





几种常见SQL分页方式效率比较几种常见SQL分页方式效率比较
1.创建测试环境,(插入100万条数据大概耗时5分钟)。
create database DBTest
use DBTest
--创建测试表
create table pagetest
(
id int identity(1,1) not null,
col01 int null,
col02 nvarchar(50) null,
col03 datetime null
)
--1万记录集
declare @i int
set @i=0
while(@i<10000)
begin
insert into pagetest select cast(floor(rand()*10000) as int),left(newid(),10),getdate()
set @i=@i+1
end
2.几种典型的分页sql,下面例子是每页50条,198*50=9900,取第199页数据。

--写法1,not in/top
select top 50 * from pagetest
where id not in (select top 9900 id from pagetest order by id)
order by id
--写法2,not exists
select top 50 * from pagetest
where not exists
(select 1 from (select top 9900 id from pagetest order by id)a where a.id=pagetest.id)
order by id
--写法3,max/top
select top 50 * from pagetest
where id>(select max(id) from (select top 9900 id from pagetest order by id)a)
order by id
--写法4,row_number()
select top 50 * from
(select row_number()over(order by id)rownumber,* from pagetest)a
where rownumber>9900
select * from
(select row_number()over(order by id)rownumber,* from pagetest)a
where rownumber>9900 and rownumber<9951
select * from
(select row_number()over(order by id)rownumber,* from pagetest)a
where rownumber between 9901 and 9950
--写法5,在csdn上一帖子看到的,row_number() 变体,不基于已有字段产生记录序号,先按条件筛选以及排好序,再在结果集上给一常量列用于产生记录序号
select *
from (
select row_number()over(order by tempColumn)rownumber,*
from (select top 9950 tempColumn=0,* from pagetest where 1=1 order by id)a
)b
where rownumber>9900
2.分别在1万,10万(取1990页),100(取19900页)记录集下测试。
测试sql:
declare @begin_date datetime
declare @end_date datetime
select @begin_date = getdate()
<.....YOUR CODE.....>
select @end_date = getdate()
select datediff(ms,@begin_date,@end_date) as '毫秒'
1万:基本感觉不到差异。
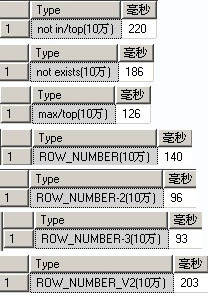
10万:
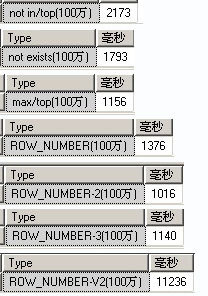
100万:
结论:
1.max/top,ROW_NUMBER()都是比较不错的分页方法。相比ROW_NUMBER()只支持sql2005及以上版本,max/top有更好的可移植性,能同时适用于sql2000,access。
2.not exists感觉是要比not in效率高一点点。
3.ROW_NUMBER()的3种不同写法效率看起来差不多。
4.ROW_NUMBER() 的变体基于我这个测试效率实在不好。原帖在这里 http://topic.csdn.net/u/20100617/04/80d1bd99-2e1c-4083-ad87-72bf706cb536.html
PS.上面的分页排序都是基于自增字段id的。测试环境还提供了int,nvarch,datetime类型字段,也可以试试。不过对于非主键没索引的大数据量排序效率肯定是很坑爹的。















 3819
3819











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









