






Boston Housing数据集包含有关波士顿不同房屋的信息。该机器学习数据集中有506个样本和13个特征变量。目标是使用给定的特征预测房屋价格的价值。我们将从scikit-learn本身导入这个机器学习数据集。
让我们从导入一些Python库开始。
import numpy as npimport pandas as pd#Visualization Librariesimport seaborn as snsimport matplotlib.pyplot as plt#To plot the graph embedded in the notebook%matplotlib inline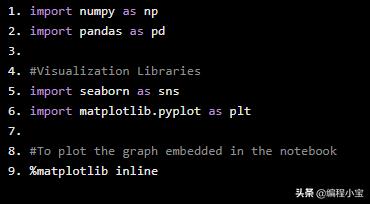
现在我们需要从sklearn导入模块
#imports from sklearn libraryfrom sklearn import datasetsfrom sklearn.linear_model import LinearRegressionfrom sklearn.model_selection import train_test_split, cross_val_scorefrom sklearn.metrics import mean_squared_error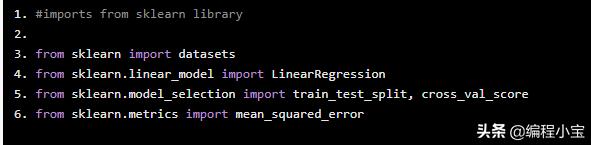
从sklearn导入机器学习数据集
#loading the dataset direclty from sklearnboston = datasets.load_boston()
sklearn返回类似字典的对象,属性是:' data ',要学习的数据,' target ',回归目标,' DESCR ',数据集的完整描述,' filename',波士顿的物理位置csv数据集。我们可以从以下操作中获得。
print(type(boston))print('')print(boston.keys())print('')print(boston.data.shape)print('')print(boston.feature_names)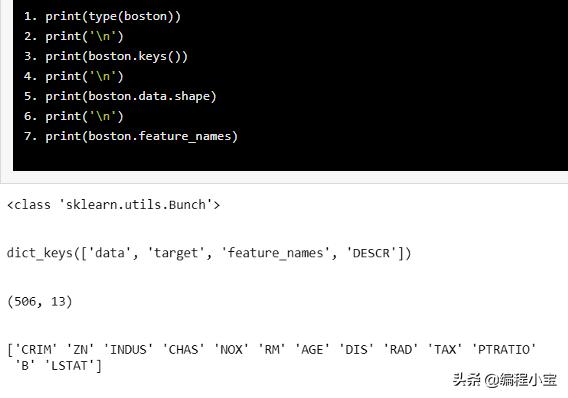
如上所述,有4个键值['data','target','feature_names','DESCR']。数据有506行和13个特征变量。请注意,这不包括目标变量。此外,还提取列的名称。使用boston.DESCR` 可以看到有关机器学习数据集的特征和更多的详细信息
print(boston.DESCR)
机器学习数据集的描述
在应用任何EDA或机器学习模型之前,我们必须将其转换为panda dataframe,这可以通过调用boston.data上的dataframe来实现。我们还将目标变量从boston.target添加到dataframe,Python代码如下:
bos = pd.DataFrame(boston.data,  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 3791
3791











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









