





字符匹配算法
BF算法
KMP算法
先在开头约定
文中原始待匹配字符串为text,如“ababcabc”
匹配串为pattern,如“ababc”
最长前后缀数组为prefix[ ]

BF算法概述
BF算法属于暴力匹配算法,时间复杂度在O(mn),较为耗时间。
其原理在于从头遍历text串,当text中某字符与pattern中第一个相等时,继续将指向text的下标值(i)向后移,同时将指向pattern的下标值(j)向后移
当出现text和pattern对应字符不相等时,将i回溯至上一次开始匹配的位置的下一位,将j回溯到0的位置,重复执行此操作
当pattern被j遍历结束的时候,则表明匹配成功;当text被遍历结束的时候,则表明匹配失败,在text中未找到pattern
BF算法较为简单,这里不做详细介绍。

KMP算法介绍
前置知识:最长公共前后缀(prefix table)
假设pattern=“ababca”,则如下图:
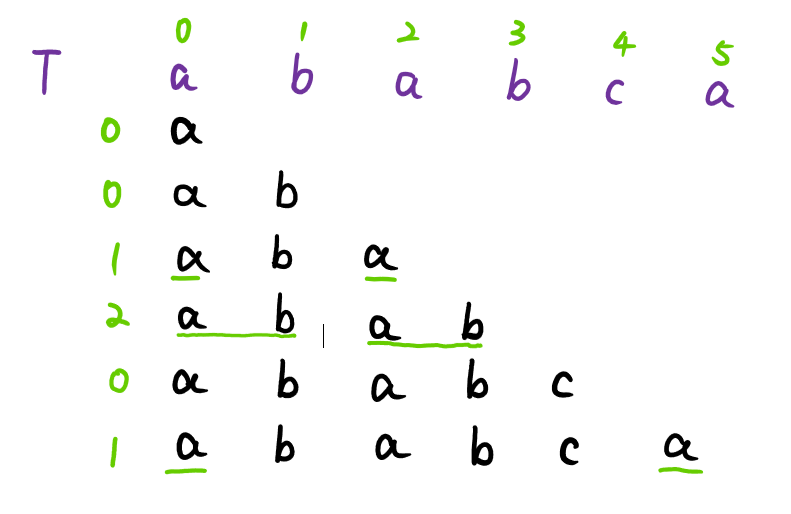
其中原始串为“ababca”,则产生六个子串。以“abab”为例,产生的不包括本身的前缀为“a”和“ab”和“aba”三个,产生的不包括本身的后缀为“b”和“ab”和“bab”三个,所以最长公共前后缀长度为2。
产生一个prefix数组,prefix[ ]={0,0,1,2,0,1},在KMP算法中,为便于算法构造,将最后一位删除,在第一位补-1,则形成prefix[ ]={-1,0,0,1,2,0}。prefix数组的作用在下文将详细给出。
算法正式开始
设text=“abaacababcac”,pattern=“ababc”。
由pattern产生的最长公共前后缀数组为prefix[ ]={-1,0,0,1,2},称为前缀表。
pattern字符串由0开始从头到尾下标为0~4,下标称作index。
遍历text的下标为i,遍历pattern的下标为j。
KMP算法比之BF算法的高明之处在于不必将i回溯,从而只需遍历一遍text,将整个算法的时间复杂度降到O(n+m)。
KMP算法的做法是将text和pattern从头进行匹配。
当匹配成功时,i和j分别向后移,直至i和j所对应的字符不一致。
这时将j往前回溯到某一特定位置,动态的想法就是将pattern串往后滑动一段距离,继续将i和j进行往后遍历,重复当前做法,直至匹配成功或者text串结束。
下面由图来讲解一下:
从头开始匹配,遇到第四位时失配:
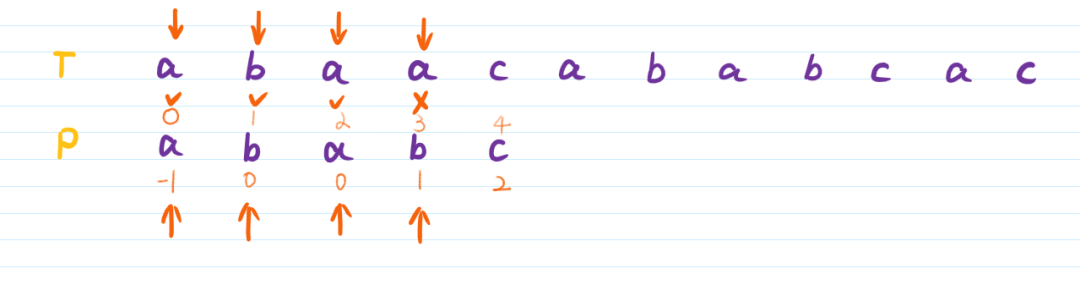
这时,将P串向后滑动一段距离,而这段特定的距离就是前文prefix table的作用。
根据前缀表中,失配的P串的位置下标为3,则将P串滑动到prefix[3]的位置,也就是pattern[1]的位置。
如下图:
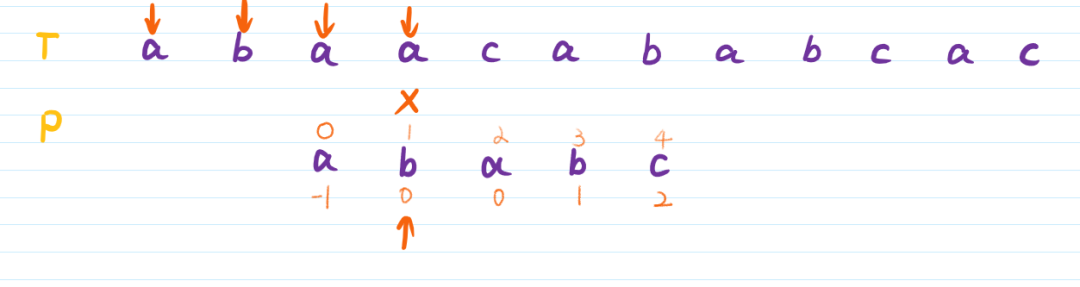
这时,T串i指向‘a’,P串j指向‘b’,又不匹配,则继续将P串右移,如图:
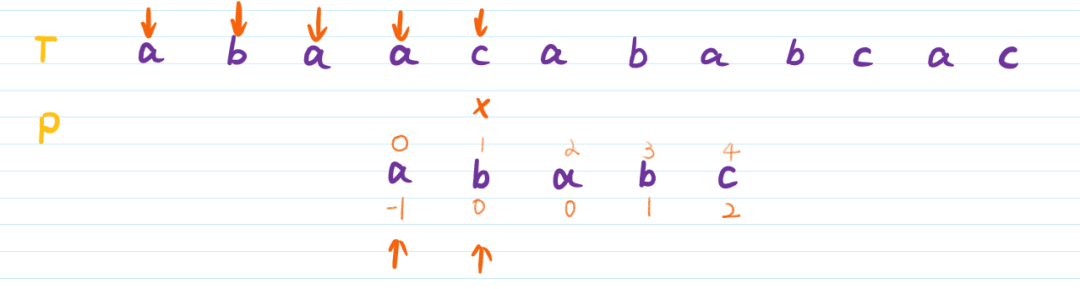
直至!

j==strlen(pattern) 时匹配成功!
这时,如果题目只要求检查是否可以匹配成功,则可以退出。
若要求求出在text中含有几个pattern串则需要继续。
将P串向右滑动特定距离。
这里的特定距离指的是P串末尾字符所对应的前缀表的位置
即P[2]的位置。

直至这时,整个算法结束!!!
看到这里,相信聪明的同学已经看出来prefix数组的作用了
那就是确定当失配时P串需要往后滑动的距离。
而具体怎样确定!!!
我们知道,prefix是最长公共前后缀,
例如,prefix[3]=1,即表示P[3]之前的串的最长公共前后缀长度为1,这里不包括P[3]本身。
当P串本身往后滑动后,需要寻找与前面匹配的最长距离,从而避免重复匹配损耗时间。
以第一个步骤为例:
当j指向b时,b之前的串最长公共前后缀的长度是1,即“aba”的最长公共前后缀长度为1。
所以P滑动到P[1]的位置,即可保证变化后的P串的j之前的1长度的串与i之前的1长度的串是完全一致的,即

算法介绍结束!!!
下一篇介绍具体代码实现。
才疏学浅,疏漏百出,如有错误,我也不听!
更多文章请移步brillanza.gitee.io















 354
354











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









