






前一篇文章 echo:python之数值计算加速(一)使用pybind11,用C为python写pyd,主要介绍了使用C给python写模块的一些基本知识,本篇主要借助一个例子,来看下用C来计算到底可以有多快。
在多因子处理的过程中,对于因子的行业中性计算是运算量比较大,在因子处理时会花费比较多时间的一个环节。本篇就用Z-score方法来对因子进行行业中性化计算为例子,来看看到底行业中性计算可以达到什么样的速度。
话不多说,先把C的计算代码框架拿出来,然后分析下行业中性化的运算结构。
1. 输入参数为两个,一个是原始因子矩阵,另一个是和因子矩阵相对应的行业代码矩阵。
2. 返回结果为和原因子矩阵大小一致的行业中性化后的矩阵。
3. 最外层循环是对行的循环,也就是对时间循环。
4. 内层首先对列循环分别计算相同行业的因子均值和标准差(这里需要用到均值和标准差的迭代公式)。
5. 最后再对列循环计算行业中性化后的因子值,并填入结果矩阵中。
按照上述逻辑编写代码
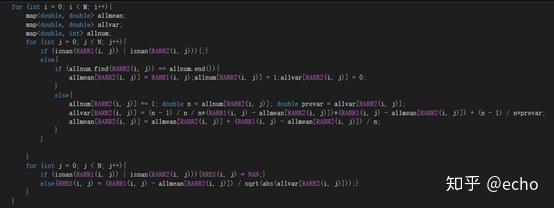
以上是函数的主体运算部分,为了放进一张图片里,调整了下代码结构,可读性不是太强,就是按照上述的逻辑来的,各位小伙伴应该也可以自行编写出来。
之后咱们就用前一篇文章讲的方法编译一把,在python里运行看看,
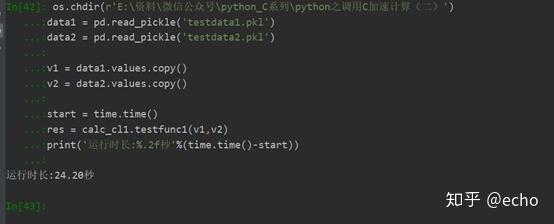
等了老半天才算出来,大概花了24秒的时间,其中计算的两个矩阵都是3071*4002,就是正常日频因子的矩阵大小。好吧这个也太慢了,我们需要改进一下,用一下C的多线程,毕竟我的小破电脑还是有四个核的,应该能提升下吧。
网上查看了几种稍微简便点的多线程计算的方法,发现最好用的还是openmp。
openmp的用法极其简单,就是在需要并行计算的for循环上加一句 #pragma omp parallel for,就会对for循环中的内容进行并行计算。
但是如果这个for循环中的结构相对复杂,而且for循环内部是有执行先后关系的,就需要用到另一个openmp的功能就是section,就是用section去包裹需要顺序执行的代码区域。
openmp还有一些其他的功能比如锁呀什么的,目前代码用不到,但是如果在并发的时候有可能对同一内存区域进行写入操作,必须要上锁,必须要上锁,必须要上锁!!!(重要的事情说三遍)如何上锁的问题,之后如果遇到会进行详细介绍,当前这个函数不涉及同时对一个内存区域操作的问题。
Emm…最后代码的样子大概是下面这个样子的。
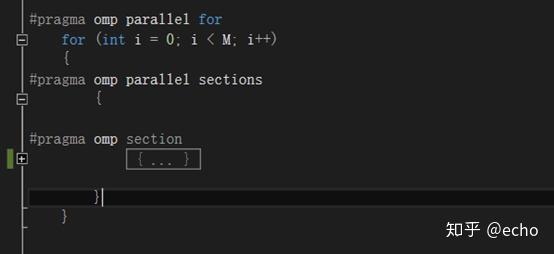
对之前的代码加上openmp并行之后,再进行编译,这个时候需要多加一个编译的参数,要开启openmp这个功能,编译代码变成如下的样子。
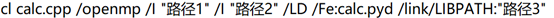
其中calc.cpp是待编译的cpp文件,路径1需要替换成前文获取到的pybind11-master文件夹下的include文件夹的所在路径,路径2需要替换成python安装路径的include文件夹的所在路径,路径3替换成python安装路径下的libs文件夹的所在路径,calc.pyd是生成的pyd名称,需要和cpp中模块名一致。多加了一个/openmp的参数。
然后重新编译cpp文件,在python中运行如下。
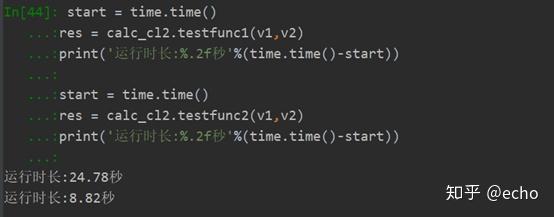
可以看到加openmp之后运行时间是不加的1/3。显著提高了运行速度,测试电脑是4核intel处理器,可以提高三倍左右的速度。一对比发现快了一些,但是9秒的速度还是太慢。
好吧接下来请出大杀器intel编译器,网上可以看到很多文章都说intel的编译器很牛逼,本人就去下载了一个来试试,下载方法可以自行百度,文末也会附上本人用的intel编译器。
本人使用的是Intel Parallel Studio XE 2019,设配的vs环境是vs2015。使用inetl编译器需要用icl命令,不过和cl命令差不太多。编译命令如下:
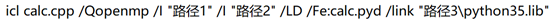
icl和cl命令的差别如下:
1. 开头的命令从cl变成icl。
2. 从/openmp变成/Qopenmp。
3. 从link/LIBPATH(原来只需要python的lib所在的路径) 变成了/link 对应python的lib(这里的lib视python环境而变,本文使用的是python35所以link的是python35.lib)。
用上述命令编译之后,在python执行代码如下:
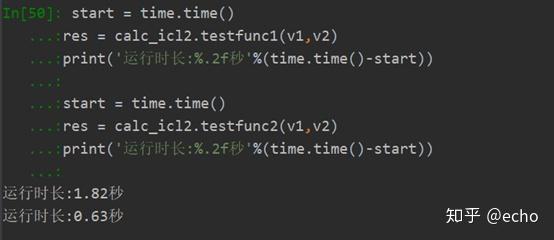
其中testfunc1是初始代码,testfunc2是加了openmp代码后的函数。可以看到速度直接起飞,之前的什么9秒都不香了。即使是未加任何优化的代码,intel编译器出来的文件执行速度也要远远高于vs编译器的速度。
以上就是用C给python写相应模块的实操过程,用到了openmp来进行并行计算,最后还用到了大杀器intel编译器,真的用这个编译器之后,其他的都不香了。
所以,小伙伴们你的行业中性计算需要多久呢?
关注【量化杂货铺】wx公众号,在后台回复【加速二】,就可以获得Intel Parallel Studio XE 2019。希望你们的计算速度也可以起飞。














 620
620











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









