





背景
在MySQL高可用架构中,目前使用比较多的是Percona的PXC,Galera以及MySQL 5.7之后的MGR等,其他的还有的MHA,今天介绍另一个比较好用的MySQL高可用复制管理工具:Orchestrator(orch)。
Orchestrator
这是一款go编写的MySQL高可用性和复制拓扑管理工具,支持复制拓扑结构的调整,自动故障转移和手动主从切换等。后端数据库用MySQL或SQLite存储元数据,并提供Web界面展示MySQL复制的拓扑关系及状态,通过Web可更改MySQL实例的复制关系和部分配置信息,同时也提供命令行和api接口,方便运维管理。
相对比MHA来看最重要的是解决了管理节点的单点问题,其通过raft协议保证本身的高可用。GitHub的一部分管理也在用该工具进行管理。
Orchestrator大致的特点有:
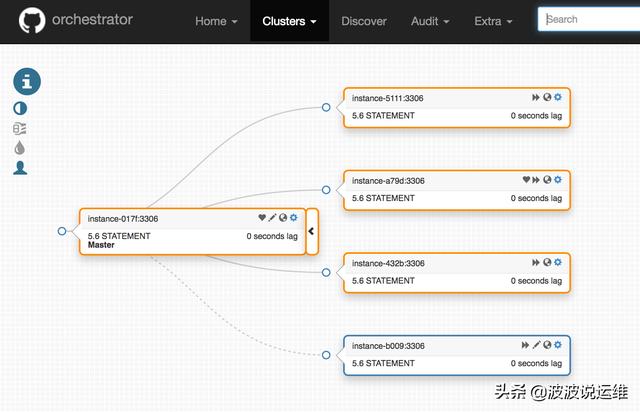
① 自动发现MySQL的复制拓扑,并且在web上展示。
② 重构复制关系,可以在web进行拖图来进行复制关系变更。
③ 检测主异常,并可以自动或手动恢复,通过Hooks进行自定义脚本。
④ 支持命令行和web界面管理复制。
安装
根据需要下载合适的包进行安装,下载好deb包后,需要安装jq的依赖包(apt-get install jq)。安装完成之后,相应的目录为:
/usr/local/orchestrator-rwxr-xr-x 1 root root 20M 1月 16 21:49 orchestrator-rw-r--r-- 1 root root 5.1K 1月 16 21:49 orchestrator-sample.conf.json-rw-r--r-- 1 root root 4.4K 1月 16 21:49 orchestrator-sample-sqlite.conf.jsondrwxr-xr-x 7 root root 4.0K 2月 15 19:03 resources- orchestrator:应用程序
- *.json:默认的配置模板
- resources:orchestrator相关的文件:client、web、伪GTID等相关文件。
配置
这里列出说明几个比较重要的参数:
- ListenAddress:web界面的http端口
- MySQLOrchestratorHost:orch后端数据库地址
- MySQLOrchestratorPort:orch后端数据库端口
- MySQLOrchestratorDatabase:orch后端数据库名
- MySQLOrchestratorUser:orch后端数据库用户名(明文)
- MySQLOrchestratorPassword:orch后端数据库密码(明文)
- MySQLOrchestratorCredentialsConfigFile:后端数据库用户名密码的配置文件「 "MySQLOrchestratorCredentialsConfigFile": "/etc/mysql/orchestrator-backend.cnf" 」,格式:
[client]user=orchestrator_srvpassword=${ORCHESTRATOR_PASSWORD}- 后端MySQL数据库的用户权限需要是:
CREATE USER 'orchestrator_srv'@'orc_host' IDENTIFIED BY 'orc_server_password';GRANT ALL ON orchestrator.* TO 'orchestrator_srv'@'orc_host';- MySQLTopologyUser:被管理的MySQL的用户(明文)
- MySQLTopologyPassword:被管理的MySQL的密码(密文)
- MySQLTopologyCredentialsConfigFile:被管理的MySQL的用户密码配置文件「"/etc/mysql/orchestrator-topology.cnf"」,格式:
[client]user=orchestrator_srvpassword=${ORCHESTRATOR_PASSWORD}- 被管理MySQL数据库的用户权限需要是:
CREATE USER 'orchestrator'@'orc_host' IDENTIFIED BY 'orc_topology_password';GRANT SUPER, PROCESS, REPLICATION SLAVE, REPLICATION CLIENT, RELOAD ON *.* TO 'orchestrator'@'orc_host';GRANT SELECT ON meta.* TO 'orchestrator'@'orc_host';GRANT SELECT ON ndbinfo.processes TO 'orchestrator'@'orc_host'; -- Only for NDB Cluster运行部署
1. 开启orchestrator
./orchestrator --debug --config=/etc/orchestrator.conf.json http2. 把配置好的复制实例加入到orchestrator,因为orch可以自动发现整个拓扑的所有实例,所以只需要添加任意一台实例即可,如果没有发现的话可以再添加。
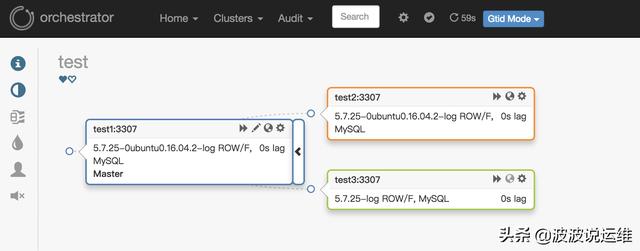
在web上添加(导航里的Clusters -> Discover):

添加完成之后,最终的结构图如下:
总结
限于篇幅的原因,今天先对orchestrator做个整体的介绍,后面会单独更新一下orch的部署教程及具体使用教程,感兴趣的朋友可以关注一下~
















 171
171











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









