






01 前言
做公众号,总是会需要使用一些图片做封面或背景。我的公众号的图片有两种来源:一是通过创可贴自己动手修改下就可以用了,还一种就是在网上下载图片。
那如何下载高清并且可以供使用(无版权)的图片了?我是使用的pexels网站下载来的图片(https://www.pexels.com/),这个网站图片高清,质量好,而且无版权,可以供免费使用。所以,本文教大家使用Python爬取Pexels图片,并保存在本地。
02 网站分析
首先,我们搜索Scenery,可以找到风景图。
https://www.pexels.com/search/Scenery/
该网站简单,不是异步加载,我们可以用lxml库来进行爬虫,其核心就是找到循环点。
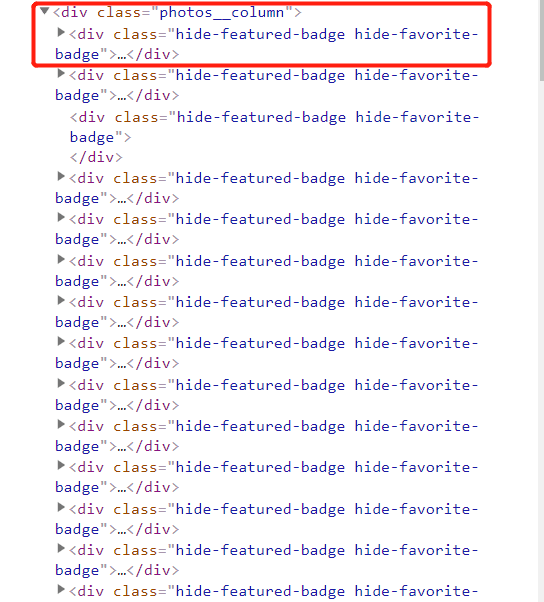
接着,我们考虑换页的url变换情况,我们按F12,打开开发者工具,查看url的变换情况。
我们发现,只需要换个page的页数即可。
https://www.pexels.com/search/Scenery/?page=
03 爬虫代码
import requests
from lxml import etree
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36'
}
path = '图片/'
urls = ['https://www.pexels.com/search/Scenery'+'/?page={}'.format(str(i)) for i in range(1,10)]
for url in urls:
res = requests.get(url, headers=headers)
html = etree.HTML(res.text)
infos = html.xpath('//div[@]/div')
for info in infos:
img = info.xpath('article/a[1]/img/@src')
if len(img) == 1:
img = img[0]
print(img)
data = requests.get(img, headers=headers)
f = open(path + img.split('?')[0][-11:], 'wb')
f.write(data.content)
f.close()

今天的分享就到这了,我们下期再见~















 7816
7816











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









