







第一章 模型的输入与评估
西瓜书概念很多,由过去多次反复入门经验,先选择摘取重要概念作为笔记,不纠结其他概念,实际代码中用到再深入。
机器学习关键是三步:1.构造输入 2.选择数学模型(线性回归、神经网络等) 3.评估输出并最小化误差(梯度下降),本章讨论模型如何选择输入数据和常见的评估指标
1.输入数据选择
1.留出法
留出法将数据集D分为两个互斥集合,其中一个作为训练集S,另一个作为测试集T。注意,划分数据集时要保持数据分布的一致性,以二分类任务为例,若训练集中正例与反例数量比2:3,则在测试集中两者比例也为2:3,此分法称为”分层采样“。在吴恩达机器学习课程中,有额外分出个验证集(即数据集分成3个互斥集合)的情况,验证集用于评估不同模型训练后,哪个模型更好,常见代码如下:
from sklearn import model_selection
# 划分训练集和测试集1:1
X_train,X_test, y_train,y_test = model_selection.train_test_split(X,y,test_size=0.5,random_state=0)

2.交叉验证法
交叉验证法将N个样本的数据集D分为k个大小相等的互斥集合,采用“分层采样”,每次训练使用k-1个子集作训练集,余下一个作为测试集,从而进行k次训练,结果取K次结果的均值,又称为“K折交叉验证”。(K通常取值为10)当K=N时,也称“留一法”。常见代码如下:
from sklearn import model_selection
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
# cv :10折交叉验证
# n_jobs:同时工作的cpu个数(-1代表全部)
# scoring: 打分方式,默认‘accuracy’,可选‘f1’、precision’、recall’、roc_auc’、'neg_log_loss'
accs=model_selection.cross_val_score(model, X, y=y, scoring=None,cv=10, n_jobs=1)

3.自助法
问题:留出法与交叉验证法中,由于数据集中留出一部分作测试集,会导致模型因训练样本数量不同而导致偏差,为了减小训练样本规模对模型的影响,采用自助法。
方案:自助法以自助采样(bootstrap sampling)为基础,每次随机从m个样本数据集D中放回式选出一个样本,放入训练集D’,执行m次后,样本m次采样中不被采到的概率为 lim n → + ∞ ( 1 − 1 m ) m = 1 e ≈ 0.368 \lim_{n\rightarrow+\infty}(1-\frac{1}{m})^m=\frac{1}{e}\approx 0.368 limn→+∞(1−m1)m=e1≈0.368,即D中由36.8%的数据未出现在训练集D’中,可用做测试集。常见代码如下:
import pandas as pd
#data为DataFrame对象
# df.sample(n=None, frac=None, replace=False, weights=None, random_state=None, axis=None)
# n :要抽取的行数,frac:抽取行的比例 ,frac=1.0时可以实现shuffle
# replace:是否为有放回抽样,True:有放回抽样,False:不放回抽样
# weights :字符索引或概率数组,axis=0:为行字符索引或概率数组,axis=1:为列字符索引或概率数组
# axis 选择抽取数据的行还是列,axis=0:抽取行,axis=1:抽取列
train = data.sample(frac=1.0,replace=True)
test = data.loc[data.index.difference(train.index)].copy()
2.评估指标
1.回归任务
回归中最常用“均方误差”,即 1 n ∑ i = 1 n ( F ( X i ) − y i ) 2 \frac{1}{n}\sum_{i=1}^{n}{(F(X_i) - y_i)^2} n1∑i=1n(F(Xi)−yi)2,对于数据分布D和概率密度函数p(x),则为 ∫ x ∈ D ( F ( X ) − y ) 2 p ( x ) d x \int _{x\in D} (F(X) - y)^2 p(x){\rm d}x ∫x∈D(F(X)−y)2p(x)dx
2.分类任务
多分类和二分类中最常用错误率与精度,错误率为分类错误样本占样本总数的比例,精度为分类正确样本占样本总数的比例。但分类任务中,比如医疗影像关心所有的疾病样片,有多少被正确识别,还会涉及代价倾向的问题(预测错误的后果),需要新指标。
2.1 F1指标
以二分类为例,根据真实结果与预测结果组合为分类(混淆=排列组合)矩阵如下,由此定义查准率P和查全率R


由上图可知,P与R相互矛盾,但我们期望P与R都能达到较高水平,当令P=R时的点为平衡点,称为BEP度量。但实际上用的最多的时F1度量,且当 P = R , F 1 A > F 1 B P=R ,F1_A > F1_B P=R,F1A>F1B时。有 B E P A > B E P B BEP_A > BEP_B BEPA>BEPB(令 1 F 1 = 1 2 ⋅ ( 1 P + 1 R ) \frac{1}{F_1}=\frac{1}{2}\cdot(\frac{1}{P}+\frac{1}{R}) F11=21⋅(P1+R1)可证)。

from sklearn import metrics
# model为模型对象
y_pred = model.predict(X_test)
# 常见分类指标度量
print(metrics.classification_report(y_test, y_pred))
'''
输出:precision recall f1-score support
0 0.80 0.80 0.80 5
1 0.75 0.75 0.75 4
accuracy 0.78 9
macro avg 0.78 0.78 0.78 9
weighted avg 0.78 0.78 0.78 9
'''
2.1 ROC与AUC
分类任务中的输出常为概率值,通常概率值以0.5为阈值,大于则判正例,小于则判负例,而研究阈值设置对模型的影响,会使用ROC(受试者工作特征)曲线。ROC纵轴为“真正例率TPR”,横轴为“假正例率FPR”。其中AUC为ROC曲线与坐标轴为成的面积,可以比较两个学习器的ROC曲线交叉时,哪个更优,下图中虚线为阈值=0.5的情况 ROC与AUC代码参考



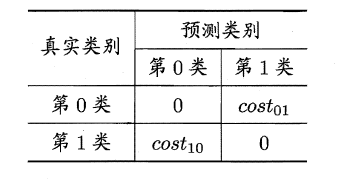
当涉及代价计算时,即对预测疾病时倾向于 不确定情况-》有疾病,而不是预测健康,付出生命代价。设代价矩阵和代价公式如下,公式中 II(…) 表示括号内条件成立,取值1

由于代价曲线横轴是取值在[0,1]之间的正例概率代价,其中p表示正例的概率,纵轴是取值为[0,1]的归一化代价
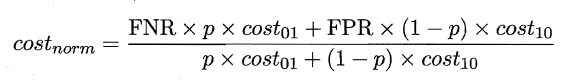
代价曲线的绘制:设ROC曲线上任一点 X i X_i Xi的坐标为(TPR,FPR) ,则可相应计算出FNR,然后在代价平面上绘制一条从(0,FPR) 到(1,FNR) 的线段 L i L_i Li,线段下的面积 S i S_i Si,表示了该条件下的期望总体代价;如此将ROC 曲线土的每个点转化为代价平面上的一条线段,然后取所有线段的下界(各线段与X轴围成的图形的交集, S 1 ⋂ S 2 ⋂ ⋯ ⋂ S n S_1\bigcap S_2\bigcap\dots\bigcap S_n S1⋂S2⋂⋯⋂Sn),围成的面积即为在所有条件下学习器的期望总体代价,如图所示:

3.比较检验(略)
当得到各个模型评估指标的结果时,不是简单的比大小(实际写代码时)选出最优模型,而是使用统计假设检验,以错误率为例,检验真实错误率有多大概率 α \alpha α 接近测试错误率,即通过测试错误率来推测泛化错误率的分布,详细参考西瓜书。
-
假设检验(二项检验、t检验)
-
交叉验证t检验
对两个学习器A和B有K折交叉验证得到测试错误率集合a和b,取对应差值,对a与b的学习性能相同做检验
-
McNemar检验(二分类问题)
-
Friedman检验与Nemenyi后续检验(以上三个只能在单组数据上检验,F检验可比较多个算法)
参考:https://github.com/Vay-keen/Machine-learning-learning-notes















 344
344











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









