






利用python进行数据预处理,不能离开pandas,我看过的教程在介绍数据预处理时的流程都是:numpy介绍、pandas介绍、数据预处理。
对于numpy和pandas,我的经验是不用刻意去记,知道他们分别是干嘛的(别人问到不至于说不出来),使用方法要有个印象,然后实际运用中有需要再去查就可以。
numpy:科学计算
pandas:基于numpy,非常适合于数据预处理。
本案例的数据预处理思路:【重点】重复值、异常值、缺失值;【细节】格式清洗、数据提炼(在该案例中没有进一步数据提炼)。
1. 导入数据,并查看数据的基本情况:
import 
从这一步的结果来看,可以初步判定:
- 数据存在缺失值(总数据共5100条,但是出发地、目的地、价格、节省四个变量下数据量都小于5100)。
- 数据可能存在异常值(描述性统计中,价格最大值达到179500,不符合实际情况,需要后续标准分判断是否属于异常值)。
- 数据可能存在重复。
- 数据的列名有些存在空格,有些没有空格,需要对列名进行格式化,方便后续调用。
2.【细节】预处理:数据框列名格式化
DataFrame.columns = [x.strip() for x in DataFrame.columns]可将列名前后的空格去除。
3.【重点】数据去重
DataFrame.duplicated() 返回每一行的True or False,实际上对去重没有什么帮助。
数据去重暂时只需要记住两个有用的
DataFrame.duplicated().sum() # 看一下重复值有多少
DataFrame.drop_duplicates() # 直接去重去重后,100条重复数据被删除,剩余5000条。

【NOTE】数据去重后,原来的索引会出现间断!所以需要进行索引重构!
DateFrame.index = range(data.shape[0]) # 重新生成0-4999的索引号4.【重点】异常值处理
异常值的处理需要考虑具体的业务环境,不同业务环境对异常值的定义不同
在该案例中,重点关注的是“价格”和“节省”两个数值型变量下的异常值
在该案例中,将“价格”列做标准分,标准分绝对值大于3的视为异常值,同时“节省”列的值大于“价格”列的值也视作异常
将满足异常判定条件的数据进行删除
# 在数据框中寻找满足上述条件的数据
std_score = (DataFrame['col_name']-DataFrame['col_name'].mean())/DataFrame['col_name'].std()
DataFrame[std_score.abs() > 3] # 第一个条件
DataFrame[data['节省'] > data['价格']] # 第二个条件
pd.concat([DataFrame[std_score.abs() > 3], DataFrame[data['节省'] > data['价格']]]) # 合并两个条件
# 获取异常数据的index
del_index = pd.concat([DataFrame[std_score.abs() > 3], DataFrame[data['节省'] > data['价格']]]).index
# 删除
DataFrame.drop(del_index, inplace=True)
5.【重点】缺失值的处理
对于缺失值具体情况的查看,掌握两个代码模板即可
DataFrame.isnull().sum() # 查看数据框总体缺失情况
DataFrame[DataFrame['col_name'].isnull()] # 某列缺失值的具体情况
该案例中,对于“价格”和“节省”列的缺失值,却用平均值补全
缺失值补全掌握一个代码模板即可
DataFrame['col_name'].fillna(round(DataFrame['col_name'].mean()), inplace=True)该案例中,对于“出发地”和“目的地”列的缺失值,可以用数据提炼的方法在其他列寻找缺失项(路线名字符串中包含出发地和目的地)
# 使用loc相对位置找到缺失值的具体位置
DataFrame.loc[DataFrame['出发地'].isnull(), '出发地']
# "路线名"列数据提炼
[str(x)[:2] for x in DataFrame.loc[DataFrame['出发地'].isnull(), '路线名']]
# 合起来就是:
DataFrame.loc[DataFrame['出发地'].isnull(), '出发地'] = [str(x)[:2] for x in DataFrame.loc[DataFrame['出发地'].isnull(), '路线名']]
# 对于“目的地”缺失值的补全同上,不赘述。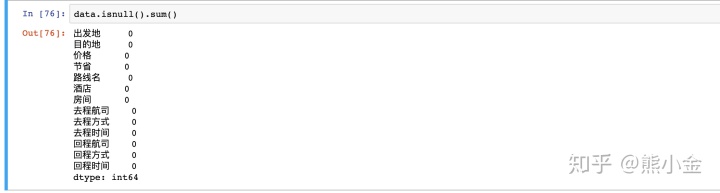
6.【细节】数据提炼
对于数据框中剩余的列,还可能包含着对分析有用的信息,比如“酒店列”包含着酒店评分等。
对于这些数据,可以使用正则表达式进行信息提炼,将提炼后的信息生成新的变量列加入数据框。
···2020.2.11更新补充···
在实际业务中,原始数据的缺失值可能会被标记为0或999之类的数值,导入pandas进行数据预处理时,可以使用DataFrame.replace("自定义缺失值", np.nan)替换为pandas可识别的缺失值类型。
对于缺失值的处理,最好是不要直接删除含缺失值的数据,而是要尽可能保留数据信息。若要删除缺失值,使用DataFrame.dropna()

学习要有输入更要有输出。
该文章作为自己的学习输出,可能有些地方是按照自己能看懂的方式写的,模糊的地方还请见谅。
欢迎交流和指教!















 212
212











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









