





在上一期的内容中我们曾经提到,Cache的速度惊人但是容量很小,不知道大家有没有想过这样的几个问题:
1. 存储系统中的每个数据都可以被Cache缓存吗? 2. 处理器的存储空间那么大,但是Cache容量那么小,是怎么做到高速缓存数据的? 3. 再深入一点,在多处理器系统中,每个处理器都有自己的L1甚至L2缓存(多处理器系统一般都会共享最后一级缓存),但是都对应一套Main Memory,同一组数据可能同时在不同处理器的Cache和Main Memory都有一组备份,这些备份之间是怎么做到同步和更新的? 换句话来说就是,怎么保证多处理器中的任意一个CPU拿到的数据是最新的正确的? 想要解决第一个问题,我们需要了解一个概念:Memory Type。所谓Memory Type可以用来描述虚拟或者物理内存中某段区间的特点和属性。当处理器对某段内存区间进行读写操作(load/store),根据Memory Type的不同,caching和ordering的行为也会随之不同。为了避免翻译带来的歧义,关键名词我都用了英文。其中的caching可以理解为存储系统是怎么样进行数据缓存的,ordering或者说memory ordering可以理解为处理器通过System BUS向System Memory发送reads(loads) /writes(store) 指令的顺序。 Memory Ordering对于处理器存储系统是一个很重要的概念,这里面涉及到了处理器的乱序执行(out of order)和内存屏障等概念。一般把程序里面指令的顺序称为program ordering,较老的CPU的memory ordering(此处认为是指令访问system bus的顺序对于load是执行环节,store是retirement环节)如pentium,486都是program ordering。但是pentium 4开始,为了提高CPU的执行效率,乱序执行和指令/数据并行技术被引入,这种情况下的memory ordering会和program ordering不同,业界管这种不同也叫做Reordering。为了保证这种Reordering并不影响执行结果和程序代码之间的因果性,X86架构提供了内存屏障指令让程序员使用,在代码中显式的规定某些操作的执行顺序是不可以被打乱的。很复杂是吧,一句两句的说不清,这一期我们暂且跳过,在后面的内容中会专门开一个问题谈Memory Ordering和内存屏障。我们说回Memory Type,Intel 64&IA-32 架构一共定义了五种Memory Type,如下:

Strong Uncacheable(UC) : 对于UC的内存读写操作都不会写到cache里,不会被reordering。这种类型的内存适用于memory-mapped I/O device,比如说集成显卡。对于被memory-mapped I/O device使用的内存,由于会被CPU和I/O device同时访问,那么CPU的cache操作就会导致一致性的问题。reordering也会导致I/O device读到没有被及时更新的数据,比如说I/O device把这些内存作为一些控制用的寄存器使用。对于普通用途的内存,UC会导致性能的急剧下降。
Uncacheable (UC-): 和UC类型一样,除了UC- memory type可以通过设置MTRRs被改写为WC memory type。MTRRs全称是MEMORY TYPE RANGE REGISTERS,从字面意思大家也可以看出来这组寄存器是干啥的。
Write Combining (WC): WC内存不会被cache, bus coherency protcoal不会保证WC内存的读写。对于WC类型的写操作,可能会被延迟,数据被combined in write combining buffer, 这样可以减少总线上的访存操作。举例来说,对于四个word的连续内存地址write操作会被合并成一笔单独的qualword write操作,这样只会产生一笔内存访问操作而非四笔。大家还记得上一期提过的write combining buffer吗,对,它就是用来把这些可以合并的write操作暂时hold住的。
Write-through (WT) :从WT内存中read是可缓存的,发生cache miss的时候分配cache line。从WT内存读取可能是推测性的。所有对WT memory的写操作都会更新main memory,在缓存中hit的写操作会更新cache line,在缓存中miss的写操作不会为其分配cache line。
Write-back(WB):Read操作和WT一样,但是write操作只会更新cache中的内存,不会同步更新到主存中。主存中的数据只会在cache line被替换或者显示clean操作时更新。WB类型提供了最佳的读写性能。
Write protected(WP): 读操作和WT/WB没有什么区别,读会被cache. 写不一样,写WP类型memory不会更新cache,而是直接更新main memory。发生cache hit的写操作并不会更新cache,却会让该行cache line 失效。WP memory对于shadowed-ROM memory 十分有用,因为对于此类memeory region更新必须对读取阴影位置的所有设备立即可见。 那我们现在来回答第一个问题:存储系统中的每个数据都可以被Cache缓存吗?答案很明显了,不一定,看memory type。 现在我们来回答第二个问题,处理器的存储空间那么大,但是Cache容量那么小,是怎么做到告诉缓存数据的?回答这个问题需要我们先了解Cache的组织结构,以及Cache和物理内存的映射关系。 尽管不同处理器Cache的实现细节各有不同,但是大致的框架和原理还是相通的。L1和L2 Cache一般会被设计成n-way set-associative cache(多路组相连缓存),如下所示就是一个多路组相连缓存的逻辑结构图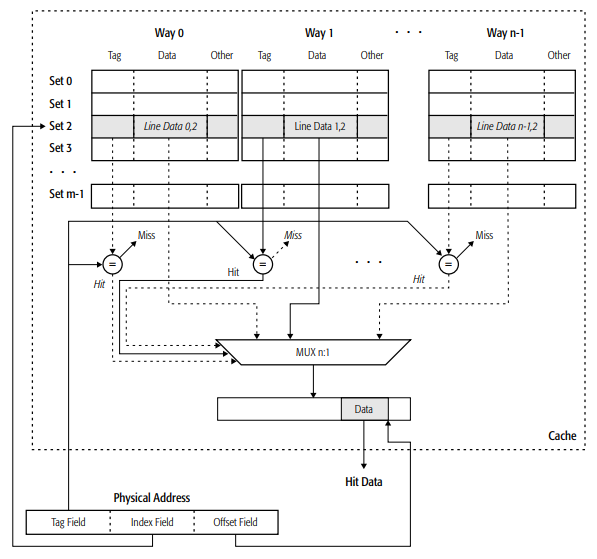 上期内容中我们曾经讲过,Cache的最小单位是Cache Line,整个cache就是由cache line组成的array构成的。从上图中我们可以看到,每条Cache Line又由三部分构成:cache-data line(a fixed-size copy of a memory block),tag和other information。
cache line array中的行被称为sets(组),列被称为ways(路)。在一个n-way set-associative caceh(多路组相连缓存)中,每个set(组)都是n个cache line的集合。举例来说,一个四路组相连缓存中,每个组里面都4条cache line,其中的每一条cache line都对应一路。
上期内容中我们曾经讲过,Cache的最小单位是Cache Line,整个cache就是由cache line组成的array构成的。从上图中我们可以看到,每条Cache Line又由三部分构成:cache-data line(a fixed-size copy of a memory block),tag和other information。
cache line array中的行被称为sets(组),列被称为ways(路)。在一个n-way set-associative caceh(多路组相连缓存)中,每个set(组)都是n个cache line的集合。举例来说,一个四路组相连缓存中,每个组里面都4条cache line,其中的每一条cache line都对应一路。
可以在程序或指令中使用数据的物理地址来访问cache。要知道,x86中每个地址对应一个字节的数据。为了访问Cache line中的某个字节数据,需要用物理地址去选择set/way/byte。具体的选择策略如下,首先把物理地址划分为下述三个部分:
Index----用来选择set Tag-----从set中选择特定的cache lineoffset----在cache line中选择特定的byte
就拿上图简单举例来说,物理地址中index field中为2,那么就选择cache中的set 2,然后set2,也就是第三行,又有n个cache line,每个cache line对应一个way,之所以能它们都属于set2又各自对应一个way,是因为他们的index都相同(为2),但是tag field都各不相同。通过物理地址的index选到set2后,在拿物理地址中的tag field中内容跟set 2中每个cache line的tag做比对,对比一圈后找到一个对应的,那么该物理地址对应那个字节的数据就存在于这个cache line中,然后通过物理地址的offset fiel再继续从这行cache line中选择对应的那个字节的数据,此时就发生了cache hit。如果透过index找不到对应的set,或者透过tag在set中找不到对应的cache line,就可以说发生了cache miss。 对于Read操作来说上面的过程已经足够,但是对于Write操作,除了上述过程外,还需要稍微复杂一点。记不记得cache还有一个部分是放other information的,在other information中有一个dirty bit,这个bit用来表示这行cache line内的数据已经被CPU改写过了但是还没有同步到Main Memory里,这就涉及到了Cache的两种写策略或者更新策略。 第一种最好理解,我们称之为写直通(write through): 当CPU执行store指令并在cache命中时,我们更新cache中的数据并且更新主存中的数据。cache和主存的数据始终保持一致。这个策略虽然保证了Cache与主存内数据的一致性,但是只要执行store或者说进行write操作,就会引发内存数据更新和cache line替换,效率比较低。 于是第二种策略应运而生,我们称之为写回(write back):当CPU执行store指令并在cache命中时,我们只更新cache中的数据。并且每个cache line中会有一个bit位记录数据是否被修改过,就是我们上面说过的dirty bit。我们会将dirty bit置位。主存中的数据只会在cache line被替换或者显示clean操作时更新。因此,主存中的数据可能是未修改的数据,而修改的数据躺在cache line中。 大家不觉得write through和write back很眼熟吗?是的,这两种更新策略分别对应文章一开始讲过的两种Memory Type。两种Memory Type的Load操作过程都是类似的,但是对于Store操作,WT 类型的memory region使用write through更新策略,WB类型的memory region使用write back更新策略。 了解了上面的背景知识以后,可能有的读者还是有问题:我们可以通过某个字节数据的物理地址里的index和tag去选中cache中某行cache line,但是内存中那么多数据,比如存在超级多index和tag一模一样的物理地址,他们都对应同一行cache line,这不有冲突了吗? 这样想法非常正常一点毛病也没有,确实存在这种情况。但是这样影响Cache去缓存CPU需要用到的数据吗?不影响啊,虽然存在这么多index/tag一模一样的物理地址,但是CPU经常用的往往只会是这其中的极个别地址中的数据,我们只需要把这极个别经常用到的数据以及它临近的数据放进cache缓存就可以大大提高CPU的执行效率了。这里是有理论支持的,叫做局部性原理。 时间局部性:在最近的未来要用到的信息,很可能是现在正在使用的信息;空间局部性:在最近的未来要用到的信息,很可能与现在正在使用的信息在存储空间上是邻近的。
CPU刚上电的时候,Cache里面数据都是无效的,不论访问哪个地址都必然发生cache miss,当cache被填满,里面的数据是CPU使用过的,那在后期CPU根据局部性原理可能会再次使用。即使CPU经常使用的数据发生变化了,那就再次cache miss,重新填满新数据,再次使用局部性原理进行数据缓存。起码两次cache miss之间的CPU数据读写效率是十分高的。
篇幅所限,第三个问题我们放在下一期内容讲。受限于作者水平,文章中必然存在疏漏和错误,如果读者中有高人发现,烦请直接留言或者发邮件到liwenlu_buaa@163.com指导或交流~
本期的内容结束了,我们下期再见~
时间局部性:在最近的未来要用到的信息,很可能是现在正在使用的信息;空间局部性:在最近的未来要用到的信息,很可能与现在正在使用的信息在存储空间上是邻近的。
CPU刚上电的时候,Cache里面数据都是无效的,不论访问哪个地址都必然发生cache miss,当cache被填满,里面的数据是CPU使用过的,那在后期CPU根据局部性原理可能会再次使用。即使CPU经常使用的数据发生变化了,那就再次cache miss,重新填满新数据,再次使用局部性原理进行数据缓存。起码两次cache miss之间的CPU数据读写效率是十分高的。
篇幅所限,第三个问题我们放在下一期内容讲。受限于作者水平,文章中必然存在疏漏和错误,如果读者中有高人发现,烦请直接留言或者发邮件到liwenlu_buaa@163.com指导或交流~
本期的内容结束了,我们下期再见~



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









