






今天我们来说说在机器学习中,针对中小型数据集常用的一种用于观察模型稳定性的方法——交叉验证。
一、什么是交叉验证?
概述
交叉验证是用来观察模型的稳定性的一种方法,我们将数据划分为n份,依次使用其中一份作为测试集,其他n-1份作为训练集,多次计算模型的精确性来评估模型的平均准确程度。训练集和测试集的划分会干扰模型的结果,因此用交叉验证n次的结果求出的平均值,是对模型效果的一个更好的度量。

实质
将数据集进行多次划分,一部分做为训练集来训练模型,另一部分做为测试集,以此多次计算,最终评价模型效果。
二、为什么要用交叉验证?(适用范围)
- 交叉验证可以用于评估模型的预测性能,尤其是训练好的模型在新数据上的表现,在一定程度上减小过拟合。
- 可以从有限的数据中获取尽可能多的有效信息。
- 在数据量较少时,更方便找到适合的模型参数。
注~
交叉验证适用于中小型的数据集,数据量较大(或做深度学习)时,不推荐使用。
- 没必要
- 训练时间拉长了,时间成本高
三、实例操作
在之前的文章中,我们使用肝炎数据集进行了数据分析及建立了决策树模型:
侦探L:Pandas与机器学习实例——肝炎数据集(2)zhuanlan.zhihu.com
当时我们指定了拆分系数为0.3,也是说将7/10的数据作为训练集,剩下3/10的数据作为测试集。
最后得到模型在测试集上的准确度是0.787。
这次我们不使用拆分系数进行划分,采用交叉验证的方法进行数据集划分。
首先还是一样,回顾一下我们的数据:
将原数据集按特征和目标进行分割:
df_x=df.drop(labels='是否生还',axis=1)
df_y=df.loc[:,'是否生还']特征:

目标:

导入我们实验索要用的库:
#决策树
from sklearn import tree
#交叉验证
from sklearn.model_selection import cross_val_score实例化(这里我们用的是分类树):
clf = tree.DecisionTreeClassifier(criterion="entropy")进行交叉验证,查看结果:
cross_val_score(clf, df_x, df_y, cv=10)
从返回的结果可以看到,返回值是包含10个准确度的array。
我们还可以进一步使用mean( )来查看交叉验证后的平均情况:
cross_val_score(clf, df_x, df_y, cv=10).mean()
可以看到,10次交叉验证的结果,平均的准确度在0.82左右。
小结:
主要参数:
通过上面的例子看到,我们的交叉验证方法这里主要有四个参数:
第一个:模型评估器,决策树、回归、随机森林、支持向量机等等。
第二个:完整的数据集特征(不需划分测试集合训练集)
第三个:完整的数据集标签(不需划分测试集合训练集)
第四个:cv=10,也就是指定做十次交叉验证(把数据分成十份,每次提取一份作为测试集,剩下的九份作为训练集,如此循环十次,默认=5)
实际上还有一个常用的常数:scoring。比如指定scoring = "neg_mean_squared_error",也就是说指定使用"neg_mean_squared_error"方法进行模型评估。
(在本例中,由于我们模型使用的是分类树,因此我们的交叉验证结果返回值是十次拟合的准确度,因此不需要使用scoring参数。)
使用交叉验证与使用拆分系数的对比:
可以看到,使用交叉验证得到的模型评估结果,在某些时候还优于使用拆分系数进行单次数据划分,有时候可以得到更客观的评估结论。
当然了,无论是使用拆分系数还是交叉验证,在后续的模型调试中,我们还是依旧要进行参数调优的~
四、使用一组交叉验证进行随机森林算法和决策树算法的效果对比
#导入随机森林并进行实例化
from sklearn.ensemble import RandomForestClassifier
rfc = RandomForestClassifier(n_estimators=30)#决策树
df_clf = cross_val_score(clf, df_x, df_y, cv=10)
#随机森林
df_rfc = cross_val_score(rfc,df_x, df_y,cv=10)作出两种算法在本例中的拟合效果图:
import matplotlib.pyplot as plt
plt.plot(range(1,11),df_clf,label = "分类树")
plt.plot(range(1,11),df_rfc,label = "随机森林")
plt.rcParams['font.sans-serif']=['SimHei']
plt.legend()
plt.show()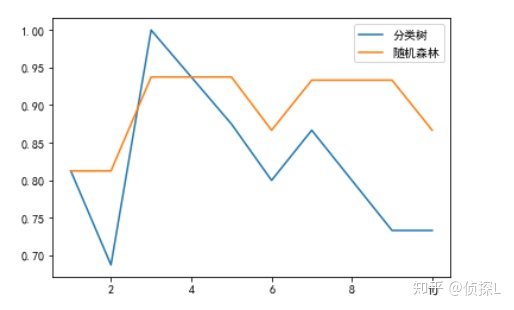
可以看到,在本次交叉验证中,随机森林算法的准确率更高一些。
df_clf_av = cross_val_score(clf, df_x, df_y, cv=10).mean()
df_rfc_av = cross_val_score(rfc,df_x, df_y,cv=10).mean()
print("本次交叉验证下决策树平均准确度:{:.2%};本次交叉验证下随机森林平均准确度{:.2%}".format(df_clf_av,df_rfc_av))
也就说是,在本例中,使用随机森林算法的效果会更好一点。
以上便是<如何在机器学习中使用交叉验证(实例)>的内容,感谢大家的细心阅读,同时欢迎感兴趣的小伙伴一起讨论、学习,想要了解更多内容的可以看我的其他文章,同时可以持续关注我的动态~















 3982
3982











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









