





阅读本文需要xx分钟 ?
前言
目标检测(Intance Detection) 和图像分割(Image Segmantation) 算是深度学习中两个个比较热门的项目了,单级式检测(YOLO、SSD)和双级式检测(Fast R-Cnn)代表了如今大多数的目标检测方法,而FCN、U-net、Deeplab则引领了图像分割的潮流,为此,我们也应该知道如果去评价我们的检测准确度:
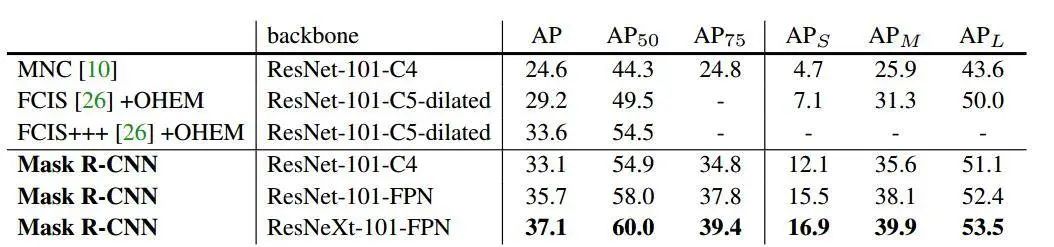
(在Mask R-Cnn论文中精度展示figure)
在目标检测的论文中,我们经常见到AP或者AR,这两个指标究竟代表什么?还有平时我们所说的Accuracy和Precision又代表什么?
那么这些标准究竟代表什么,有什么意义,光看上面的表可能是看不明白的,而网络中的评价标准大多解释的比较杂乱,为了方便之后的查阅,特地在此整理归纳,保证你看了就明白到底是个怎么样的评价标准,如有错误,欢迎拍砖~
评价标准
AP代表的是"Average Precision",代表平均精度,而AR代表的是"Average Recall",表示平均召回率。在coco数据集的官网中有对此的简单评价标准介绍:
目标检测和图像分割的评价标准是一样的,核心都是使用IOU标准,可以看之前的这篇进行补充:https://oldpan.me/archives/iu-iou-intersection-over-union-python
IOU(Intersection-Over-Union)
IOU即Intersection-Over-Union,IoU相当于两个区域重叠的部分除以两个区域的集合部分得出的结果,具体的可以在之前的这篇文章中了解到,这里就不赘述了。

目标检测和图像分割使用的IOU方法都是一样的,不同的是目标检测面向判断选定框和预测框;而图像分割面向的是选定掩码和预测掩码。
在目标检测中,检测目标用box进行评价。我们的IOU评价方式为(将预测框和选定框放入公式中去判定):

而在图像分割中,我们用掩码来进行评价,IOU评价方式为(将预测掩码和选定掩码放入公式汇中去判定):


Image credit
因为我们识别或者分割图像一般都有好几个类别,所以我们把每个分类得出的分数进行平均一下就可以得到mean IoU,也就是mIoU。
Pixel Accuracy
上面所述的IoU只是用于评价一幅图的标准,如果我们要评价一套算法,并不能只从一张图片的标准中得出结论。一般对于一个数据集、或者一个模型来说。评价的标准通常来说遍历所有图像中各种类型、各种大小(size)还有标准中设定阈值.论文中得出的结论数据,就是从这些规则中得出的。
在进行评价标准前,我们首先了解一下基本概念:
Precision(准确率):表示符合要求的正确识别物体的个数占总识别出的物体个数的百分数
Recall(召回率):表示符合要求正确识别物体的个数占测试集中物体的总个数的百分数
FP:false positive(误报),即预测错误(算法预测出一个不存在的物体)
FN:false negative(漏报),即没有预测到(算法没有在物体规定范围内预测出该物体)
TP: true positive(正确),既预测正确(算法在物体规定范围内预测出了该物体)
TN: true negative,算法预测出了此处是背景,也就是说此处没有任何物体,当然也没有mask。
如下图,我们设定阈值为0.5,也就是说,只要IoU得分大于0.5我们就算成功预测到物体,而低于该分数我们就规定为没有预测到物体。

那么什么是准确度(accuracy,ACC)?注意准确度和精确度(precision)是两码事,两者不可混为一谈,评价标准中,Pixel Accuracy表示检测物体的准确度,重点判断标准为是否检测到了物体,而Pixel Precision则代表检测到所有的物体中覆盖的精确度,重点判断mask是否精确地覆盖到了该物体。
而下方的公式是准确度公式,注意公式中的被除数和除数,TP代表检测出来并且正确的目标,而TN代表正确识别的背景(一般我们将背景也分为一类)。
Pixel Precision
而像素精度则是在已经检测到的基础上(不论检测是否失误)进行评测的标准:
其中,代表阈值,也就是最开始的和分别代表阈值是0.5和0.75。
上面是coco的评价标准,表示在所有检测出来的目标有多大的比率是正确的。而有些任务因为侧重不同所以公式也稍有变化。比如下面的公式,加入了FN,没有检测出来的实际物体也进行了计算。
 Image credit
Image credit
不论哪种方式,我们评价的时候尽可能顾全所有的阈值,所以一般使用的公式为:
这个时候,的取值范围一般是。也就是最开始coco标准中注明的情况。
也就是说,当阈值(Threshold)越高,评价标准就越严格,我们检测目标的IoU值必须足够高才能满足要求。
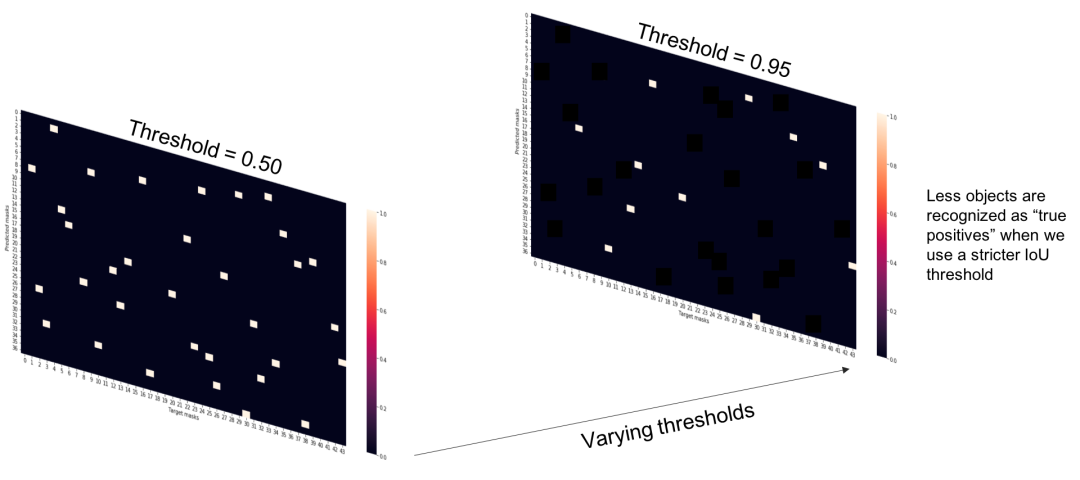 Image credit
Image credit
对于多分类的检测,只需要在公式最前面加上类别即可:
上面就是AP的基本公式,而AR的公式则如下:
召回率更强调是否能否检测到物体而不是检测到正确的物体。一般准确率和召回率不可能都很高,一方高另一方则会稍微低一些,如何trade-off这两个指标是目标检测和图像分割中经常考虑的问题。
参考文档:
https://www.jeremyjordan.me/evaluating-image-segmentation-models/ http://cocodataset.org/#detection-eval https://blog.csdn.net/u014734886/article/details/78831884
来者是客
如果你喜欢这里的内容
如果你觉得很有收获
如果你和我一样有着相似的想法
不妨留个言吧

- OpenVino初探(实际体验)
- 一个Tensor的生命历程(Pytorch版)-上篇
- 解密Deepfake(深度换脸)-基于自编码器的(Pytorch代码)换脸技术
- 利用TensorRT对深度学习进行加速
- (深度文)马尔科夫随机场(MRF)在图像处理中的应用-图像分割、纹理迁移
















 1775
1775











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









