





日常工作中果果经常要处理各种各样的数据。说到数据分析,Excel是不错的选择,毕竟Excel提供了很方便的交互式界面,数据过滤和可视化功能。基本上你能想到的功能,Excel都能提供。
但是问题在于,同样的数据可能每月每周甚至每天都会更新,比如说销售数据。每一次数据更新,意味着要手动做一系列事情:
导入到Excel里->调整格式->数据处理->画图->排版->分析->发给领导
这样的工作单次可能耗时不多,但是经常做、每天做,就有点让人抓狂了。
如何从机械式的工作中解脱出来呢,当然是使用python了!
下面果果给大家展示一张python绘制的图:
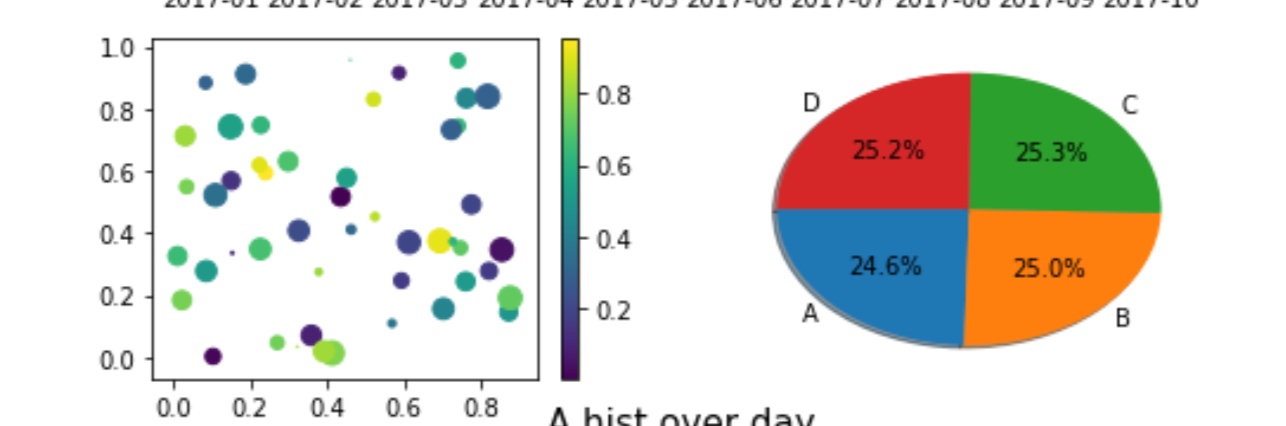
这是一张用python绘制的图,它有几个特点:
- 自动绘图:是导入数据后程序自动出的图;
- 自动排版:这是一张组合图,程序自动排版。对于单个子图来说,组图的信息更丰富,给人的感官带来很好的体验;
- 形式多样:包含各种常用的图,包括折现图,饼图,散点图,直方图等;
自从果果在工作中使用了python绘图之后,再也不用手动调数据画图了。只要新的数据来了,自动出一张大图。这样可以把更多的时间放在分析数据上。
这样一来,原来的工作流,就被简化成了:
自动出图->数据分析->发给领导
不仅省了很多力气,而且把时间和精力聚焦在了最重要的部分,也就是写数据分析报告。这块做的越好,领导越满意。
好了,说了这么多,下面就由小六六手把手教你怎么做这样一张大图。
Step1. 加载python中必要的库
import 这里使用了matplotlib绘图,使用pandas加载和处理数据。
Step2.读取数据
这里果果并没有使用真的数据,而是自己造了一组数,见下面代码
dates = pd.date_range('20170101', periods=300)
df = pd.DataFrame(np.random.rand(300,4), index=dates, columns=list('ABCD'))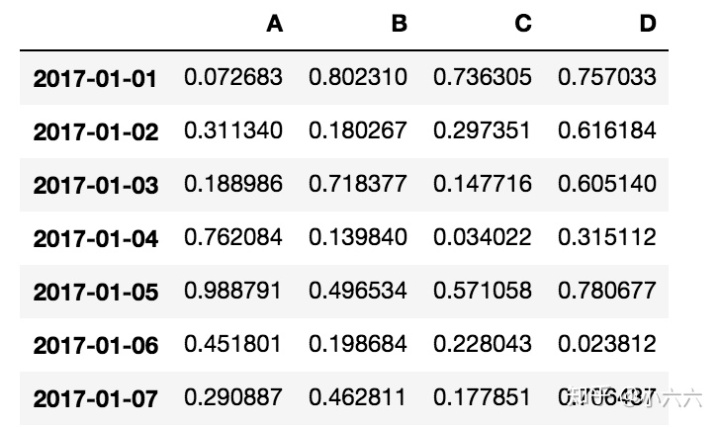
如上图所示,这里的A、B、C、D可以业务上有不同含义的数据,比如四种商品的点击量,出售数量等。
我们可以简单的把这组数据视为四种物品每天的出货量。
Step3.处理数据
这一部分就需要结合具体的业务了;一般来说业务数据的处理流程是固定的,因此这里写好之后就不用再改动了。当然,后续调整的话也很方便。
///按月份对商品数据求和
date_groupby = df.groupby(lambda x:pd.datetime.strftime(x,'%Y-%m')).apply(sum)
///统计四种商品的出货总量占比
date_sum = df.apply(sum)
date_ratio = date_sum/date_sum.sum()Step4.画图
处理好各种数据之后,就可以调用绘图工具画图啦。这里根据大家想要的呈现形式,调用matplotlib强大的功能,就可以自动生成各式各样的图。
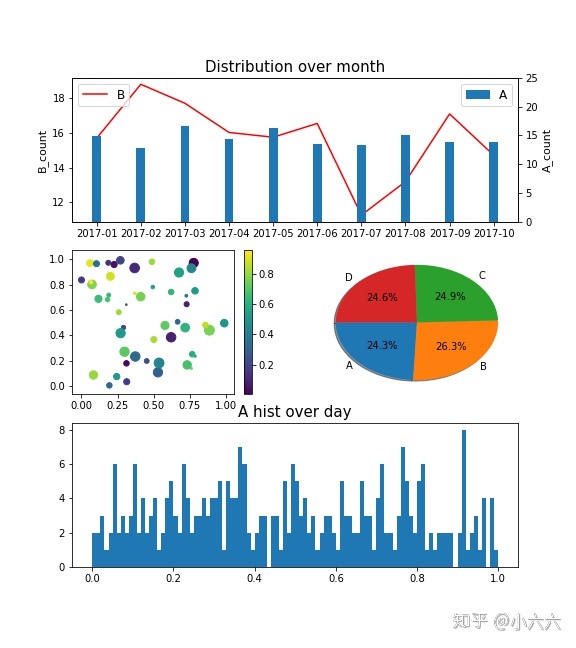
fig = plt.figure(figsize=(8,9))
ax_0 = fig.add_subplot(3, 1, 1 )
ax_0_twin = ax_0.twinx()
ax_0_twin.bar(date_groupby.index,date_groupby["A"],width = 0.2,label = "A")
plt.ylim((0, 25))
ax_0.plot(date_groupby.index,date_groupby["B"],color = "r", label = "B")
ax_0_twin.set_title(r'Distribution over month',fontsize=15)
ax_0.legend(loc=2, prop={'size': 12})
ax_0_twin.legend(loc=1, prop={'size': 12})
ax_0.set_ylabel(r'B_count',fontsize=11)
ax_0_twin.set_ylabel(r'A_count',fontsize=11)
ax_1 = fig.add_subplot(3, 2, 3 )
rng = np.random.RandomState(10)
colors = rng.rand(50)
sc = ax_1.scatter(df["A"].iloc[0:50],df["B"].iloc[0:50],
c=colors,s=100*df["C"].iloc[0:50])
plt.colorbar(sc)
ax_2 = fig.add_subplot(3, 2, 4 )
ax_2.pie(date_ratio,
labels=date_ratio.index , autopct = '%3.1f%%',
startangle = 180, shadow = True)
ax_3 = fig.add_subplot(3, 1, 3 )
ax_3.hist(df["A"],bins = 100)
ax_3.set_title(r'A hist over day',fontsize=15)最后看一眼生成的图:
用python绘图,解放双手,释放创造力!你学会了么?
文中相关的代码已经整理好,关注公众号 果果数据,回复 “画图” 即可获得下载链接。

其他文章:
小六六:使用Python做中文分词和绘制词云zhuanlan.zhihu.com

















 1143
1143











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









