





高分辨距离像(High Resolution Range Profile,HRRP)样本中蕴含目标重要信息,但是受其自身可视性的限制,这些信息并不适宜直接用于识别[1]。为此,必须细致地剖析HRRP样本,尽量准确地获取繁杂数据中的重要信息,方可实现对目标的准确识别。
依据数学分析,常规信号可采用某空间(域)内的若干基函数组合来表达。因此,以往有不少识别算法尝试将目标HRRP映射到某个特定域内,借助适当变换来完成对其的分析、表达,尤其是降维表达[2]。近年来对稀疏理论的研究发现,想要更为精准地对特定信号开展降维分析,其实可在考虑并衡量信号自身特征的基础上,依据冗余度更大的基函数组合来完成。本文就将遵循特征表示的识别思路,依据稀疏理论,探讨能够更为简洁且稳健提高HRRP目标识别效果的方法。
1 稀疏分析技术要点
由常规正交基构成的字典种类很多,且优势鲜明。目前,其实已有不少研究针对特定的应用,找到了与之契合、意义明确的正交基,用以完成工作所需的信号分解及表达。可是依此所得的分析结论并非均可推广,或者具备借鉴意义。换言之,在实际信号相对复杂,且可能具有未知特性的情况下,仅依靠由某一确定正交基构造的字典,往往很难保证其对信号表达的准确性,自然也无法保证变换、表达的稀疏性。
为了弥补简单正交字典的劣势,同时又保留其优势,或可尝试借助多个正交基级联构造冗余字典,以达到预期表达效果。事实上,这类研究思路已在图像信号处理中得到了应用及验证[3-4]。研究人员曾围绕常用(诸如:时-频、Meyer-Lemarié小波及傅里叶基等)级联字典的设计和相关分解思路进行探讨,但以往此类字典大多仅借由两种正交基组合构造,因此为了进一步提升此类字典的表达能力,可考虑将其拓展为更多个基的组合,以构造一类兼具正交性及过完备特点的联合字典,并用以实现对雷达一维HRRP信号的稀疏分析。
1.1 联合字典

为了满足求解的唯一性条件,并兼具较好的表达能力,本文的联合字典考虑选用一类具备良好正则性的Daubechies小波(dbN,N为阶数) 。对于dbN小波,通常随着N的增加,将使得信号在依其变换后的能量愈发集中,数据压缩率愈高。不过,N增大在带来压缩优势的同时,却削弱了其时域紧支性,影响了对样本进行稀疏表达所涉的运算量,制约了分析的实时操作性。
为此,文中在采用其构造联合字典进行HRRP稀疏分析时,不仅对子字典选择进行了适当的折中处理(N=1~10),还尝试探寻更为快捷的分解策略。
1.2 分解策略

依据联合字典,采用改进的分组匹配追踪策略Improved Partition Matching Pursuit (IPMP)实现分解的具体步骤如下:

2 基于联合字典稀疏表达的目标识别
该识别算法将被划分为两个处理环节:前一环节主要关注如何自HRRP数据中筛选目标特征;后一环节则关注如何利用所得识别目标。
2.1 训练环节

(1)采用Daubechies系列小波基构造联合字典。
(2)基于样本求取类别字典。
借助IPMP算法,依联合字典对HRRP样本进行分解,以剔除样本中的无用成分,保留核心目标特征,同时实现数据降维,求得各目标类别字典Gl(l=1,2,…,N)。
2.2 测试环节
在这一环节,将借助类别字典Gl(l=1,2,…,N)对相应目标HRRP样本开展稀疏分析,以判定其类别。具体操作步骤如下:
初始化:根据数据类型,确定对其的校准策略,并得到测试样本y。

3 仿真分析
3.1 仿真数据说明
仿真环境:Windows 7系统,CPU频率为1.5 GHz,内存2 GB。仿真软件为MATLAB 2012b。仿真中用到3类飞机目标(B-1b、B-52、F-15型)的HRRP仿真数据,数据设定:雷达中心频率为5 520 MHz,带宽400 MHz,方位角控制在0°~180°间,每隔0.1°采集一次回波,当俯仰角及横滚角均为0°时,所得样本中等间隔筛选出600个用于训练阶段;当俯仰角调整为3°、横滚角也调整为3°时,所得样本中等间隔筛选出300个用于测试。另外,还将在测试样本中加入白噪声,以模拟不同信噪比的情况。
3.2 实验分析
3.2.1 训练仿真实验
为了有效地对HRRP信号进行稀疏分析,字典的选择至关重要,而与之配合的分解算法的选择也同样非常关键。本文依据联合字典,探讨了一类适用的IPMP分解策略。为了说明不同字典及分解方法对于样本表达测效果差异,图1中展示的是对于F-15机型同一组HRRP样本信号,分别依据Harr小波基或联合字典,辅以不同分解策略,经稀疏分析之后所得的逼近效果比对结果。
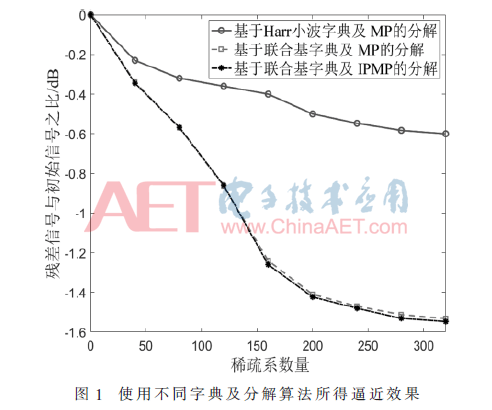
通过图1可知,首先,无论采用何类字典和分解策略,随着所选稀疏系数的增多,对原始数据表达的误差将逐渐减小。不过,减小到一定程度后,这种变化趋势会趋于缓慢,并趋向稳定。其次,比较了图示三类方法所得逼近表述的准确性,可以看出在使用联合字典时,由于其具备对多种特征的表达能力,因而适用范围更广,表述效果也相对更优,分解留存的残差也就更小。再次,图中还依据同一联合字典,就不同分解算法性能进行了比对。鉴于本文探讨的IPMP分解方法是在常规MP方法的基础上做了相应的修正,改善了后者求解时可能面临的过匹配难题,所以采用IPMP分解所得的表达准确率会适当优于使用MP所得。
除去表述上的差异外,更重要的是,使用IPMP算法将能够更快地完成样本分解。表1中给出了稀疏系数量为100、信噪比15 dB时,针对同一目标相同样本,分别用表内分解方法及字典进行稀疏分析时,所耗费时间的对比关系。
3.2.2 测试仿真实验
无论是何种应用背景,当样本信噪比较高时,识别分析效果往往相对较优。可是,实践中很难保证接收信号质量,为此所用识别策略应具备尽可能好的抵御杂噪、干扰的性能。本实验就此进行了算法间的比较分析,并给出了如图2所示的测试结果。

图2中就几类算法的性能进行了比对,其中本文探讨的方法以及依据PCA开展的识别均可归入依重构模型开展识别分析的类型。不同的是,前者将依据联合字典展开对HRRP的稀疏分析、降维处理,以达成识别分析的目的。相较而言,后者其实也具备类似的“去冗余”能力,可将HRRP样本由高维向低维映射,并且也能保留其潜在的数据结构,使得去冗余后的低维数据中仍然留存有原始信号的主要特征。不过,根据以往研究、应用也可了解到,虽然PCA算法中基的选取至关重要,可是它本身对此却有所制约,不仅如此,其主成分数量还受到信号维度大小的限制。显然,两者相比,本文所用的联合字典不仅冗余,约束也更弱,因此依其所得识别性能也就更优。
此外,本实验还比较了MCC、SVM识别算法的性能,结果显示:信噪比对各类算法的识别性能均有明显的影响。具体而言,SVM与本文算法相比,两者性能虽然在高信噪比时差别不大,但在低信噪比时却相距甚远,后者的抗噪能力显然更强。而用MCC法识别所得的准确率普遍较低,据本文算法取得的识别结果亦是优于采用MCC所得。不过,有研究表明[1],某些情况下其实可先借由对HRRP数据进行适当的幂变换预处理,再采用MCC法即可获取较好的辨识结果。但是,这类幂变换可能会造成噪声水平的放大,削弱目标分量,反而影响了MCC法识别分析的抗噪性能。
4 结论
本文将稀疏分析理论引入目标识别应用,并基于分组稀疏分析策略开展了对HRRP样本的剖析及识别。实验表明:基于分组稀疏分析思路的目标识别方案切实可行,能够用以达成对目标稳健、有效地识别;相比某些常规识别算法,文中所提方法具有抵御杂噪干扰的能力及识别准确率均更优。在当前宽带雷达普遍应用的背景下,文中所提算法实现过程简捷,大量压缩了样本分析量,缓解了此类识别势必面临的庞杂的数据处理难题。
参考文献
[1] 杜兰.雷达高分辨距离像目标识别方法研究[D].西安:西安电子科技大学,2007.
[2] 冯博,杜兰,张学锋,等.基于字典学习的雷达高分辨距离像目标识别[J].电波科学学报,2012,27(5):897-905.
[3] 全盛荣,张天骐,王俊霞,等.基于稀疏分解的SFM信号的时频分析方法[J].电子技术应用,2016,42(6):87-90.
[4] BI D,XIE Y,ZHENG Y R.Synthetic aperture radar imaging using basis selection compressed sensing[J].Circuits Systems & Signal Processing,2015,34(8):2561-2576.
[5] LIU X, FAN J, LI W.Concave minimization for sparse solutions of absolute value equations[J].Transactions of Tianjin University,2016,22(1):89-94.
[6] 陈发堂,丁月友,冯永帅.大规模MIMO中基于GSSK系统的稀疏检测算法[J].电子技术应用,2016,42(7):107-110.
作者信息:
段沛沛1,2,李 辉1,雒明世2
(1.西北工业大学 电子信息学院,陕西 西安710029;2.西安石油大学 计算机学院,陕西 西安710065)















 1793
1793











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









