





集合,字符编码
内容
- 集合类型
- 关系运算
- 去重(有局限性)
- 字符编码(理论多,结论少)
应用:
- 处理文本文件
- python字符串语法
----------------------缓冲带------------------------正题
1. 集合类型
1.1 作用
- 关系运算
- 去重(有局限性)
1.2 定义
在{}中用逗号分隔开多个元素,多个元素满足下列三个条件
- 集合内元素必为不可变类型
- 集合内元素无序
- 集合内元素没有重复
s = {1,'ds'}
# s = set({1,2})了解
s = {}
# 默认是空字典
# 定义空集合
s = set()
print(s,type(s))1.3 类型转换
set('hello')
# 剩下helo(无序)1.4 内置方法
关系运算
1.4.1 取交集
两者共同点
friends1 = {'Sb','Richard','吃鸡','Egon'}
friends2 = {'Joy','Richard','WangZheRongYao','Egon'}
res = friends1 & friends2
print(res)
print(friends1.intersection(friedns2))1.4.2 取合集
两者所有着
friends1 = {'Sb','Richard','吃鸡','Egon'}
friends2 = {'Joy','Richard','WangZheRongYao','Egon'}
print(friends1.union(friends2))1.4.3 取差集
friends1/friends2独有的好友独有的好友
friends1 = {'Sb','Richard','吃鸡','Egon'}
friends2 = {'Joy','Richard','WangZheRongYao','Egon'}
print(friends1 - friends2)
print(friends1.difference(friends2))
# 取friends1独有的好友
print(friends2 - friends1)
print(friends2.difference(friends1))
# 取friends2独有的好友1.4.4 取对称差集
去掉两人共有的好友
friends1 = {'Sb','Richard','吃鸡','Egon'}
friends2 = {'Joy','Richard','WangZheRongYao','Egon'}
print(friends1 ^ friends2)
print(friends1.symmetric_difference(friends2))1.4.5 父子集
包含的关系(比的是整体,部分不算)
s1 = {1,2}
s2 = {1,2,3}
# 不存在包含关系,以下均为Fales
print(s1<s2) # True 必须是s1大于或等于,才为True
print(s1>s2) # Fales
print(s1.issuperset(s2))
print(s2.issubest(s1))去重
- 只能针对不可变类型
- 无法保证原来的顺序
其他操作(辣鸡)
# 1.长度
s={'a','b','c'}
print(len(s))
# 2.成员运算
print('c' in s)
# 3.循环
for item in s:
print(item)其他内置方法
555~
s = {1,2,3}
s.discard(4) # 删除,没有值不变
print(s)
s.remove(4) # 删除,值不存在就报错
s.update({1,2,5}) # 添加
s.pop() # 删,不指定参数随机删
s.add(4) # 单独添加
s.isdisjoint({5,8,9}) # 两个集合完全独立,没有重复返回True,反之返回Fales
# True2.字符编码
2.1 字符编码介绍
2.1.1 什么是字符编码
人类与计算机交互,肯定是用人类的字符,比如'Good','不错'等等,
但是,计算机只知道'100011001010101000'也就是二进制数字,代表着高低电流
聪明的人类想,能不能制定一套规则,把我们的字符对应成计算机可以识别的‘110101100’
于是,他们写了一套规则 这就是字符编码表
字符编码表 存入内存'上' >----翻译----> 100101000100011110010
字符编码表 已存入内存的值'上' <----翻译----< 100101000100011110010
2.1.2 字符编码发展史
2.1.2.1 阶段1:一家独大
计算机起源于美国,人家只考虑了英文字母和键盘上的符号,发明出了 ASCII 表
ASCII表采用8位二进制数(1bytes),每8位二进制数对应一个英文字符
只能识别英文字符
(ps: 你能用美式键盘+英文输入法输出的,ASCII表都能读取)
2.1.2.2 阶段2:群雄纷争
后来计算机传到中国,日本,韩国······
字符编码表这么简单,谁都能创造一个
于是,中国人定制了 GBK ,日本人定制了 Shift_JIS ,韩国人定制了 Euc-kr ······
······
其实这些编码没你想象的那么复杂,GBK就是在ASCII上加入了中文字符于二进制数的一一对应的关系,以此类推。
(补充:GBK是采用英文字符还是8位二进制数,但中文字符是16位二进制数,至于Shift_JIS、Euc-kr···有多少位,我就不太清楚)
2.1.2.3 分久必合
2.1.2.3.1 Unicode
- Unicode兼容万国字符
- 采用16位二进制数(2bytes)对应中文字符
- 个别生僻字采用4bytes,8bytes
- 现代计算机内存中统一使用
Unicode表里面放的是: 人类字符 -----> Unicode格式的数字
Unicode表流程
人类的字符(英文) -------- Unicode格式的数字(内存中)---
| |
| |
| |
硬盘 硬盘
| |
| |
| |
(转换) (转换)
GPK格式的二进制 Shift_JIS格式的二进制老的字符编码都可以转换为Unicode, 但是 不能通过Unicode互相转换 !
2.1.2.3.2 utf-8
引子:
但是,想实现存入操作又支持万国字符的话,Unicode就不行了:
如果我要是99.99%都是英文,代码就是'0000000010101001'
前面的'00000000'就浪费了
不说占内存,这么多东西,就会增加磁盘IO操作,进而非常慢 ······
正题
utf-8 意思是Unicode transfrom format-8
transfrom的意思是转换,format的意思是格式
utf-8的意思也就是Unicode转换格式-8
规则如下
1个英文字符 ----> 1byte(8位二进制)
1个中文字符 ----> 3byte(24位二进制)
有人要问了,原来中文字符一个是2byte,现在变成了3byte,这不是越优化越坏吗
A:Unicode生僻字还4byte,8byte,知足长乐吧
2.1.2.4总结
- 内存固定使用Unicode,我们可以改变得是硬盘存入方式
- 英文+汉字 ---> unicode ---> GBS
- 日文+汉字 ---> unicode ---> Shift_JIS
- 王者(万国字符)--- Unicode ---> utf-8
2.1.3 文本编辑器关于字符编码的应用
我用Noatpad++建了一个txt,把你瞅啥翻译成了n种语言
用的是有道翻译
保存好没有乱码
我们就用这个文档来演示一下
2.1.3.1 存乱了
首先确认,右下角显示的是utf-8
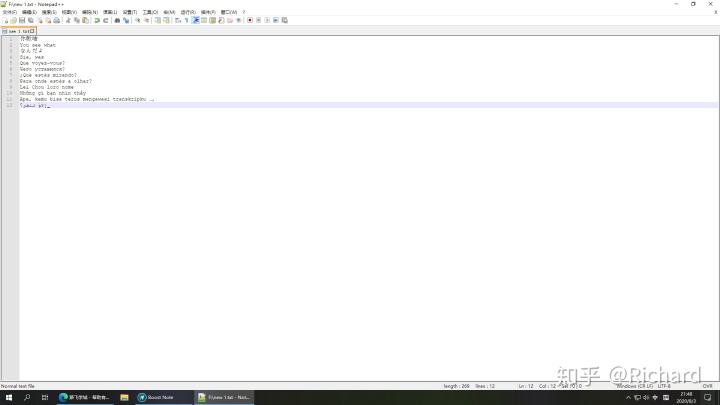
然后剪切掉内容
点上面的语言,然后选择Shift_JIS
保存
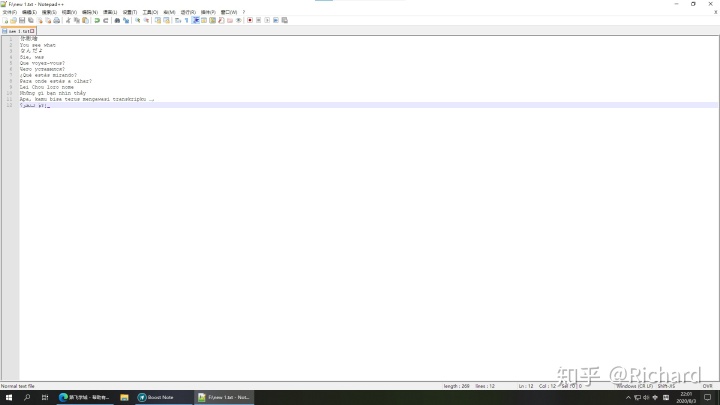
没有乱码吗?
目前用的还是内存方面(万能Unicode)
我再退出重进一下
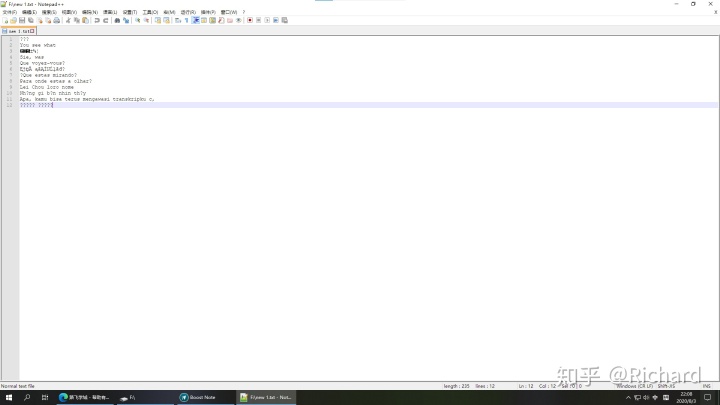
乱了!
(日文可能不识别平假名)
此处加图片
我的数据已不复存在
转成utf-8也没用了
555~~~
2.1.3.2 取乱了
首先,把utf-8改成GBK(GB2312)
随便写汉字
保存重进
把编码改成Shift_JIS
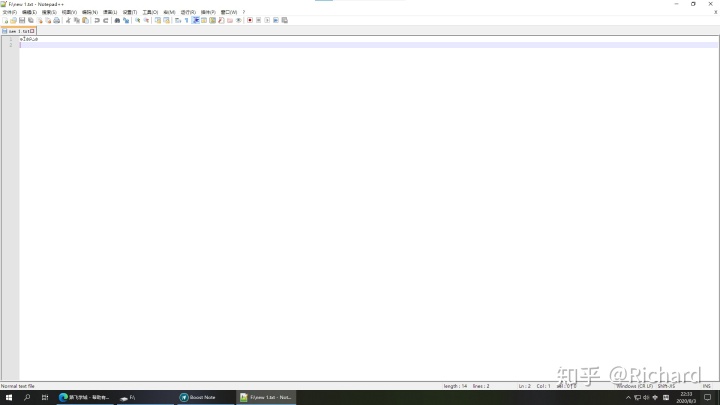
差点没了
改成GBK
数据又得到恢复了
2.1.3.3 文本文件乱码问题总结
存乱了:编码格式要设置为支持文件内字符串的格式(utf-8)
取乱了:是以什么格式存进硬盘里的,就把错误的改回来
(ps:win10是因为Noatpad++只能在win10上运行)
2.1.4 python应用
python2中,默认使用的是ASCII表
python3中,默认使用的是UTF-8表
保证前两个阶段不乱码
其实在开头加这个就可以了
# coding utf-8保证字符串不乱码
在python2中可以这么写
x = u'上'python3就不用了
end
附:
Unicode首页地址
https://home.unicode.org/home.unicode.orgUnicode编码文档地址
Unicode 13.0.0www.unicode.org














 603
603











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









