





【51CTO.com原创稿件】最近的一个项目是风控过程数据实时统计分析和聚合的一个 OLAP 分析监控平台,日流量峰值在 10 到 12 亿上下,每年数据约 4000 亿条,占用空间大概 200T。

面对这样一个数据量级的需求,我们的数据如何存储和实现实时查询将是一个严峻的挑战。
经过对 Elasticsearch 多方调研和超过几百亿条数据的插入和聚合查询的验证之后,我们总结出以下几种能够有效提升性能和解决这一问题的方案:
- 集群规划
- 存储策略
- 索引拆分
- 压缩
- 冷热分区等
本文所使用的 Elasticsearch 版本为 5.3.3。

什么是时序索引?其主要特点体现在如下两个方面:
- 存,以时间为轴,数据只有增加,没有变更,并且必须包含 timestamp(日期时间,名称随意)字段。
其作用和意义要大于数据的 id 字段,常见的数据比如我们通常要记录的操作日志、用户行为日志、或股市行情数据、服务器 CPU、内存、网络的使用率等。
- 取,一定是以时间范围为第一过滤条件,然后是其他查询条件,比如近一天、一周、本月等等,然后在这个范围内进行二次过滤。
比如性别或地域等,查询结果中比较关注的是每条数据和 timestamp 字段具体发生的时间点,而非 id。
此类数据一般用于 OLAP、监控分析等场景。
集群部署规划
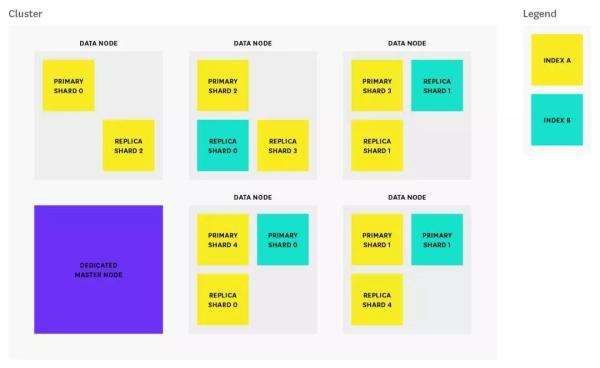
我们都知道在 Elasticsearch(下称 ES)集群中有两个主要角色:Master Node 和 Data Node,其他如 Tribe Node 等节点可根据业务需要另行设立。
为了让集群有更好的性能表现,我们应该对这两个角色有一个更好的规划,在 Nodes 之间做读取分离,保证集群的稳定性和快速响应,在大规模的数据存储和查询的压力之下能够坦然面对,各自愉快的协作。
Master Nodes
Master Node,整个集群的管理者,负有对 index 的管理、shards 的分配,以及整个集群拓扑信息的管理等功能。
众所周知,Master Node 可以通过 Data Node 兼任,但是,如果对群集规模和稳定要求很高的话,就要职责分离,Master Node 推荐独立,它的状态关乎整个集群的存活。
Master 的配置:
node.master: true node.data: false node.ingest: false 这样 Master 不参与 I、O,从数据的搜索和索引操作中解脱出来,专门负责集群的管理工作,因此 Master Node 的节点配置可以相对低一些。
另外防止 ES 集群 split brain(脑裂),合理配置 discovery.zen.minimum_master_nodes 参数,官方推荐 master-eligible nodes / 2 + 1 向下取整的个数。
这个参数决定选举 Master 的 Node 个数,太小容易发生“脑裂”,可能会出现多个 Master,太大 Master 将无法选举。
更多 Master 选举相关内容请参考:
https://www.elastic.co/guide/en/elasticsearch/reference/5.3/modules-discovery-zen.html#master-election Data Nodes
Data Node 是数据的承载者,对索引的数据存储、查询、聚合等操作提供支持。
这些操作严重消耗系统的 CPU、内存、IO 等资源,因此,应该把最好的资源分配给 Data Node,因为它们是真正干累活的角色,同样 Data Node 也不兼任 Master 的功能。
Data 的配置:
node.master: false node.data: true node.ingest: false Coordinating Only Nodes
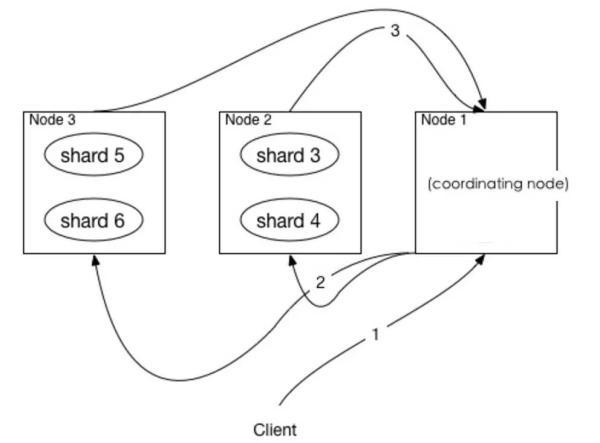
ES 本身是一个分布式的计算集群,每个 Node 都可以响应用户的请求,包括 Master Node、Data Node,它们都有完整的 Cluster State 信息。
正如我们知道的一样,在某个 Node 收到用户请求的时候,会将请求转发到集群中所有索引相关的 Node 上,之后将每个 Node 的计算结果合并后返回给请求方。
我们暂且将这个 Node 称为查询节点,整个过程跟分布式数据库原理类似。那问题来了,这个查询节点如果在并发和数据量比较大的情况下,由于数据的聚合可能会让内存和网络出现瓶颈。
因此,在职责分离指导思想的前提下,这些操作我们也应该从这些角色中剥离出来,官方称它是 Coordinating Nodes,只负责路由用户的请求,包括读、写等操作,对内存、网络和 CPU 要求比较高。
本质上,Coordinating Only Nodes 可以笼统的理解为是一个负载均衡器,或者反向代理,只负责读,本身不写数据,它的配置是:
node.master: false node.data: false node.ingest: false search.remote.connect: false 增加 Coordinating Nodes 的数量可以提高 API 请求响应的性能,我们也可以针对不同量级的 Index 分配独立的 Coordinating Nodes 来满足请求性能。
那是不是越多越好呢?在一定范围内是肯定的,但凡事有个度,过了负作用就会突显,太多的话会给集群增加负担。
在做 Master 选举的时候会先确保所有 Node 的 Cluster State 是一致的,同步的时候会等待每个 Node 的 Acknowledgement 确认,所以适量分配可以让集群畅快的工作。
search.remote.connect 是禁用跨集群查询,防止在进行集群之间查询时发生二次路由:
https://www.elastic.co/guide/en/elasticsearch/reference/current/modules-cross-cluster-search.html Routing
类似于分布式数据库中的分片原则,将符合规则的数据存储到同一分片。ES 通过哈希算法来决定数据存储于哪个 Shard:
shard_num = hash(_routing) % num_primary_shards 其中 hash(_routing) 得出一个数字,然后除以主 Shards 的数量得到一个余数,余数的范围是 0 到 number_of_primary_shards - 1,这个数字就是文档所在的 Shard。
Routing 默认是 id 值,当然可以自定义,合理指定 Routing 能够大幅提升查询效率,Routing 支持 GET、Delete、Update、Post、Put 等操作。
如:
PUT my_index/my_type/1?routing=user1 { "title": "This is a document" } GET my_index/my_type/1?routing=user1 不指定 Routing 的查询过程:

简单的来说,一个查询请求过来以后会查询每个 Shard,然后做结果聚合,总的时间大概就是所有 Shard 查询所消耗的时间之和。
指定 Routing 以后:
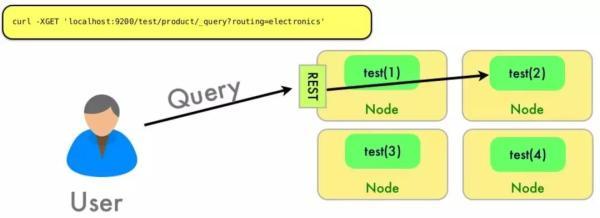
会根据 Routing 查询特定的一个或多个 Shard,这样就大大减少了查询时间,提高了查询效率。
当然,如何设置 Routing 是一个难点,需要一点技巧,要根据业务特点合理组合 Routing 的值,来划分 Shard 的存储,最终保持数据量相对均衡。
可以组合几个维度做为 Routing ,有点类似于 Hbase Key,例如不同的业务线加不同的类别,不同的城市和不同的类型等等,如:
- _search?routing=beijing:按城市。
- _search?routing=beijing_user123:按城市和用户。
- _search?routing=beijing_android,shanghai_android:按城市和手机类型等。
数据不均衡?假如你的业务在北京、上海的数据远远大于其他二三线城市的数据。
再例如我们的业务场景,A 业务线的数据量级远远大于 B 业务线,有时候很难通过 Routing 指定一个值保证数据在所有 Shards 上均匀分布,会让部分 Shard 变的越来越大,影响查询性能,怎么办?
一种解决办法是单独为这些数据量大的渠道创建独立的 Index,如:
http://localhost:9200/shanghai,beijing,other/_search?routing=android 这样可以根据需要在不同 Index 之间查询,然而每个 Index 中 Shards 的数据可以做到相对均衡。
另一种办法是指定 Index 参数 index.routing_partition_size,来解决最终可能产生群集不均衡的问题,指定这个参数后新的算法如下:
shard_num = (hash(_routing) + hash(_id) % routing_partition_size) % num_primary_shards index.routing_partition_size 应具有大于 1 且小于 index.number_of_shards 的值。
最终数据会在 routing_partition_size 几个 Shard 上均匀存储,是哪个 Shard 取决于 hash(_id) % routing_partition_size 的计算结果。
指定参数 index.routing_partition_size 后,索引中的 Mappings 必须指定 _routing 为 "required": true,另外 Mappings 不支持 parent-child 父子关系。
很多情况下,指定 Routing 后会大幅提升查询性能,毕竟查询的 Shard 只有那么几个,但是如何设置 Routing 是个难题,可根据业务特性巧妙组合。
索引拆分
Index 通过横向扩展 Shards 实现分布式存储,这样可以解决 Index 大数据存储的问题。
但在一个 Index 变的越来越大,单个 Shard 也越来越大,查询和存储的速度也越来越慢。
更重要的是一个 Index 其实是有存储上限的(除非你设置足够多的 Shards 和机器),如官方声明单个 Shard 的文档数不能超过 20 亿(受限于 Lucene index,每个 Shard 是一个 Lucene index)。
考虑到 I、O,针对 Index 每个 Node 的 Shards 数最好不超过 3 个,那面对这样一个庞大的 Index,我们是采用更多的 Shards,还是更多的 Index,我们如何选择?
Index 的 Shards 总量也不宜太多,更多的 Shards 会带来更多的 I、O 开销,其实答案就已经很明确,除非你能接受长时间的查询等待。
Index 拆分的思路很简单,时序索引有一个好处就是只有增加,没有变更,按时间累积,天然对索引的拆分友好支持,可以按照时间和数据量做任意时间段的拆分。
ES 提供的 Rollover Api + Index Template 可以非常便捷和友好的实现 Index 的拆分工作,把单个 index docs 数量控制在百亿内,也就是一个 Index 默认 5 个 Shards 左右即可,保证查询的即时响应。
简单介绍一下 Rollover API 和 Index Template 这两个东西,如何实现 index 的拆分。
Index Template
我们知道 ES 可以为同一目的或同一类索引创建一个 Index Template,之后创建的索引只要符合匹配规则就会套用这个 Template,不必每次指定 Settings 和 Mappings 等属性。
一个 Index 可以被多个 Template 匹配,那 Settings 和 Mappings 就是多个 Template 合并后的结果。
有冲突通过 Template 的属性"order" : 0 从低到高覆盖(这部分据说会在 ES6 中会做调整,更好的解决 Template 匹配冲突问题)。
示例:
PUT _template/template_1 { "index_patterns" : ["log-*"], "order" : 0, "settings" : { "number_of_shards" : 5 }, "aliases" : { "alias1" : {} } } Rollover Index

Rollover Index 可以将现有的索引通过一定的规则,如数据量和时间,索引的命名必须是 logs-000001 这种格式,并指定 aliases,示例:
PUT /logs-000001 { "aliases": { "logs_write": {} } } # Add > 1000 documents to logs-000001 POST /logs_write/_rollover { "conditions": { "max_age": "7d














 2780
2780











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









