





前篇文章(https://zhuanlan.zhihu.com/p/81850840/)讲了进程地址空间的分配,那本文会继续讲物理内存如何管理,何时分配等问题。
物理内存meta管理
涉及到物理内存的分配、释放,必然有一个数据结构对其进行管理,同时也要考虑到性能、效率、安全性等方面的问题。
前文讲了,linux管理内存大小的粒度是4K,我们叫做page。在单cpu的机器上,一般采用平台内存模型(flat memroy model),就是将page平铺开供cpu使用,但是在多cpu的情况下,就会出现对page的相互竞争、抢占的情况,导致效率低,所以本文讲NUMA(non-uniform memory access)架构下,非一致性内存访问。
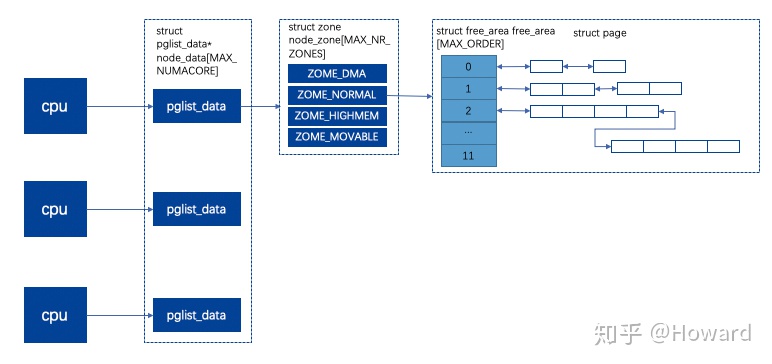
pglist_data:numa中一个cpu对应指定的内存节点,重要的字段如下:
- mem_map数组:包含了该node上所有的struct page,包括已分配、未分配的,也用于物理页号映射。
- node_zones数组:存储该节点所有的zone。
- node_zonelist数组:存储其他节点的zone,numa架构下,当前cpu的pglist_data -> mem_map的page用完后,可以通过该数组申请其他cpu的内存。
node_zone:存储该节点的区域,用区域来区分不同的物理内存。
- 三种类型的zone:
- ZONE_DMA:DMA方式可以操作的内存区域;
- ZONE_NORMAL:普通的映射区;
- ZONE_HIGHMEM:高端内存映射的区域。
- free_area:空闲page的数组 + 链表的结构,伙伴系统依靠该数据结构来分配物理内存。每个数组的item都是一个链表,链表中的每个item就是待分配的单元,其大小为2的n次方个页,n为数组下标。MAX_ORDER = 11,一次可以分配2的11次方个页,即M内存。
page:用于表示一个4k页面的meta信息,如果内存为4G,则有1M个page,如果page占用空间太大,则用户实际可使用的内存就会变少,而page的使用方式有多种,需要meta记录下来,所以内部大量使用union,page目前实际大小为32byte,就是4G的内存,需要使用32M来保存meta信息。以下是page使用方式:
- 整页模式:分配内存的单位就是页,包括匿名映射和文件映射,其重要的字段如下:
- struct address_space *mapping:指向映射到该page内容的源地址空间,可能是文件、可能是进程地址空间。
- mapping == 0,说明是swap的页面,其指向swapper_space的地址。
- 如果mapping != 0,第0位bit[0] = 0,说明该page属文件映射,mapping指向文件的地址空间address_space,此时pgoff_t index则是address_space指向的radix tree的页号。(可参见文件系统:https://zhuanlan.zhihu.com/p/61123802)
- 如果mapping != 0,第0位bit[0] != 0,说明该page为匿名映射,mapping指向vm_area_struct -> anon_vma对象。
- _mapcount:被页表引用的次数。
- lru:如果page还未被分配,则处于伙伴系统,lru将其连接在相同阶的free_area上。如果已经分配,则连接到zone中,供回收时使用。
- struct address_space *mapping:指向映射到该page内容的源地址空间,可能是文件、可能是进程地址空间。
- slab模式:类似于对象池,将一页分配多个slot,每次分配的单位就是对象大小的内存,基本会小于4k,所以一般1个页可以包含多个对象。
- s_mem:指向正在使用的slab的第一个对象。
- freelist:池子中可分配的空闲对象。
- rcu_head:需要释放对象的列表。
- lru:指向slab的管理结构。
更详细struct page的介绍,可以参考《深入理解Linux内核》296页。
伙伴系统 (Buddy system)
依据pgdata_list -> zone -> free_area,分配物理内存,返回struct page链表,其算法如下:
1)将分配空间大小归一化,2^n-1 < X < 2^n,此时从free_area[n]开始查找,若有,则直接返回。
2)若free_area[n]无法找到,则在n ~ MAX_ORDER 之间遍历,若有,则将内存页一拆为二,一部分用于分配,分配有剩余且大于4k,则寻找free_area挂上去,另一部分挂在上一阶的空闲链表上。
3)如果当前zone -> free_area不ok,则遍历node_zonelists中的其他zone。
如现在需要分配1个页,free_area[0],free_area[1]都为空,从free_area[2]上取出一个单元(order = 2时,分配item = 4 page),在分配需要使用的1个页后,剩下的3页中,1个页挂在free_area[0],2个页作为一个单元挂在free_area[1]上。
其函数调用链:alloc_pages(gfp_t gfp_mask, unsigned int order) -> alloc_pages_current -> __alloc_pages_nodemask。
gfp_t的枚举值:GPF_USER、GPF_KERNAL、GPF_HIGHMEM,分别对应ZONE_NORMAL、ZONE_NORMAL、ZONE_HIGHMEM的空间。
页表
前面讲了进程地址空间,本文前面说了物理内存的分配,那进程地址空间如何和物理内存对应呢?就是linux的页表机制。
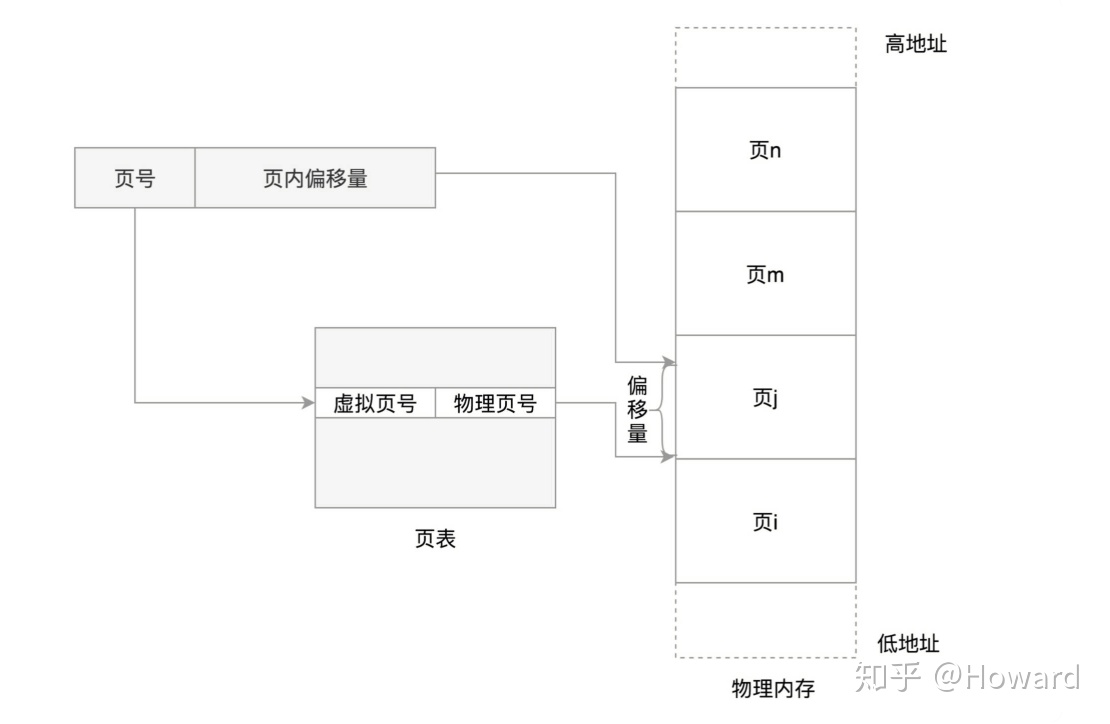
段地址 + 段偏移 = 逻辑地址,然后将逻辑地址拆解为页号(20位) + 页内偏移(12位)。页表维护虚拟页号和物理页号的映射。
对于32位的系统,支持最大物理寻址空间为4g。1 page为4k,4g的空间需要1m个page。由于是32位,每个page需要32位,即4个字节来索引,所以4g空间需要4m的页表。由于逻辑地址是按进程隔离的,所以进程之间的逻辑地址可能重合,但都映射了不同的物理地址,所以页表也需要按进程隔离。如果有机器上有1000个进程,则页表就会占用1000 * 4m = 4g的页表空间,32位系统的内存就撑满了。
为节省内存空间,对页表进行分级: 4g空间需要4m的页表,那这4m的页表需要1k个页表(4k的空间)来描述,具体如下图:
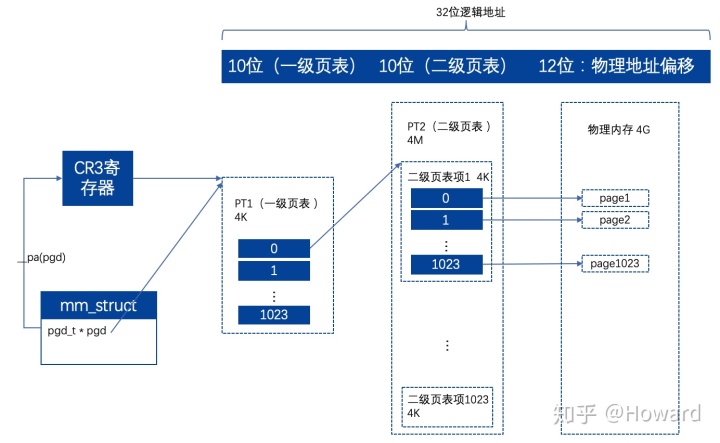
有人会说新增了一级页表,那不就从4m -> 4m + 4k了吗?比原来更大了。但是大部分情况,1个进程是不会用到4g的地址空间的,对于没有用到的地址空间,只要1级页表缺失4byte,2级页表就可以省下4k。
页表是有Linux按照x86规范构造的,并将一级页表的指针通过宏__pa()转换为物理地址,并加载到cr3寄存器(这也是x86体系规范),这个过程就是在context_switch -> switch_mm中发生的。
逻辑地址 -> 物理地址的具体转换过程由硬件完成,比如执行mov指令时(见前文开头https://zhuanlan.zhihu.com/p/81850840/),其传入的是逻辑地址,硬件访问时会转换为物理地址访问,并取出对应的值,这个模块叫MMU(memory mangerment unit)。
缺页中断
何时分配的物理内存呢?是不是上层只要调用brk、mmap就分配呢?显然不是的,上文讲brk、mmap时并没有将分配物理内存。实际的物理内存是在进程访问时,发现页表项为空会触发缺页异常,在缺页异常处理程序中分配内存。缺页异常的注册中断门代码如下:
set_intr_gate(14,&page_fault);其调用链路是:do_page_fault -> handle_mm_fault -> handle_pte_fault,其中handle_mm_fault主要是创建或找到页表项pte,handle_pte_fault是完成物理页的分配,并将物理页号记录到页表项pte中。主要代码如下:
do_page_fault(struct pt_regs *regs, unsigned long error_code)
{
unsigned long address = read_cr2(); // 缺页中断发生的线性地址通过cr2寄存器传递
......
__do_page_fault(regs, error_code, address);
......
}
/*
* This routine handles page faults. It determines the address,
* and the problem, and then passes it off to one of the appropriate
* routines.
*/
static noinline void
__do_page_fault(struct pt_regs *regs, unsigned long error_code,
unsigned long address)
{
// 判断是否在内核态,如果是则调用内核的分配函数
if (unlikely(fault_in_kernel_space(address))) {
if (vmalloc_fault(address) >= 0)
return;
}
...... // 找到缺页中断发生的线性地址描述符
vma = find_vma(mm, address);
......
fault = handle_mm_fault(vma, address, flags);
......
/*
* 根据线性地址完成页表的查询或分配,此处代码是支持64位os的,所以是4层页表,比
* 前面分析32位的页表多2层
*/
static int __handle_mm_fault(struct vm_area_struct *vma, unsigned long address,
unsigned int flags)
{
struct vm_fault vmf = {
.vma = vma,
.address = address & PAGE_MASK,
.flags = flags,
.pgoff = linear_page_index(vma, address),
.gfp_mask = __get_fault_gfp_mask(vma),
};
struct mm_struct *mm = vma->vm_mm;
pgd_t *pgd;
p4d_t *p4d;
int ret;
// 寻找或分配页表项
// 全局页表
pgd = pgd_offset(mm, address);
p4d = p4d_alloc(mm, pgd, address);
...... // 上层页表
vmf.pud = pud_alloc(mm, p4d, address);
...... // 中间层页表
vmf.pmd = pmd_alloc(mm, vmf.pud, address);
......
return handle_pte_fault(&vmf);
}handle_pte_fault会完成真是物理页的分配和pte页表项的填充。
1)如果vmf -> pte为null,说明没有分配,如果是匿名映射,直接调用do_anonymous_page分配。如果是文件映射,则调用do_fault进行分配,此处涉及到vfs(虚拟文件系统的操作,请参考https://zhuanlan.zhihu.com/p/61123802)
2)如果vmf -> pte存在且不在内存中,说明是swap到硬盘了,通过do_swap_page swap in就ok了。
static int handle_pte_fault(struct vm_fault *vmf)
{
pte_t entry;
......
vmf->pte = pte_offset_map(vmf->pmd, vmf->address);
vmf->orig_pte = *vmf->pte;
......
if (!vmf->pte) {
if (vma_is_anonymous(vmf->vma))
return do_anonymous_page(vmf);
else
return do_fault(vmf);
}
if (!pte_present(vmf->orig_pte))
return do_swap_page(vmf);
......
}do_anonymous_page:
1)pte_alloc:分配页表项。
2)alloc_zeroed_user_highpage_movable:分配一个页,此处最终调用到伙伴系统的__alloc_pages_nodemask,然后返回一个struct page。
3)mk_pte:struct page转换为物理页号,并保存在pte页表项中,这是映射物理内存的关键,
static int do_anonymous_page(struct vm_fault *vmf)
{
struct vm_area_struct *vma = vmf->vma;
struct mem_cgroup *memcg;
struct page *page;
int ret = 0;
pte_t entry;
......
if (pte_alloc(vma->vm_mm, vmf->pmd, vmf->address))
return VM_FAULT_OOM;
......
page = alloc_zeroed_user_highpage_movable(vma, vmf->address);
......
entry = mk_pte(page, vma->vm_page_prot);
if (vma->vm_flags & VM_WRITE)
entry = pte_mkwrite(pte_mkdirty(entry));
vmf->pte = pte_offset_map_lock(vma->vm_mm, vmf->pmd, vmf->address,
&vmf->ptl);
......
set_pte_at(vma->vm_mm, vmf->address, vmf->pte, entry);
......
}
#define mk_pte(page, pgprot) pfn_pte(page_to_pfn(page), (pgprot))
#define page_to_pfn(page) ((unsigned long) (page - vmem_map))
static inline pte_t pfn_pte(unsigned long page_nr, pgprot_t pgprot)
{
phys_addr_t pfn = (phys_addr_t)page_nr << PAGE_SHIFT;
pfn ^= protnone_mask(pgprot_val(pgprot));
pfn &= PTE_PFN_MASK;
return __pte(pfn | check_pgprot(pgprot));
}page_to_pfn:获取物理页号的函数。page实例是前面伙伴系统分配的,同时该page实例存储在pglist_data -> mem_map中,page - vmem_map,结构体直接想减,得到的是两个地址之间可以有多少个减数大小的对象,此处就表示该page是mem_map中的index,这就是物理页号。pte结构就是一个long,将该物理页号和一些控制信息按x86要求记录就好。
很多人这里可能会困惑,物理页号是啥?和硬件相关吗?其实硬件没有物理页号这个概念。只是这个struct page就占用了这个物理页号,其他的page不能使用。当访问物理内存时,真实的物理地址 = 物理页号 * 4k。而释放内存,只需要释放这个pte和page即可,下次再次分配该page时,将物理地址上的内存空间覆盖就好。















 169
169











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









