






背景:
近期在工作中遇到一个比较疑难的问题, 写文章纪念下。
一线工程师邮件:“同一个语句,SYS用户执行和表的属主执行获得了不同的执行计划,请帮忙分析, 目前通过SQlProfile绑定较好的执行计划。但是客户还是要找到出现不同执行计划的原因”
基本情况:
SQL:
SELECT BILL_ID, ACCT_ID, STATE,TO_CHAR(STATE_DATE, 'YYYYMMDDHH24MISS') FROM bill_201902 where created_date> (select created_date from bill_201902 where bill_id = :1 ) - 1/24/12 andbill_id <=:2 AND STATE IN ('40C', '40F') AND MOD(ACCT_ID, :MOD_ID)=:REST_IDORDER BY BILL_ID ASC;
执行计划:
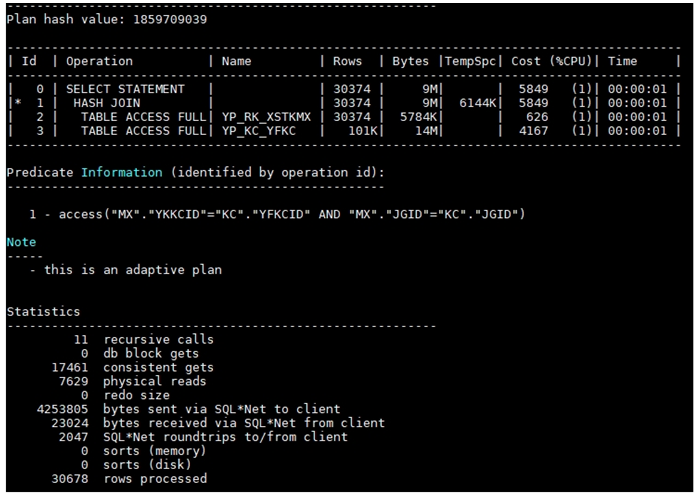
属主下执行计划:
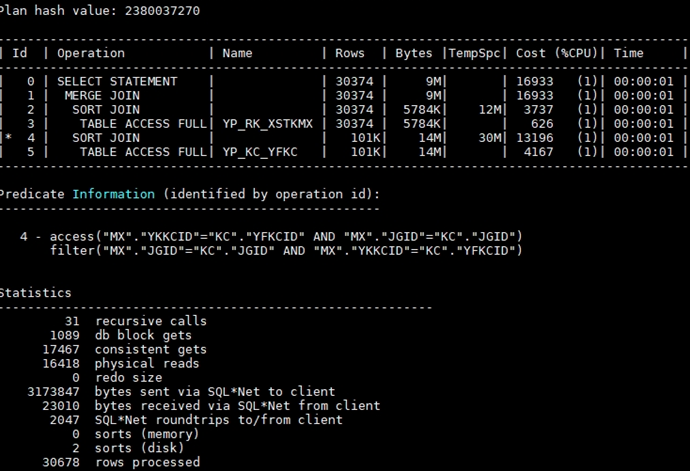
问题排查
摸清楚大致情况发现 12C新特性“this is an adaptive plan”.
Adaptive Plans允许后期改变执行计划,比如由于统计信息不及时更新或者where条件过于复杂导致估算的rows差异很大。因此在后期允许适当调整执行计划,作为辅助方案。
官方文档
:http://docs.oracle.com/database/121/TGSQL/tgsql_optcncpt.htm#TGSQL221
跟一线工程师。确认是不是SYS用户用了这个特性, 属主用户是否也能用这个特性。一线工程师否定,都能用这个特性。 而且属主用户执行计划很稳定,都是排序合并连接。
是否是真实rows和估算的rows差异太大,才会后期执行的适合用这个特性适当修正执行计划?那把问题集中到统计信息中。
一线工程师反馈说统计信息,应该没有问题,毕竟刚收集过统计信息。而且通过两个执行计划发现,起码两边的rows相等的。下一步就要排查在两边基于相同的统计信息,为什么一个选择hash 关联 ,一个选择排序合并连接。
SYS 的执行计划:
HASH 关联
Outertable: YP_RK_XSTKMX Alias: MX
resc: 625.943187 card 31127.000000 bytes: deg: 1 resp: 625.943187
Innertable: YP_KC_YFKC Alias: KC
resc: 4167.379012 card: 103254.000000 bytes: deg: 1 resp: 4167.379012
using dmeth: 2 #groups: 1
Cost per ptn: 1072.258737 #ptns: 1
hash_area: 256 (max=262144) buildfrag:787 probefrag: 1979 ppasses: 1
Hash join: Resc: 5865.580937 Resp: 5865.580937 [multiMatchCost=0.000000]
排序合并连接
Outer table: YP_RK_XSTKMX Alias: MX
resc: 625.943187 card 31127.000000 bytes: deg: 1 resp: 625.943187
Inner table: YP_KC_YFKC Alias: KC
resc: 4167.379012 card: 103254.000000 bytes: deg: 1 resp: 4167.379012
using dmeth: 2 #groups: 1
SORT ressource Sort statistics
Sort width: 6142 Area size: 1048576 Max Area size: 1073741824
Degree: 1
Blocks to Sort: 858 Row size: 225 Total Rows: 31127
Initial runs: 2 Merge passes: 1 IO Cost / pass: 466
Total IO sort cost: 1324.000000 Total CPU sort cost: 71668204
Total Temp space used: 13100000
SORT ressource Sort statistics
Sort width: 6142 Area size: 1048576 Max Area size: 1073741824
Degree: 1
Blocks to Sort: 2150 Row size: 170 Total Rows: 103254
Initial runs: 2 Merge passes: 1 IO Cost / pass: 1166
Total IO sort cost: 3316.000000 Total CPU sort cost: 160036771
Total Temp space used: 32547000
SM join: Resc: 9441.148261 Resp: 9441.148261 [multiMatchCost=0.000000]
SMJoinSM cost: 9441.148261
resc: 9441.148261 resc_io: 9426.000000resc_cpu: 448492175
Best:: JoinMethod: Hash
Cost: 5865.580937 Degree: 1 Resp: 5865.580937 Card:31127.000000 Bytes:
属主的执行计划:
HASH关联
Outertable: YP_RK_XSTKMX Alias: MX
resc: 625.943187 card 31127.000000 bytes: deg: 1 resp: 625.943187
Inner table: YP_KC_YFKC Alias: KC
resc: 4167.379012 card: 103254.000000 bytes: deg: 1 resp: 4167.379012
using dmeth: 2 #groups: 1
Cost per ptn: 15724.811560 #ptns: 1
hash_area: 16 (max=16) buildfrag: 787 probefrag: 1979 ppasses: 1
Hash join: Resc: 20518.133760 Resp: 20518.133760 [multiMatchCost=0.000000]
排序合并连接
Outer table: YP_RK_XSTKMX Alias: MX
resc: 625.943187 card 31127.000000 bytes: deg: 1 resp: 625.943187
Inner table: YP_KC_YFKC Alias: KC
resc: 4167.379012 card: 103254.000000 bytes: deg: 1 resp: 4167.379012
using dmeth: 2 #groups: 1
SORT ressource Sort statistics
Sort width: 3 Area size: 36864 Max Area size: 36864
Degree: 1
Blocks to Sort: 858 Row size: 225 Total Rows: 31127
Initial runs: 191 Merge passes: 5 IO Cost / pass: 466
Total IO sort cost: 3188.000000 Total CPU sort cost: 113926420
Total Temp space used: 13100000
SORT ressource Sort statistics
Sort width: 3 Area size: 36864 Max Area size: 36864
Degree: 1
Blocks to Sort: 2150 Row size: 170 Total Rows: 103254
Initial runs: 479 Merge passes: 6 IO Cost / pass: 1166
Total IO sort cost: 9146.000000 Total CPU sort cost: 292401521
Total Temp space used: 32547000
SM join: Resc: 17141.046323 Resp: 17141.046323 [multiMatchCost=0.000000]
Best:: JoinMethod: SortMerge
Cost: 17141.046323 Degree: 1 Resp: 17141.046323 Card:31127.000000 Bytes:
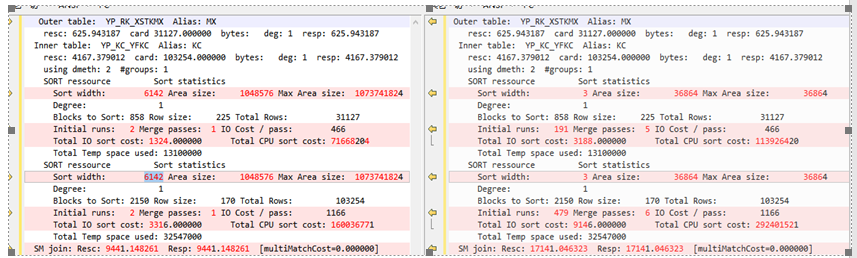
上述信息通过10053得到,数据信息比较细,为了方便阅读,我整理了表格
我们明显的看到
SYS | 属主 | |
HASH 关联 | COST:5865(最佳) | COST:20518 |
排序合并连接 | COST:9441 | COST: 17141(最佳) |
SYS用户下无论是hash关联还是排序合并连接成本明显较小,而hash 关联成本最小,因此选择了hash关联。
属主用户下同样的道理,选择了成本最小的关联方式,即排序合并连接。再来看实际上效率最高的关联方式也就是HASH 关联时候 SYS 中:
hash_area: 256 (max=262144)
而在属主用户中 :hash_area: 16(max=16),
具体的对比:

我们也知道无论是HASH 关联还是排序合并连接都是发生在PGA中,是不是SYS用户中单个Session分配的PGA要大呢?一线工程师也是大牛,迅速响应反馈到说SYS是本地登陆,而属主用户是远程登陆上的。立刻把SYS用户换成远程登陆,发现和属主用户远程登陆时候出现的情况一致。(和大牛合作就是舒服),最后排查到PGA的管理方式上面。找到问题的根源就好办了。
总结:
从问题反馈到弄清楚基本情况我们的排查经历了,
从执行计划角度出发,先定位到12C新特性,分析后排除。
随即排查到统计信息中,发现都是基于相同的统计信息,因此统计信息的原因排除,但牵引出排除的方向(基于相同的信息,为何执行计划不同,也就是CBO的行为结果为何不同)
接着10053信息中排查CBO的行为,排查到两边使用的内存空间不同,再次牵引出PGA的管理方式才是根本原因。















 847
847











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









