







1.文档编写目的
Fayson在前面的文章0403-如何在Hadoop中处理小文件、0455-如何在Hadoop中处理小文件-续和0405-如何使用Impala合并小文件等,在文章中也详细说明了怎么去处理Hadoop中的小文件。文章中也提到小文件过多会对NameNode造成压力,导致NameNode内存使用过高。本篇文章Fayson主要使用Hadoop Archive Files功能将集群中的小文件进行归档。
- 测试环境:
1.操作系统:Redhat7.4
2.CM和CDH版本为5.15.0
2.环境准备
在本地测试环境中准备大量的小文件,这里Fayson直接将/opt/cloudera/parcels/CDH/lib目录直接put到HDFS上(因为lib下有大量的jar包)。
1.在put小文件到HDFS前,集群中的Block数量为30418
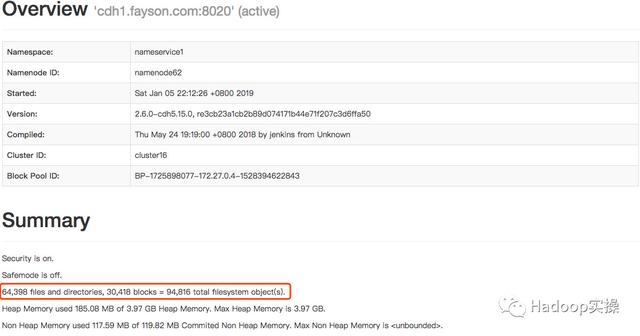
2.将/opt/cloudera/parcels/CDH/lib目录put到HDFS的/tmp目录下
[root@cd 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 5031
5031











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









