





本篇文章将介绍实践中使用的大多数常见机器学习模型,以便花更多的时间来构建和改进模型,而不用解释其背后的理论。让我们开始吧。

机器学习模型的基础细分
所有机器学习模型都分为有监督的或无监督的。如果模型是监督模型,则将其再分类为回归模型或分类模型。我们将介绍这些术语的含义以及下面每个类别中对应的模型。
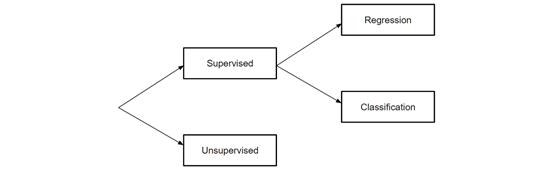
监督学习
监督学习涉及学习基于示例。将输入映射到输出的功能。
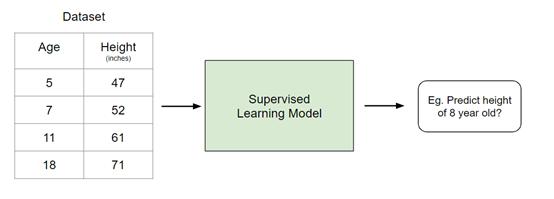
例如,如果我有一个包含两个变量的数据集,即年龄(输入)和身高(输出),我可以实现一个监督学习模型,以根据一个人的年龄预测其身高。
监督学习的例子
重申一下,在监督学习中,有两个子类别:回归和分类。
回归
在回归模型中,输出是连续的。以下是一些最常见的回归模型类型。
线性回归
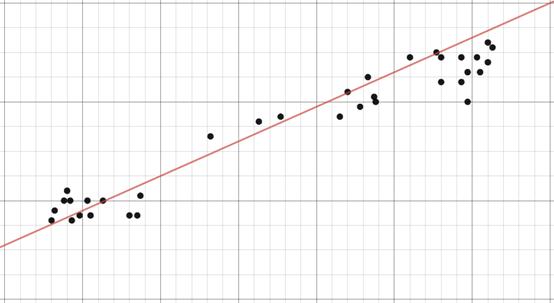
线性回归的例子
线性回归的想法只是找到最适合数据的线。线性回归的扩展包括多元线性回归(例如,找到最佳拟合的平面)和多项式回归(例如,找到最佳拟合的曲线)。您可以在上一篇文章中了解有关线性回归的更多信息。
决策树
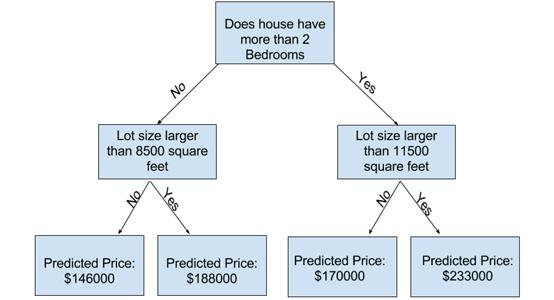
决策树是一种流行的模型,用于运筹学,战略计划和机器学习。上方的每个正方形称为一个节点,您拥有的节点越多,决策树(通常)将越准确。做出决策的决策树的最后节点称为树的叶子。决策树直观且易于构建,但在准确性方面却不足。
随机森林
随机森林是一种基于决策树的整体学习技术。随机森林涉及使用原始数据的自举数据集创建多个决策树,并在决策树的每个步骤中随机选择变量的子集。然后,模型选择每个决策树的所有预测的模式。这有什么意义呢?通过依靠“多数胜利”模型,它降低了单个树出错的风险。

例如,如果我们创建一个决策树,第三个决策树,它将预测0。但是,如果我们依靠所有4个决策树的模式,则预测值为1。这就是随机森林的力量。
StatQuest在完成这一工作方面做得非常出色。看这里。
神经网络
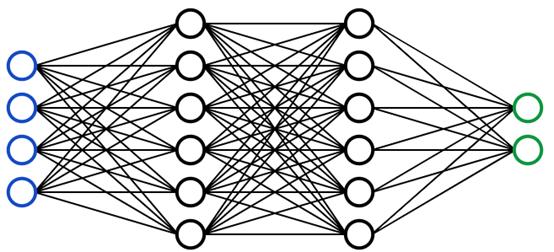
神经网络的视觉表示
一个神经网络是人脑启发多层模型。像我们大脑中的神经元一样,上面的圆圈代表一个节点。蓝色圆圈代表输入层,黑色圆圈代表隐藏层,绿色圆圈代表输出层。隐藏层中的每个节点代表输入所经历的功能,最终导致绿色圆圈中的输出。
神经网络实际上非常复杂且非常数学,因此我不会对其进行详细介绍,但是……
Tony Yiu的文章对神经网络背后的过程进行了直观的解释(请参阅此处)。
如果您想进一步了解神经网络背后的数学原理,请在此处查看这本免费的在线书籍。
如果你是一个视觉/音频学习者,3Blue1Brown对神经网络和YouTube上的深度学习一个惊人的一系列这里。
分类
在分类模型中,输出是离散的。以下是一些最常见的分类模型类型。
逻辑回归
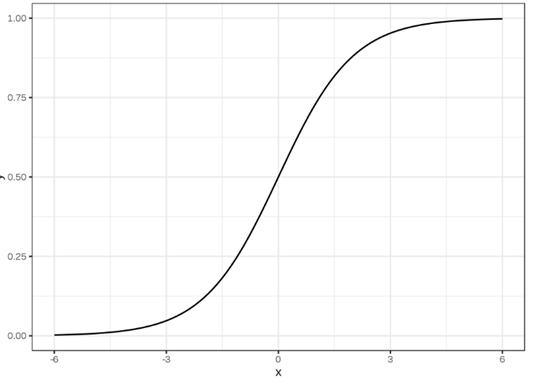
Logistic回归与线性回归相似,但用于建模有限数量(通常为两个)结果的概率。在对结果的概率建模时,使用逻辑回归而不是线性回归有很多原因(请参见此处)。本质上,以输出值只能在0到1之间(见下文)的方式创建逻辑方程。
支持向量机
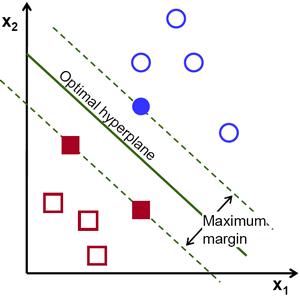
一个支持向量机是一种监督分类技术,其实可以变得相当复杂,但非常直观的在最基本的层面上。
假设有两类数据。支持向量机将在两类数据之间找到一个超平面或边界,以使两类数据之间的余量最大化(请参见下文)。有许多平面可以将两个类别分开,但是只有一个平面可以使两个类别之间的边距或距离最大化。
如果您想了解更多细节,Savan在此处撰写了一篇有关支持向量机的出色文章。
朴素贝叶斯
朴素贝叶斯(Naive Bayes)是数据科学中另一个流行的分类器。贝叶斯定理驱动着它背后的思想:
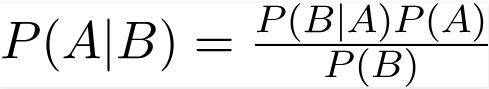
尽管对朴素贝叶斯(Naive Bayes)做出了许多不切实际的假设(因此将其称为“朴素”(Naive)),但事实证明,它在大多数情况下都可以执行,并且构建起来也相对较快。
决策树,随机森林,神经网络
这些模型遵循与先前解释相同的逻辑。唯一的区别是输出是离散的而不是连续的。
无监督学习
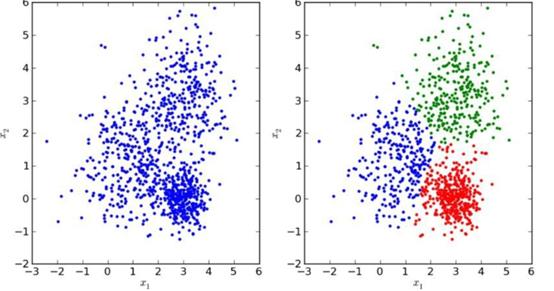
与有监督的学习不同,无监督的学习用于得出推论并从输入数据中找到模式,而无需参考标记的结果。无监督学习中使用的两种主要方法包括聚类和降维。
聚类
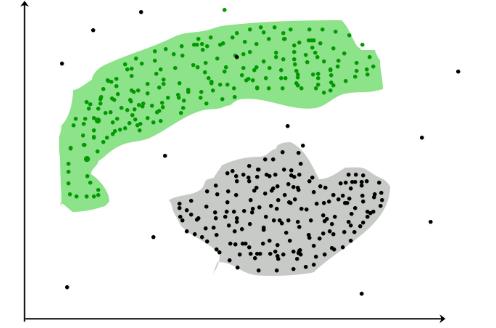
聚类是一种无监督的技术,涉及对数据点的分组或聚类。它通常用于客户细分,欺诈检测和文档分类。
常见的聚类技术包括k均值聚类,分层聚类,均值漂移聚类和基于密度的聚类。尽管每种技术在寻找簇时都有不同的方法,但它们都旨在实现同一目标。
降维
降维是通过获取一组主变量来减少所考虑的随机变量数量的过程。简单来说,就是减少要素集尺寸的过程(更简单地说,就是减少要素数量)。大多数降维技术可以归类为特征消除或特征提取。
一种流行的降维方法称为主成分分析。
主成分分析(PCA)
从最简单的意义上讲,PCA涉及将较高维度的数据(例如3个维度)投影到较小的空间(例如2个维度)。这样会导致数据维度较低(2维而不是3维),同时将所有原始变量保留在模型中。















 183
183











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









