





1、长尾请求
说到请求的响应时间,人们最容易想到的是平均响应时间,而大型互联网公司常常挂在嘴边的会是99%的请求在XX毫秒之内返回。
之所以99%的请求很重要,是因为在制定服务SLA时99%请求的响应时间是非常重要的指标之一。想更多了解SLA制定的同学,请参考“云中慢步”公众号之前文章:SLI,SLO和SLA。
除去99%的请求,这剩下的1%就算是长尾请求了(不排除有公司要求更高,可能0.1%才算)。在本文中的长尾请求(慢请求)是指响应时间超过1秒的请求。
长尾请求的形成原因有很多种,以搜索引擎为例,常见的有:
1. 查询词属于偏僻词导致的磁盘访问;2. 查询词匹配过多结果导致处理时间变长;3. 恶意组合的复杂查询请求;4. 查询路径上的慢节点。关于前3种长尾的优化可以在网上找到较多的介绍,本文主要介绍最后一种情况,查询路径上的慢节点导致的长尾请求。
这里可能有人会问,为什么要分析长尾请求呢?两方面的原因:改善整体响应时间和节省成本
1)改善整体响应时间
在分布式系统下,一个请求的处理需要调用很多其他服务来完成。
尤其是对于像搜索这样的服务,需要在大量的数据集中检索匹配的内容,这就涉及到并发的到大量机器的查询,优化长尾可以改善整个服务的响应时间。
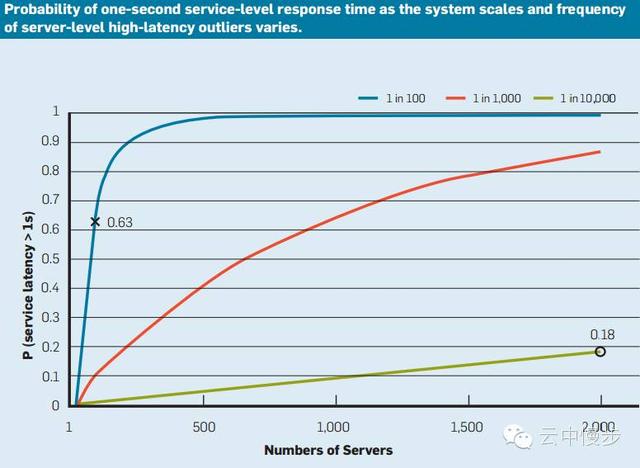
如下图所示,假设某服务处理时间超过1秒(Service Latency > 1s)的比例仅为 1% (对照图例中的蓝线,1 in 100)。
再假设:为了完成查询请求,前端服务需要同时查询100个該服务的实例。
那么,前端服务中服务延时大于1秒(Service Latency > 1s)的请求将超过63%!亦即图中 0.63 的位置。
From Jeff Dean: Tail At Scale
由图可知,即使服务处理时间超过1秒的比例仅为 0.01% (对照上图中的绿线,1 in 10000),当需要同时查询的实例数(Numbers of Servers)达到2000时,服务延时大于1秒的请求数将超过18%!
2)节省成本
为了给用户提供更好的服务,制定SLA时服务的响应时间不会超过1秒,一般在几百毫秒之内。关于响应时间对收入的影响,已经是普遍的共识了,会减少广告点击、降低用户转化率等,在最近几年SLA的制定过程中长尾的响应时间发挥了越来越重要的作用。
然而当系统调用链复杂时,兼顾低延迟和高资源使用率是非常有挑战性的。因为我们要讨论的这种长尾一般是由共享资源的争抢使用导致的,触发条件比较苛刻,调试起来就更加困难了。
所以导致很多公司只能通过降低资源使用率来获得更好的响应时间,虽然这意味着购买更多的机器。
反之,通过分析长尾请求,从而定位到问题并解决,可以大量的节省成本。
要知道提高1%的资源使用率都可以节省几百万美金的数据中心开支。
2、分析工具
然而,并不是所有的性能分析工具都适合分析长尾问题的。例如perf是Linux系统下最常见的性能调试工具,除了perf还有很多其他的工具,都是基于采样的profiler。
基于采样的性能调试工具,使用起来很简单,而且对系统造成的额外负担也很小。因为perf会把采样到的数据汇总成平均值。
但是长尾问题是很难在均值的情况下被分析的,所以对于类似长尾请求的这类性能问题,perf就有心无力了,比如一个典型的搜索请求,如下图所示:
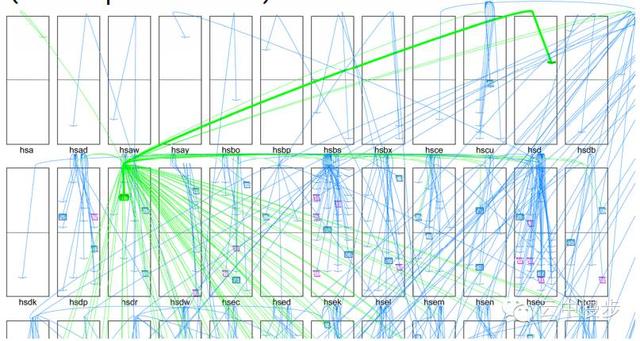
图中每个长方形代表一个机架,每条线代表了一个RPC请求,可以看出一个搜索请求的处理需要涉及几百台机器。
那条绿颜色的粗线是进来的RPC,绿颜色的细线条是第一次扇出(fanout),蓝颜色的线条是第二次扇出,第二次扇出之后的机器还有RPC到最终叶子节点的调用没有画出来,每个叶子节点花费1-2ms处理请求,然后结果被一级级汇总,最后返回给用户。
因为涉及了大量机器的扇出RPC调用,每一个搜索请求都会受到长尾的影响(前面提到的假设1%的长尾,在对100个机器的调用时会导致63%的请求受到影响),这样的系统perf是没法定位慢请求的性能原因的。
上面这张搜索调用图,很形象的描述了一个east-west network traffic,一个请求带来大量的数据中心服务器间流量,相比于以前的north south network traffic,现在对数据中心的网络带宽要求是前所未有的,多层次分布式的RPC调用对性能排查工具的要求也是前所未有的。
虽然谷歌的Dapper系统可以对分布式系统的调用进行端到端的追踪,从而定位到某个软件模块拖慢了整个请求。但是由于慢请求的不确定性,它也很难定位到具体的触发原因。
对于这样的问题,谷歌公司的Dick Sites和其他工程师开发了一个trace系统,这个系统捕获“所有”时间,可以轻松的实现对长尾问题的定位,下面用一个例子来看看这个系统能解决什么样的性能问题。
3、案例分析
Slow RPC
还是上面那个搜索请求,但是另外一种形式:
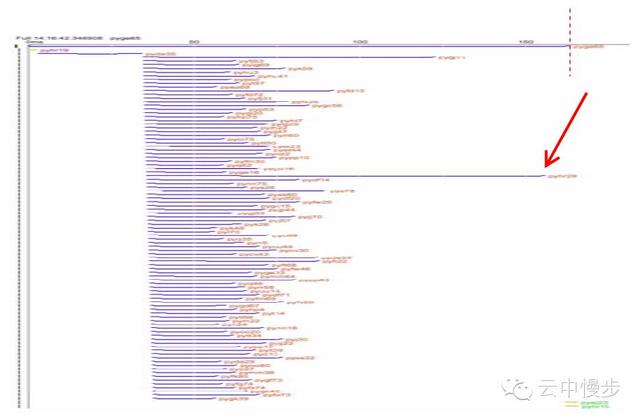
最上面一条线是整个搜索的处理时间,下面的每条线代表了一个RPC请求到不同的机器,可以看出整个搜索的响应时间被一个慢请求拖慢了。
因为大部分的RPC都是正常的,只有少数几个RPC是慢的,所以为了能够排查问题仅仅有汇总的数据是根本不行的。
我们需要一个系统能够放大所有的慢请求,而且因为慢请求很难重现,所以这个系统需要一直运行,从而能够事后分析。
一直运行带来的问题是资源占用,因为Dick Sites同学的这个trace系统是为了解决性能问题从而能提高资源使用率,而且需要运行在所有机器上才能捕获所有的信息,如果占用过多资源,就失去了设计该系统的意义,大佬们肯定不会同意。
最终该trace系统可以使用的系统资源是1%的CPU!
接下来让我们看一下慢RPC所在的机器:
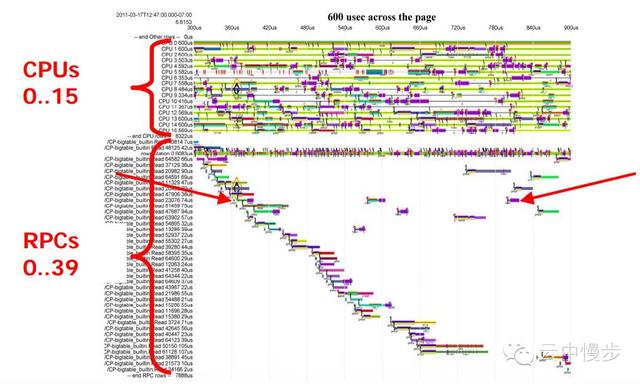
这台机器有16个CPU,同时在处理40个RPC,大部分RPC的处理时间在50us左右,但是有几个RPC的处理时间格外的长。
如果只关注其中一个慢RPC:
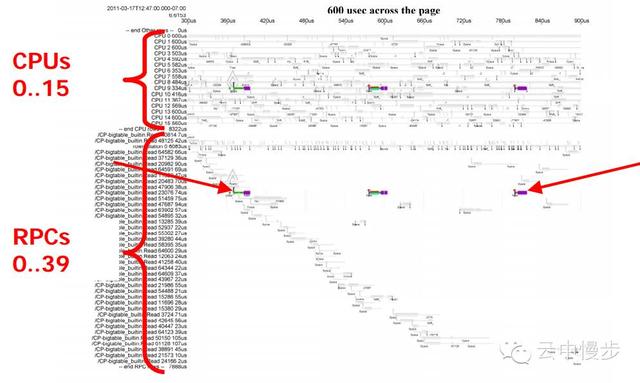
我们可以看到的是这个RPC大部分时间都在wait,真正执行的时间很短。
这时,常见的profiler工具,比如oprofile在这种情况下起不到作用,因为它只能告诉我们关于RPC在执行时的情况,而现在我们需要知道的是为什么RPC会block。
换一个角度,看一下同样的时间段,线程和锁的情况:
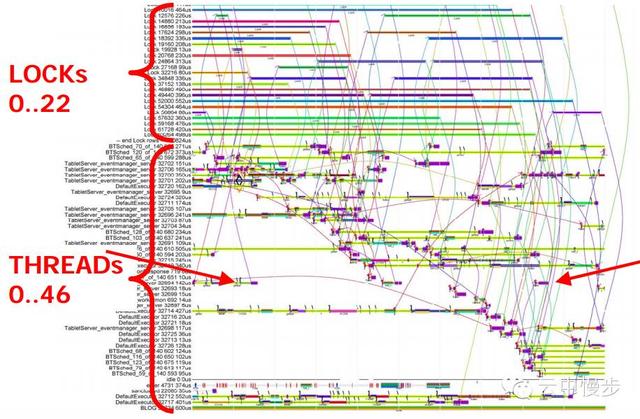
两个箭头之间的是同一个RPC,可以看到该线程等待lock花费了绝大部分时间,为什么呢?
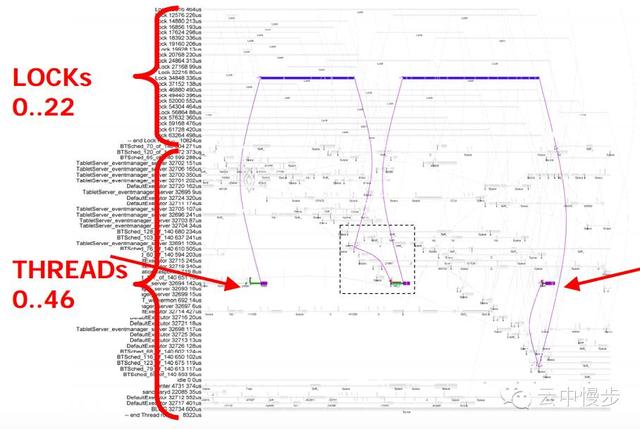
上图去掉了其他无关线程,两个箭头之间依然是之前那个慢RPC线程,可以看出来该线程是在等同一个lock,让我们进一步放大:
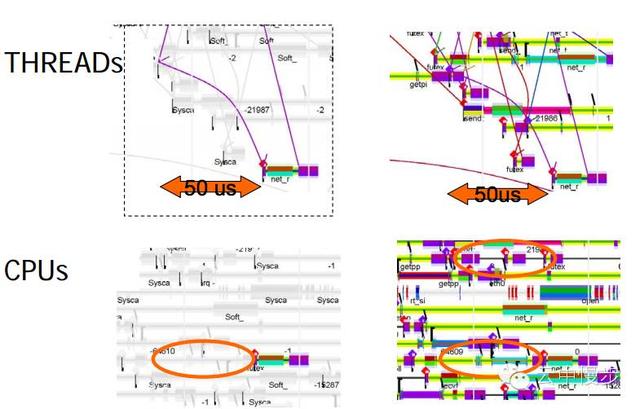
这时可以看到该线程被执行是在获得lock之后50us,被放在同一个CPU上执行,50us的等待是因为之前有其他线程在该CPU上执行,但是在这50us的等待时间时,是有其他CPU空闲的。
最终的答案是:CPU亲和策略导致内核调度器始终把线程调度到之前执行的CPU上。
虽然这样的本意是为了保证最好的cache locality,但是带来的问题是:线程就必须等待其他线程结束后才能获得该CPU的使用权。
这样的等待值不值得,就要权衡等待时间和在其他CPU上运行时的cache latency了,通过该框架分析更多的trace之后才有可能做出最好的判断。
结束语
如此复杂的性能问题,依靠传统的采样profiler是不可能追踪定位到根本原因的。
Dick Sites和工程师们开发的trace框架在仅仅使用不到1%CPU的限制下,能够捕获到足够的信息来还原分布式场景下系统的状态,需要对硬件系统的工作方式非常了解,并能够结合各个硬件的特点,进行精密的软件设计,才能够在不影响系统系能的情况下完成既定目标。
不知道将来谷歌会不会考虑开源这个系统,至少来篇Paper也行,嘿嘿!















 1769
1769











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









