





中文分词任务是一个预测序列的经典问题,已知的方法有基于HMM[1]的分词方法、基于CRF[2]的方法和基于LSTM的分词方法。
本文介绍Xinchi Chen等人[3]提出的基于LSTM的分词方法。根据Atlas ML团队的工作[4],基于ICWS2005MSRA数据集上的最佳模型,由上述LSTM模型的分词方法取得,F1值为97.40%,其模型结构为预处理层+多字(Bigram)+LSTM层+CRF层。
本文根据Xinchi Chen等人的论文,在ICWS2005PKU数据集上,利用Keras构建网络进行了重复实验,损失函数用了文中提到的squared_hinge方法,optimizer用了nadam方法。模型分为四层,第一层输入层的最大长度为1019,由于在PKU训练集和测试集上最长语句为1019个字;第二层为嵌入层,其中根据PKU训练集生成的字表为4698个字,并增加一个未登录词字符,共4699个元素,嵌入空间100维,标识0为特殊字符在空间隐去(对于未登陆此,输入层传参时索引赋值为0);第三层为双向LSTM层,含150个lstm cell单元,经过Xinchi Chen实验证明窗口为(0,2)时,即对于每个字符c,(c+0,c+2)的滑动窗口时LSTM效果最佳,直接采用它的结论进行实验;最后加入全连接层,kernelregularizer使用了0.0001的L2正则。训练的batch_size为1024,训练100轮,在PKU测试集上达到了0.9566的精度。
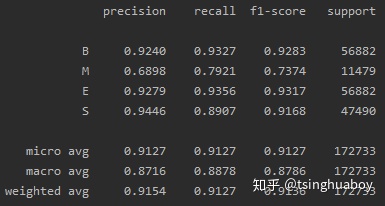
原始论文的F1值为95.7%,仅利用C0窗口的BiLSTM模型在PKU测试集上的准确率,见图1:
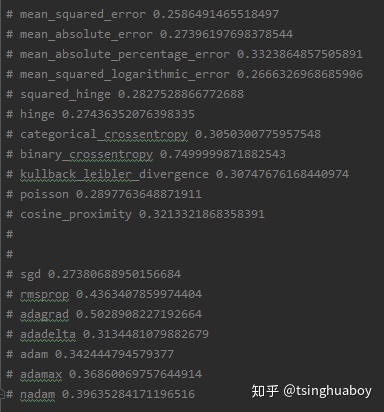
各损失函数与优化函数在模型下,训练1轮达到的精度如图2:
实现的程序见[5]。
[1]隐马尔可夫模型;部分可见马尔可夫模型. https://zhuanlan.zhihu.com/p/106054580.
[2]Conditional Random Field中文分词. https://zhuanlan.zhihu.com/p/107593308.
[3]Xinchi Chen etc al. Long short-term memory neural networks for Chinese word segmentation. //Conference Proceedings - EMNLP 2015: Conference on Empirical Methods in Natural Language Processing.
[4]Atlas ML. Chinese Segment State of the art. https://paperswithcode.com/task/chinese-word-segmentation
[5]LSTM中文分词. https://github.com/ShenDezhou/LSTM.















 1550
1550











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









