






©PaperWeekly 原创 · 作者|苏剑林
单位|追一科技
研究方向|NLP、神经网络
GELU,全称为 Gaussian Error Linear Unit,也算是 RELU 的变种,是一个非初等函数形式的激活函数。它由论文 Gaussian Error Linear Units (GELUs) [1] 提出,后来被用到了 GPT 中,再后来被用在了 BERT 中,再再后来的不少预训练语言模型也跟着用到了它。
随着 BERT 等预训练语言模型的兴起,GELU 也跟着水涨船高,莫名其妙地就成了热门的激活函数了。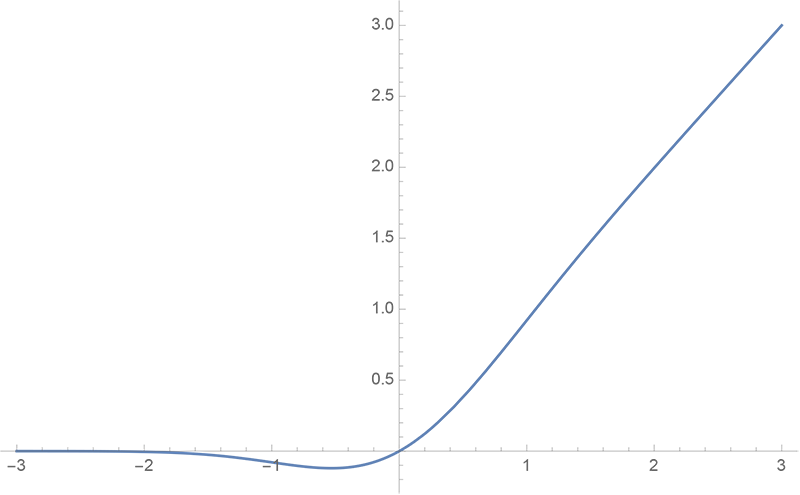
 GELU函数
GELU 函数的形式为:
GELU函数
GELU 函数的形式为:
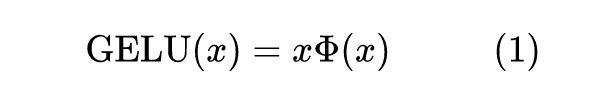
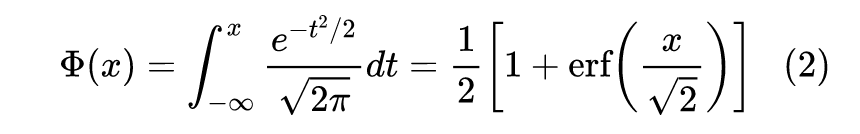
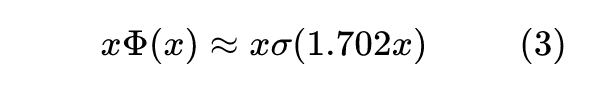 以及:
以及:
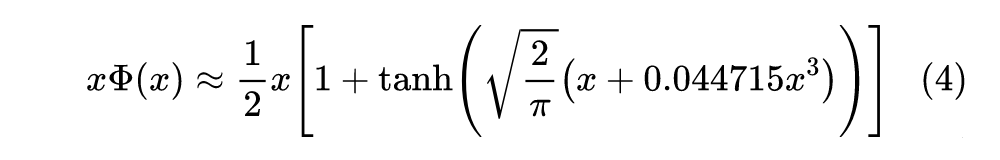
 用啥近似
显然,要找 GELU 的近似形式,就相当于找 近似,这也等价于找 的近似。
用啥近似
显然,要找 GELU 的近似形式,就相当于找 近似,这也等价于找 的近似。
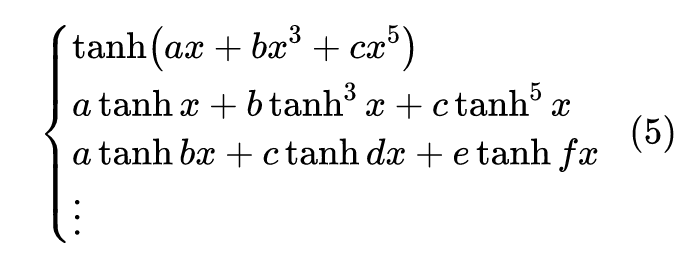
 怎样近似
有了待拟合的形式之外,下面要考虑的就是怎么拟合、以什么标准的问题了,说白了,就是想个办法求出各项系数来。一般来说,有两种思路:局部拟合和全局拟合。
怎样近似
有了待拟合的形式之外,下面要考虑的就是怎么拟合、以什么标准的问题了,说白了,就是想个办法求出各项系数来。一般来说,有两种思路:局部拟合和全局拟合。
3.1 局部拟合
局部拟合基于泰勒展开,比如考虑近似形式 ,我们在 x=0 处展开,得到: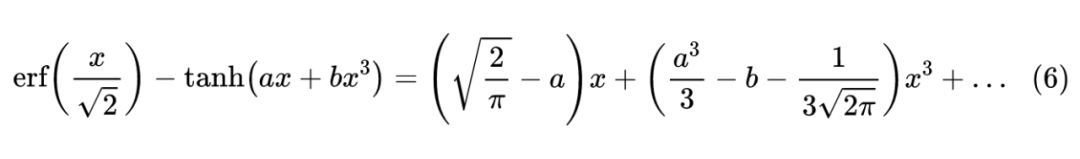
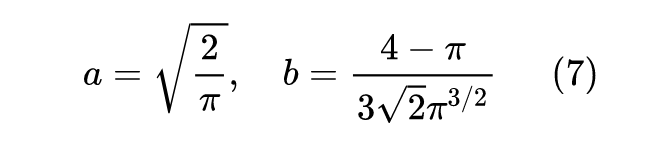
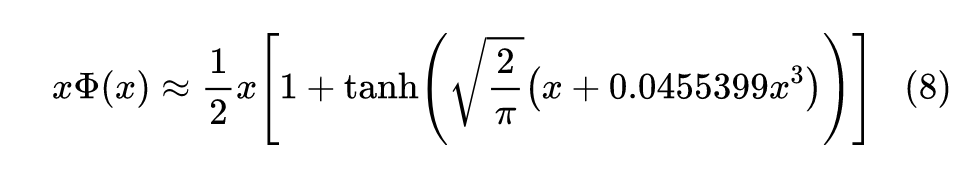
式(8)已经跟式(4)很接近了,但是第二个系数还是差了点。这是因为(8)纯粹是局部近似的结果,顾名思义,局部近似在局部会很精确,比如上面的推导是基于 x=0 处的泰勒展开,因此在 x=0 附近会比较精确,但是离 0 远一点时误差就会更大。因此,我们还需要考虑全局误差。
比较容易想到的全局误差是积分形式的,比如用 去逼近 f(x) 时,我们去算:
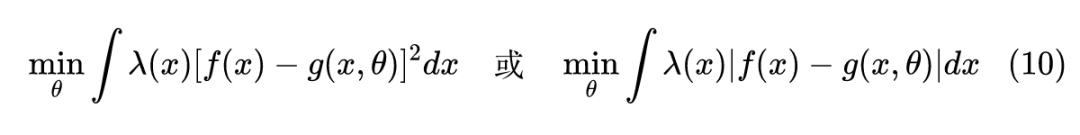
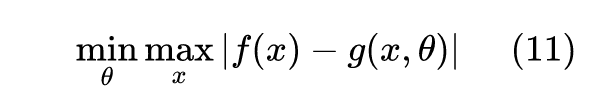
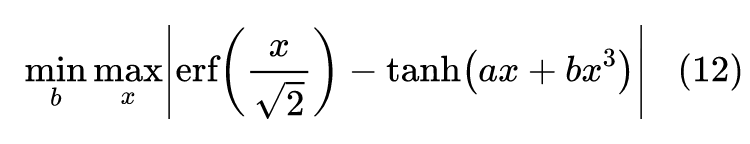
用 scipy 可以轻松完成求解:
import numpy 最后得到 b=0.035677337314877385,对应的形式就是:
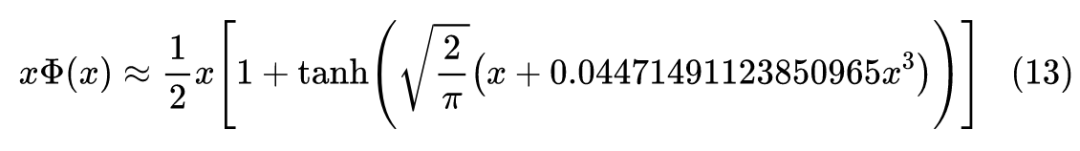
最后几位有效数字可能有误差,但前面部分已经跟式(4)完美契合了。补充说明下,式(4)提出自论文 Approximations to the Cumulative Normal Function and its Inverse for Use on a Pocket Calculator [2] ,已经是 40 多年前的结果了。
至于第一个近似,则来自论文 A logistic approximation to the cumulative normal distribution [3] ,它是直接用 全局逼近 的结果,即: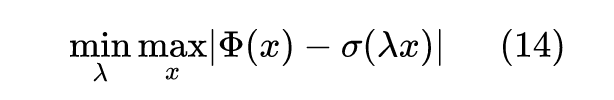


参考链接
[1] https://arxiv.org/abs/1606.08415 [2] https://www.jstor.org/stable/2346872 [3] https://core.ac.uk/download/pdf/41787448.pdf
点击以下标题查看更多往期内容:
变分推断(Variational Inference)最新进展简述
变分自编码器VAE:原来是这么一回事
图神经网络三剑客:GCN、GAT与GraphSAGE
如何快速理解马尔科夫链蒙特卡洛法?
深度学习预训练模型可解释性概览
ICLR 2020:从去噪自编码器到生成模型

#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

















 809
809











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









