






导读
最近一直在看一些关于mysql innodb事务提交,innodb crash recovery,内部XA事务等资料,整理一下我对这块的一个初步理解。希望看完后能对大家理解mysql innodb事务提交过程,以及如何做crash recovery有个大概的了解
2PC
为了性能考虑,每次提交事务的时候,只需要将redo和undo落盘就代表事务已经持久化了,而不需要等待数据落盘。这样就已经能保证事务的crash时的前滚或者回滚(WAL)。由于undo的信息也会写入redo,所以其实我们只需要根据redo是否落盘而决定crash recovrey的时候是重做还是回滚。而上面提到,开启binlog后,还需要考虑binlog是否落盘(binlog牵扯到主从数据一致性,全备恢复的位点)。根据事务是否成功写binlog决定事务的重做还是回滚。
2PC即innodb对于事务的两阶段提交机制。当mysql开启binlog的时候,会存在一个内部XA的问题:事务在存储引擎层(redo)commit的顺序和在binlog中提交的顺序不一致的问题。
2PC原理
将事务的commit分为prepare和commit两个阶段:
1、prepare阶段:redo持久化到磁盘(redo group commit),并将回滚段置为prepared状态,此时binlog不做操作。

2、commit阶段:innodb释放锁,释放回滚段,设置提交状态,binlog持久化到磁盘,然后存储引擎层提交
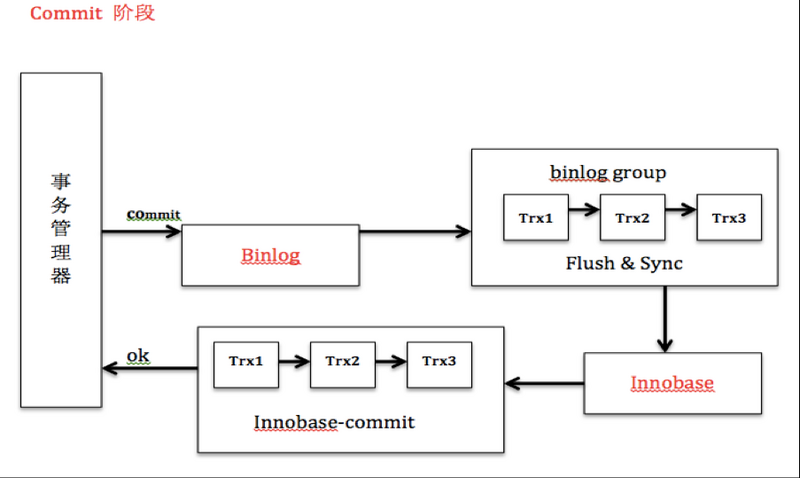
2PC保证了事务在引擎层(redo)和server层(binlog)之间的原子性。其中binlog作为XA协调器,即以binlog是否成功写入磁盘作为事务提交的标志(innodb commit标志并不是事务成功与否的标志)。所以在崩溃恢复中也是以redolog中的xid与binlog中的xid进行比较,如果xid在binlog中则提交,否则回滚。
Crash Recovery
Crash Recovery(no binlog)
由于未提交的事务和已回滚的事务也会记录到redo log中,因此在进行恢复的时候,这些事务要进行特殊的处理
innodb的处理策略是:进行恢复时,从checkpoint开始,重做所有事务(包括未提交的事务和已回滚的事务),然后通过undo log回滚那些未提交的事务
XA Crash Recovery
1、扫描最后一个 binlog,提取xid(标识binlog中的第几个event)
2、xid也会写到redo中,将redo中prepare状态的xid,去跟最后一个binlog中的xid比较 ,如果binlog中存在,则提交,否则回滚
为什么只扫描最后一个binlog?因为binlog rotate的时候会把前面的binlog都刷盘,而且事务是不会跨binlog的。
具体的,这个函数将最后一个 binlog 中完整写入的事务 XID 添加到一个 hash,这些 XID 标志着对应的事务已经完成。实现上,遍历并解析 binlog 文件中的每个 event,遇到 XID-event 时,将其中的 xid 提取出来并加入 hash。
接下来,通过 handler 接口中的 ha_recover 函数将这个 hash 传递给 InnoDB,以此告诉 InnoDB 哪些事务需要回滚。
在 InnoDB 拿到这个 hash 后,首先调用 innobase_xa_recover 函数得到 InnoDB 中处于 prepared 状态的 xid 集合,然后遍历其中每个 prepared 状态的事务,确定是否需要回滚
Group Commit
背景
我们知道,日志的写入基本上是顺序IO。WAL(Write-Ahead-Logging)用顺序的日志写入代替数据的随机IO实现事务持久化。但是尽管如此,每次事务提交都需要日志刷盘,仍然受限于磁盘IO。group commit的出现就是为了将日志(redo/binlog)刷盘的动作合并,从而提升IO性能
2PC机制只能解决单个事务的redo/binlog顺序一致的问题,如果并发怎么办呢(有可能存在一种情况:binlog提交顺序(T1,T2,T3),innodb commit顺序(T2,T3,T1))。
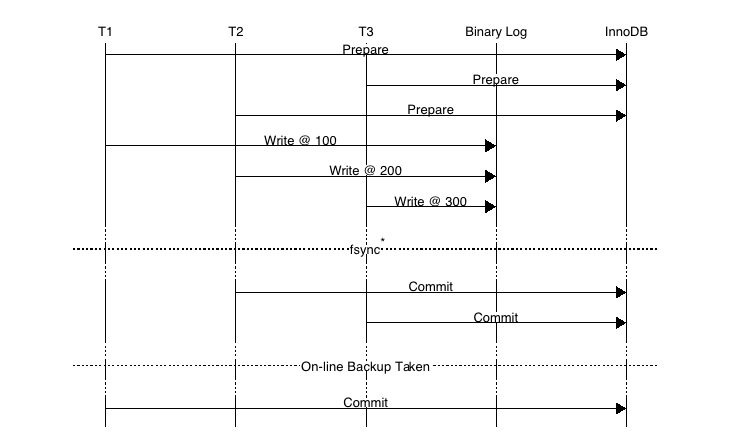
如上图,事务按照T1、T2、T3顺序开始执行,将二进制日志(按照T1、T2、T3顺序)写入日志文件系统缓冲,调用fsync()进行一次group commit将日志文件永久写入磁盘,但是存储引擎提交的顺序为T2、T3、T1。当T2、T3提交事务之后,若通过在线物理备份进行数据库恢复来建立复制时,因为在InnoDB存储引擎层会检测事务T3在上下两层都完成了事务提交,不需要在进行恢复了,此时主备数据不一致
事务提交顺序
MySQL 的内部 XA 机制保证了单个事务在 binlog 和 InnoDB 之间的原子性,接下来我们需要考虑,在多个事务并发执行的情况下,怎么保证在 binlog 和 redolog 中的顺序一致?
早期解决方法
**在 MySQL 5.6 版本之前,使用 prepare_commit_mutex 对整个 2PC 过程进行加锁,只有当上一个事务 commit 后释放锁,下个事务才可以进行 prepare 操作,这样完全串行化的执行保证了顺序一致。
存在的问题是,prepare_commit_mutex 的锁机制会严重影响高并发时的性能,在每个事务执行过程中, 都会至少调用 3 次刷盘操作(写 redolog,写 binlog,写 commit),多个小 IO 是非常低效的方式。

上图所示MySQL开启Binary log时使用prepare_commit_mutex和sync_log保证二进制日志和存储引擎顺序保持一致,prepare_commit_mutex的锁机制造成高并发提交事务的时候性能非常差而且二进制日志也无法group commit。
MySQL5.6 Group Commit
2PC中的prepare阶段,会对redo进行一次刷盘操作(innodb_flush_log_at_trx_commit=1),这时候redo group commit的过程如下:获取 log_mutex
若flushed_to_disk_lsn>=lsn,表示日志已经被刷盘,跳转5
若 current_flush_lsn>=lsn,表示日志正在刷盘中,跳转5后进入等待状态
将小于LSN的日志刷盘(flush and sync)
退出log_mutex
这个过程是根据LSN的顺序进行合并的,也就是说一次redo group commit的过程可能会讲别的未提交事务中的lsn也一并刷盘
为了提高并发性能,肯定要细化锁粒度。MySQL 5.6 引入了 binlog 的组提交(group commit)功能,prepare 阶段不变,只针对 commit 阶段,将 commit 阶段拆分为三个过程:flush stage:多个线程按进入的顺序将 binlog 从 cache 写入文件(不刷盘);
sync stage:对 binlog 文件做 fsync 操作(多个线程的 binlog 合并一次刷盘);
commit stage:各个线程按顺序做 InnoDB commit 操作。
其中,每个阶段有 lock 进行保护,因此保证了事务写入的顺序。
实现方法是,在每个 stage 设置一个队列,第一个进入该队列的线程会成为 leader,后续进入的线程会阻塞直至完成提交。leader 线程会领导队列中的所有线程执行该 stage 的任务,并带领所有 follower 进入到下一个 stage 去执行,当遇到下一个 stage 为非空队列时,leader 会变成 follower 注册到此队列中。
这种组提交的优势在于锁的粒度减小,三个阶段可以并发执行,从而提升效率。
MySQL5.7 Group Commit优化
MySQL 5.6 的组提交逻辑中,每个事务各自做 prepare 并写 redo log,只有到了 commit 阶段才进入组提交,因此每个事务的 redolog sync 操作成为性能瓶颈。
在 5.7 版本中,修改了组提交的 flush 阶段,在 prepare 阶段不再让线程各自执行 flush redolog 操作,而是推迟到组提交的 flush 阶段,flush stage 修改成如下逻辑:收集组提交队列,得到 leader 线程,其余 follower 线程进入阻塞;
leader 调用 ha_flush_logs 做一次 redo write/sync,即,一次将所有线程的 redolog 刷盘;
将队列中 thd 的所有 binlog cache 写到 binlog 文件中。
这个优化是将 redolog 的刷盘延迟到了 binlog group commit 的 flush stage 之中,sync binlog 之前。通过延迟写 redolog 的方式,为 redolog 做了一次组写入,这样 binlog 和 redolog 都进行了优化。
如何实现,很简单,因为log_sys->lsn始终保持了当前最大的lsn,只要我们刷redo刷到当前的log_sys->lsn,就一定能保证,将要刷binlog的事务redo日志一定已经落盘。通过延迟写redo方式,实现了redo log组提交的目的,而且减少了log_sys->mutex的竞争。目前这种策略已经被官方mysql5.7.6引入。
Binlog Group Commit
Binlog Group Commit的基本思想是引入队列机制,保证innodb commit的顺序与binlog落盘的顺序一致,并将事务分组,组内的binlog刷盘动作交给一个事务进行,实现组提交目的。队列中的第一个事务称为leader,其他事务称为follower。所有事情交给leader去做。过程分为三个阶段
Flush Stag
将每个事务的binlog写入内存
1) 持有Lock_log mutex [leader持有,follower等待]。
2) leader 调用 ha_flush_logs 做一次 redo write/sync,即,一次将所有线程的 redolog 刷盘
3) 获取队列中的一组binlog(队列中的所有事务)。
4) 将binlog buffer到I/O cache。
5) 通知dump线程dump binlog。
Sync Stage
将内存中的二进制日志刷新到磁盘,若队列中有多个事务,那么仅一次fsync操作就完成了二进制日志的写入,这就是BLGC。
1) 释放Lock_log mutex,持有Lock_sync mutex[leader持有,follower等待]。
2) 将一组binlog 落盘(sync动作,最耗时,假设sync_binlog为1)。
Commit Stage
leader根据顺序调用存储引擎层事务的提交,Innodb本身就支持group commit,因此修复了原先由于锁prepare_commit_mutex导致group commit失效的问题。
1) 释放Lock_sync mutex,持有Lock_commit mutex[leader持有,follower等待]。
2) 遍历队列中的事务,逐一进行innodb commit。
3) 释放Lock_commit mutex。
4) 唤醒队列中等待的线程。
change_stage 的流程是:线程先入队,在释放上一阶段的 lock,最后申请下一阶段的 lock。这样保证了每个时刻,每个 stage 都只有一个线程在执行,从而保证了线程的顺序性。反之,如果先释放上一个 stage lock,再申请入队,后面的线程就可能赶上来,同时申请入队,从而无法保证顺序性。
由于有多个队列,每个队列各自有mutex保护,队列之间是顺序的,约定进入队列的一个线程为leader,因此FLUSH阶段的leader可能是SYNC阶段的follower,但是follower永远是follower。
当有一组事务在进行commit阶段时,其他新事物可以进行Flush阶段,从而使group commit不断生效。group commit的效果由队列中事务的数量决定,若每次队列中仅有一个事务,那么可能效果和之前差不多,甚至会更差。但当提交的事务越多时,group commit的效果越明显,数据库性能的提升也就越大。
还有一点要说明:sync_binlog=1这个参数单位表示的是一组事务,而并非一个事务
参考资料















 1314
1314











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









