






未经许可请勿转载
更多数据分析内容参看这里
一、 决策树简介
今天我们来学习一下决策树。基本上来说,根据目标字段的不同,决策树可以分为两种类型,一种是分类树,另一种是回归树。如下图所示,左侧是分类树,右侧是回归树,两者的树结构没有区别,从根节点到最后的叶节点就是我们的决策。两者的主要差别在于目标的不同,左侧是要根据输入字段判断客户是否会购买电脑,它是类别型属性,而右侧的回归树的目标字段是数值型,要根据输入字段判断房屋的成交价。决策树的输入属性既可以是类别型,也可以是数值型,其次还要提供标识字段来识别记录,当然ID字段在训练的时候实际上是不起作用的。

二、分类树基本概念(Classicfication Tree)
- 分类树算法的种类
在分类树算法中,C5.0, CART, CHAID是其中非常有名的,而又以C5.0和CART最为著名,此前有一个数据挖掘大师写过datamining中必须要掌握的十大算法中,C5.0和CART双双入选。C5.0的开发者是澳洲的数学家J.R. Quinlan,最初在他的博士论文中提出了ID-3,后来他觉得ID-3有诸多缺点,在企业实际应用中有蛮多不合的情况,因此虽然他已经取得了博士学位后,他依然将ID-3修正为C4.5,C4.5是一个里程碑,ID-3中的缺点几乎全部解决,同时他还发表了一本书《C4.5 Programs for Machine Learning, Morgan Kaufmann, 1993》。ID-3和C4.5都是开源的,但是到了C5.0,Quinlan开了一家公司专门来出售C5.0的软件,但是好消息是R语言involve了C5.0的套件,因此又变成开源的了。所有的分类树算法都是自顶向下的逻辑,逐步长大的。
2. 分类树的学习阶段
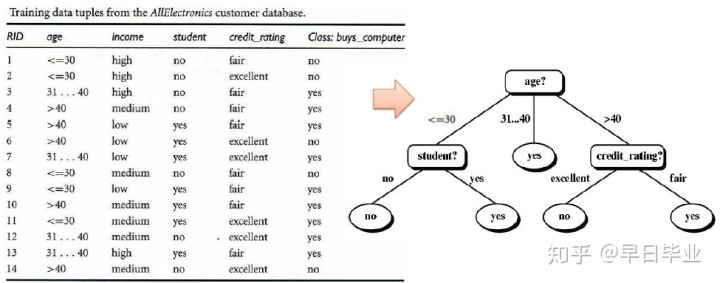
下图是分类树的学习阶段,根据训练集中输入的age,income两个输入字段来判断其信用评级credit_rating,通过分类树算法,最终会生成一棵分类树。从根节点到每一个叶节点都对应着我们不同的分类规则,比如如果年龄在31-40,收入为高,那么信用评价为优秀。

3. 分类树的测试阶段

在分类树的测试阶段,我们可以拿前面的分类树(分类规则)来对另外一组的测试数据来做测试。在我们的Test data中,已经有credit_rating字段,这是标准答案,但是在测试过程中并不会用到这一个字段,这个字段是用来构造的混淆矩阵,最终计算命中率,捕捉率和F指标,用以判断分类树是否可以用在真实环境新的数据中。
4. 分类树的模型训练结果
分类树算法就是要根据我们喂入的测试数据,生成一棵最为精简的分类树。
5. 分类树的归纳学习原理
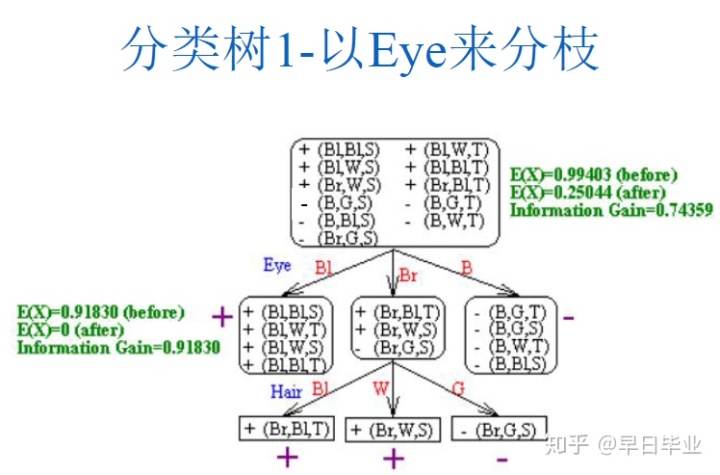
最初,所有的的训练集数据都在根节点,然后我们会递归地选择一个属性来对训练集进行分割,属性选择的标准是要使得识别的正确率最高。具体我们来看下面的例子,根据眼睛的颜色,发色和身高来判断是否是东方人。

第一种我们选择以眼睛的颜色来分支,在树根节点是没有任何信息的,因此要判断是否东方人,我们只能根据概率大致猜测一下,猜错的概率是5/11。在根据Eye 分支后,由于black颜色的都是东方人,blue颜色的都不是东方人,因此这两个分支不会犯错,而brown颜色的眼睛我们同样只能根据概率猜测都为东方人,有一个案例会犯错,因此总的错误率降低至1/11。
第二次我们首先用身高来分枝,由于无论高矮我们都没有办法确定其是否是东方人,因此在知道了身高信息后,总的犯错概率仍然是5/11。因此第一次我们应该选择眼睛的颜色来分枝。事实上,我们选择切割的标准是希望大多数的数据能够被划分到单一类目中去(比如都是东方人,或者都是西方人)。
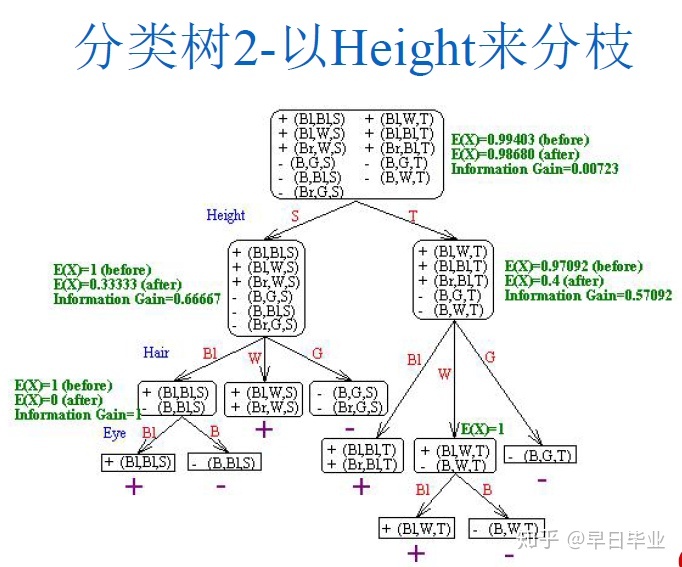
还有一个要注意的是,要避免分类树过度拟合,也就是要做砍树处理。比如分类树1-以eye来分枝中,如果继续对中间节点以Hair来分枝,就会产生5条规则,在训练集中虽然会提升正确率,但用在真实环境中错误率会比较高,原因训练集中数据较少的类目代表性不足,比如你在做问卷的时候问了一个人回答yes,正确率100%,但是如果第二个人回答no,正确率立刻下降到50%。所以我们并非追求训练集100%正确,特别是训练集中的数据并非那么干净的时候,不可能100%正确。
三、 ID3分类树的属性选择
前面我们已经提到属性的选择和砍树的处理,但是这只是概念上的,真正在应用的时候我们需要把概念量化到具体的值。在实际的算法中,属性的选择并非采用简单的正确率,而是会采用相对复杂一些的拟合指标。ID3中使用的是Information Gain,C4.5/C5.0使用Gain Ratio, CART使用Gini Index ,CHAID使用CHi-Square Statistic。我们先来看ID3.
我们仍然使用前面使用过的数据集,目标字段是是否会购买电脑,输入字段是age,income,student,和credit_rating

在进行ID3的字段选择之前,先大概看看数据是平均分布还是偏某一类,平均分布的数据就不太好。我们用熵的概念,I(s1,s2)=I(9,5)= -9/14log_2(9/14)-5/14log_2(9/14)=0.940。基本上分两类的问题中,entropy的值会在0-1之间,越靠近1数据越平均分布。
具体选择哪个字段,我们需要计算每个属性的熵值。首先我们来计算age的entropy,由于age分类<30, 31...40和>40三类,我们需要三小类各自的值,最后加权计算后得到0.694计算过程如下。

这意味着由于知道了年龄信息,我们的熵值从0.94下降到了0.694,这就是信息增益的概念,也是age这个字段重要性的象征,越是重要下降的幅度越大,此处,Gain(age)=I(S1,S2)-E(age)=0.246。类似的,我们可以计算出Gain(income)=0.029,Gain(student)=0.151, gain(creditrating)=0.048。由于age字段的增益最大,因此选择它作为分支的属性,我们创建一个命名为age的节点,并根据不同的age分类生成三个分枝,由于31...40岁所有人都被分为yes,因此这一个分枝就是一个叶节点,用yes 来标识。而另外两个分枝还需要根据其余的属性继续分,至于选择哪个属性,其实本例子中也十分明显,由于student字段可以完全分开左边的分枝,credit_rating可以完全分开右边的分枝,因此这两个字段再下一步会被选中。

最终的分类树如下:

ID3算法的缺点有:适用的场景偏好属性有众多的分类;所有的属性必须是分类字段,如果是连续型数值字段,比如离散化处理;不能处理空值;不砍树。
四、 C4.5分类树的属性选择
为了解决上述问题,C4.5做了各种改进。首先在原有的信息增益的基础上,发展了获利比例的概念。如下所示,Gain Ration是在Information Gain生成后,再去除以一个分支度。这能够解决ID3偏好分类过多的缺点,当分类过多的时候,分支度大,最终降低了Gain Ratio。这边的分支度也借用了熵的公式,而不是简单的分三类就是3。

C4.5也能处理数值型连续变量,首先它会将所有的数值从小到大排列,然后在每两个数值的中点去做切割,把原有的树分为两枝,并计算Gain Ratio。最后会挑选所有Gain Ration中最大的那一个对应分割点作为分枝的依据。
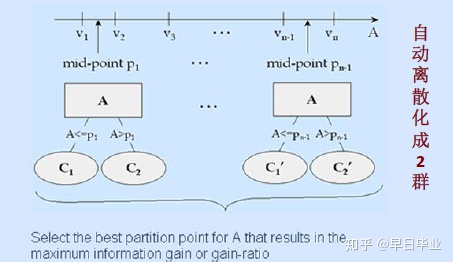
C4.5支持砍树(Tree Pruning)处理,避免过度拟合问题。砍树一般有两种做法,修剪法(Prunning Technique)和盆栽法(Bonsai Technique),修剪法是一种自底向上的做法,C5.0和CART采用这种方法,首先让树长满,然后去做砍枝处理盆栽法是CHAID在用,如下图。

C4.5的砍树方法,是通过比较树展开和合上两种情况下的预期错误率,去决定是否要砍枝处理,由于公式比较复杂,此处不再展开。
五、 分类树算法——CART(Classification and Regression Tree)
分类回归树 - CART (Classification and Regression Tree)算法是一种建构二元(Binary)分类回归树的算法,它在1984年由Breiman, Friedman, Olshen与Stone四人所提出。CART把分类树和回归树合并在一个算法里,今天我们主要看里面的分类树部分。
CART的基本原理和ID3、C4.5差不多,但许多方面有区别,首先筛选属性时指标不同,CART算法中,Attribute Selection是以Gini Index作为评估指标,Tree Pruning是以Bottom-Up的方式配合验证数据集(Validation Dataset)来进行。CART算法一个主要特征是,不管是数值字段还是分类字段,它永远分两枝,避免了分枝过多的问题,这也和ID3等不一样。

上图中,我们要根据四个输入属性来判断便利店的开设能否盈利,分类树的属性选择指标采用Gini指数,
选择道路距离作为分枝属性,由于CART总是构建二元树,因此对应不同的距离,可以有如下选项, 由于第二种分割方式Gini值为0.357,下降的幅度最大,所以道路距离会在次切割。
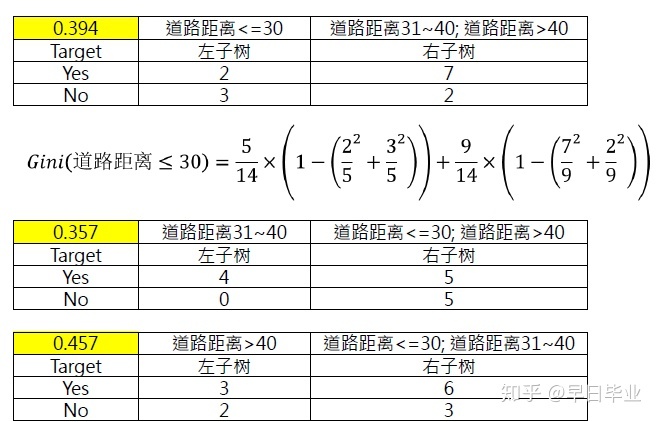
类似的,可以分别计算出人口密度,区域和是否有地铁站的Gini值。最终啥选出道路距离31-40的来做树的切割,生成第一层次的分类树。
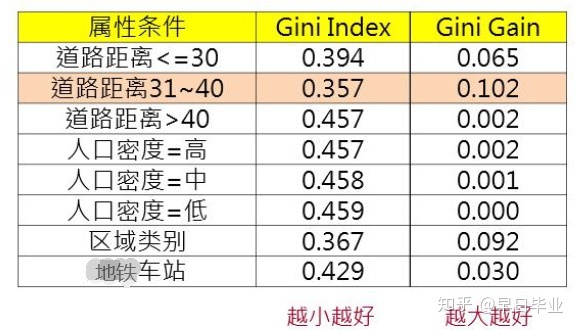
按照上面的方式,不断向下切割,可以生成最完整的分类树。
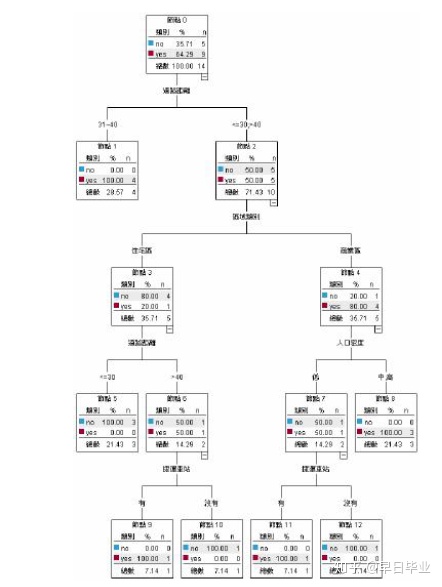
那是否分类树需要生成的这么完整,下面就涉及到CART的砍树处理。CART的砍树是根据验证数据来决定是否砍树。CART会将训练集分为两部分,一部分是真正的训练集,另一部分是验证数据集。下图中,框内的是训练集生成的分类树,框外的则是验证数据,我们要判断的就是树节点合起来和展开时的错误对比,如果合起来错误率更低,则需要砍掉下边的节点。
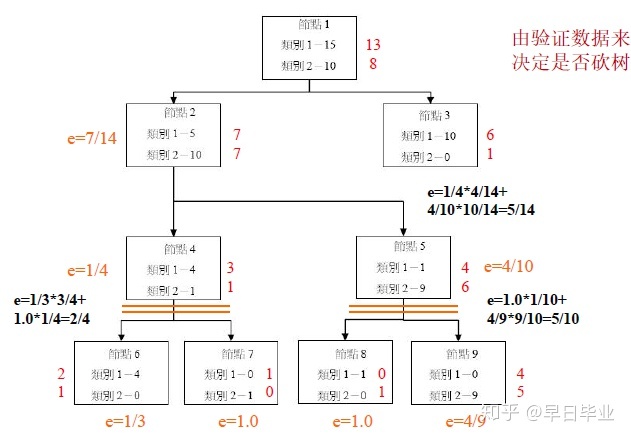
以最左下角的非叶节点(节点4)为例,由于类别1有四个数据,类别2有一个数据,因此节点4会判断数据为类别1,对验证数据来说,3笔是类别1,1笔是类别2,因此错误的比率e=1/4。节点4展开为节点6和节点7时,节点6判断为类别1,节点2判断为类别2,此时对于验证数据集而言,节点6的错误率为1/3,节点7的错误率为100%,加权错误率为
CART在处理连续型数值变量时,处理方法和C4.5一样的,不再赘述。
五、 CHAID分类树算法的属性选择
CHAID 在筛选属性的时候用的是卡方统计量,这就要求输入字段和目标字段均未类别变量。如果有数值字段,必须要做离散化处理。 卡方值越大(P value越小),代表此条件与目标字段的关系越密切,越是重要的条件字段。CHAID根据p Value决定树是否继续往下长,属于Top-Down的砍树方法。
六、 如何运用分类树进行预测
一般来说有直接和间接两种方式来进行预测,直接方法是在树上找到一条路径,从root到leaf,就能进行预测,比如下面从age到no的路径。间接方式则是通过树生成一条条规则,根据规则去做预测。

虽然看起来路径和规则并没有区别,但是分类规则可以做得更为进准,它可以被优化。比如下面的分类树可以生成四条规则:
•Watch the game and home team wins and out with friends then bear
• Watch the game and home team wins and sitting at home then milk
• Watch the game and home team loses and out with friend then bear
• Watch the game and home team loses and sitting at home then diet soda
我们发现规则1和规则3都是喝啤酒,而不管比赛输赢,因此我们可以优化这两条规则为一条
• Watch the game and out with friends then bear
但反过来,分类规则能否画成分类树,这个其实十分困难。所以分类规则是比较自由的,分类树则比较受到限制,所以人们研究如何产生更有的分类规则,使得预测的结果更佳。

















 1210
1210











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









