







论文标题:RT-Trajectory: Robotic Task Generalization via Hindsight Trajectory Sketches
论文作者:Isabel Leal, Krzysztof Choromanski, Deepali Jain, Avinava Dubey, Jake Varley, Michael Ryoo, Yao Lu, Frederick Liu, Vikas Sindhwani, Quan Vuong, Tamas Sarlos, Ken Oslund, Karol Hausman, Kanishka Rao
作者单位:Google DeepMind, University of California San Diego, Stanford University, Intrinsic
Intrinsic
论文原文:https://arxiv.org/abs/2311.01977
论文出处:–
论文被引:–(01/05/2024)
项目主页:https://rt-trajectory.github.io/
论文代码:–
Abstract
泛化(Generalization)仍然是强大的机器人学习系统最重要的需求之一。虽然最近提出的方法在泛化到新物体,语义概念或视觉分布变化方面显示出前景,但泛化到新任务仍然具有挑战性。例如,即使折叠任务(folding task)的机械臂轨迹与拾放任务(pick-and-place task)相似,在拾放任务中训练出来的语言条件策略也无法推广到折叠任务中。如果我们通过粗略的轨迹草图(trajectory sketches)来表示任务,这种泛化就会变得可行。我们提出了一种使用这种粗略轨迹草图的策略调节方法,我们称之为 RT-Trajectory,这是实用的,易于指定的,并且可以让策略有效地执行原本难以执行的新任务。轨迹草图既要足够详细以表达以运动为中心的低层次指导,又要足够粗略以允许学习策略在上下文视觉观察的背景下解释轨迹草图,两者之间取得了平衡。此外,我们还展示了轨迹草图如何为与机器人策略交流提供有用的接口——可以通过简单的人工输入(如草图或视频)或自动方法(如现代图像生成或航点生成方法)来指定轨迹草图。在各种真实世界的机器人任务中对 RT 轨迹进行了大规模评估,发现在提供相同训练数据的情况下,与语言条件策略和目标条件策略相比,RT 轨迹能够执行更广泛的任务。
Summary
研究背景
追求通用机器人策略一直是机器人领域的一项长期挑战。目标是设计出不仅在已知任务中表现出色,而且还能泛化到训练数据集中没有体现的新物体,新场景和新行动的策略。在这项工作中,重点放在策略学习方面,正如在实验中展示的那样,策略学习会对其泛化能力产生巨大影响:任务规范和策略调节。
任务规范的传统方法包括单样本任务调节(one-shot task conditioning),这种方法的泛化能力有限,因为单样本向量无法捕捉不同任务之间的相似性。
- 最近,语言条件反射显著提高了对新语言指令的泛化能力,但它也存在缺乏特异性的问题,这使得它很难泛化到难以描述的新行动上。
- 目标图像或视频调节是另外两种替代方法,有望实现更强大的泛化,并能捕捉难以用语言表达但易于用视觉呈现的细微差别。然而,事实证明它很难被学习,而且在测试时需要花费更多精力来提供,因此不太实用。
最重要的是,策略调节不仅会影响任务规范的实用性,还会对推理时的泛化产生很大影响。如果任务的表征与训练任务的表征相似,底层模型就更有可能在这些数据点之间进行插值。这通常体现在不同条件机制下的泛化类型上,例如,如果策略是以自然语言命令为条件的,那么它很可能会泛化到文本命令的新措辞上,而同样的策略在接受拾放任务训练时,即使折叠的手臂轨迹与拾放相似,也很难泛化到折叠任务上,因为在语言空间中,这一新任务不属于之前所见的数据。这就引出了一个问题:我们能否设计出一种更好的调节模式,既具有表现力,实用性,又能更好地推广到新任务中?
方法介绍
为此,用轨迹草图作为表达能力和易用性之间的中间解决方案。具体来说,采用了投射到摄像机视场中的2D轨迹,假设摄像机已校准。这种方法有几个优点。例如,在给定演示数据集的情况下,可以自动提取事后可见的2D轨迹标签,而无需手动标注。此外,轨迹标签允许我们明确反映机器人不同运动之间的相似性,正如我们在实验中展示的那样,与以语言和目标为条件的替代方法相比,这种方法能更好地利用训练数据集,从而实现更广泛的任务。此外,人类或现代图像编辑模型可以直接在图像上勾勒出这些轨迹,使其成为一个简单而又富有表现力的策略界面。
本文的主要贡献在于新颖的策略调节框架 RT-Trajectory,它能促进任务的泛化。这种方法采用2D轨迹作为机器人策略的调节信号,既可由人类解读,又具有丰富的表现力。我们的实验设置涉及各种已知和新奇物体的操作任务。实验表明,RT-Trajectory 优于现有的策略调节技术,尤其是在对新行动的泛化方面,而这正是机器人技术面临的一项挑战。
相关工作
Generalization in Robot Learning
最近的研究工作已经开始研究基于学习的机器人策略如何能够稳健地泛化到训练期间所见数据之外的情况。
- 实证研究分析了机器人模仿学习中的泛化挑战,重点关注 2D 控制,演示质量,视觉分布偏移和行动一致性。
- 此外,先前的研究还提出了明确测试策略泛化的评估方案;其中包括泛化到新语义属性,保留语言模板,未见物体类别,新背景和干扰项,分布转移组合,开放集语言指令和网络规模语义概念。
这些先前的研究主要针对语义和视觉泛化,而我们还研究了任务泛化,其中包括需要以新的方式结合已见状态和行动的情况,或泛化到完全未见的状态或行动。
Policy Conditioning Representations
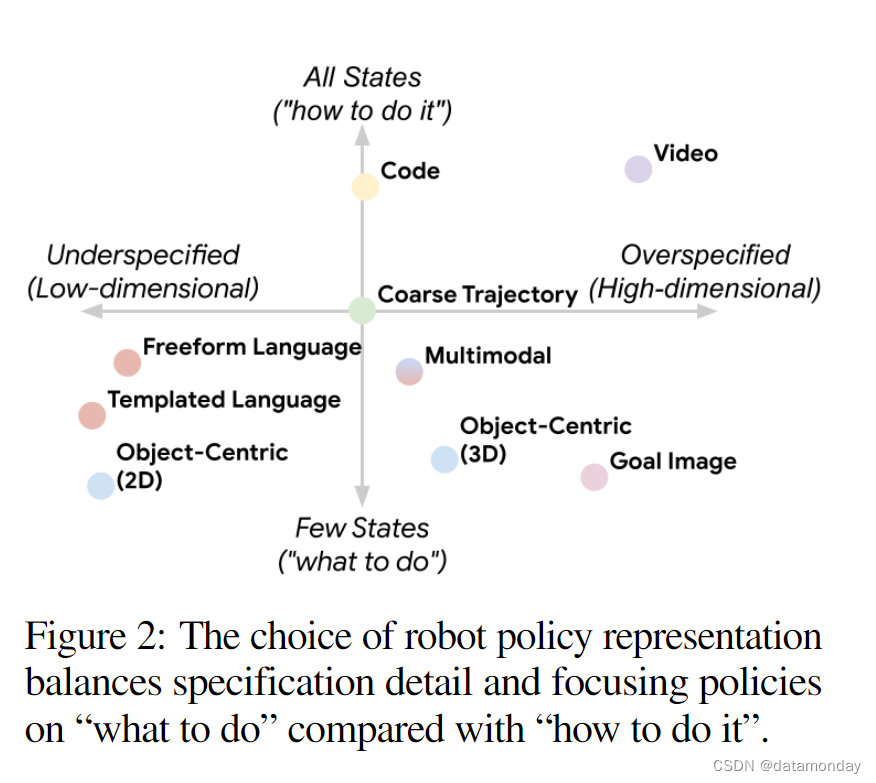
研究了几种策略调节方法。大体上,有两个方面需要考虑:
- 1)目标的过度指定和不足指定
- 2)对轨迹中所有状态的调节与仅对最终状态的调节
近期最重要的研究集中在语言条件策略上,这些策略利用模板化或自由形式语言作为任务规范。
- 以语言为条件的策略:可以被认为是对最终状态的规范不足(例如,一个完成 pick can 的策略有许多可能的最终状态)。
- 以目标图像为条件的策略:最终目标图像定义了所需任务的结束状态。以目标图像为条件的策略可以被认为是对最终状态(即 “做什么”)的过度规定,因为它们定义了整个配置,其中有些可能并不相关。例如,目标图像的背景像素可能与任务无关,而是包含了多余的信息。
- 有一些中间层次规范的例子提出了以2D和3D物体为中心的表征,使用多模态嵌入将任务表示为任务条件文本和目标条件图像的联合空间,以及将策略描述为代码,约束如何执行每个状态。
- 更详细的状态规范类型是对整个 RGB 视频进行调节,这相当于对整个状态轨迹(即 “如何做”)进行过度规范。然而,对长视频进行上下文编码在规模上具有挑战性,而且从高维视频中学习是一个具有挑战性的学习问题。
与此相反,我们的方法使用轻量级的粗粒度状态规范,目的是在足够的状态规范能力以捕捉显著的状态属性,同时又易于学习之间取得平衡。我们特别与语言条件和目标图像条件基线进行了比较,并展示了使用中间层次条件表征(如粗轨迹草图)的好处。
模型架构
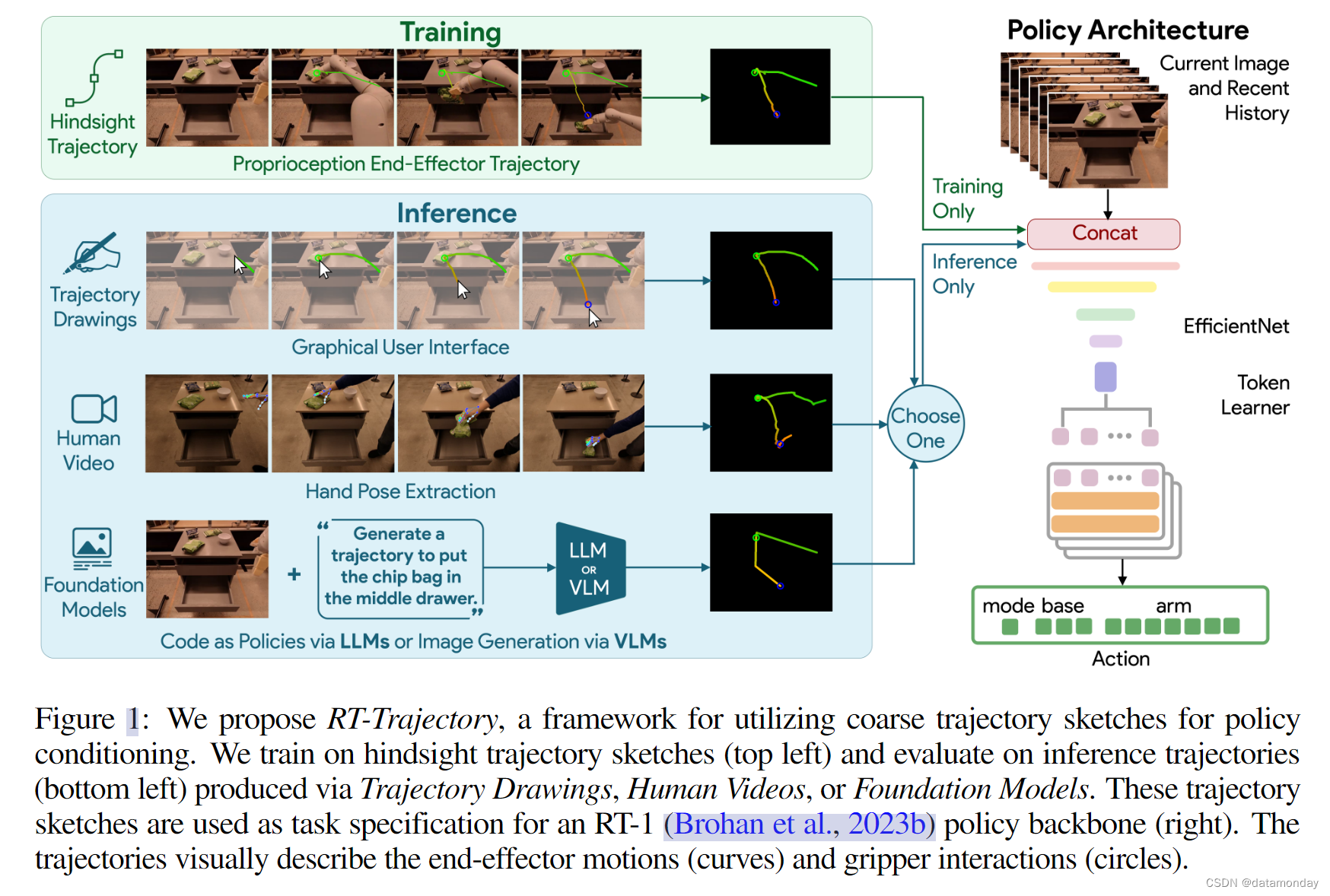
目标是学习一种能够利用2D粗略轨迹草图作为条件的机器人控制策略。我们提出的方法的系统图见图 1。在策略训练过程中,我们首先进行事后轨迹标注,从演示数据集中获取轨迹条件标签(第 3.2 节)。这使我们能够重新使用现有的演示数据集,并确保提出的方法能够扩展到新的数据集。然后,通过模仿学习训练以2D轨迹草图为条件的基于Transformer的控制策略(第 3.3 节)。在推理过程中,用户或高层次规划器会从机器人摄像头中观察到初始图像,并创建一个粗略的2D轨迹草图来指定所需的运动(图 1 左下方),然后将其输入训练好的控制策略,以执行指定的操作任务。
HINDSIGHT TRAJECTORY LABELS
在本节中,介绍如何从演示数据集中获取训练轨迹条件标签(trajectory conditioning labels)。建轨迹表示格式的 3 个基本要素:
- 2D轨迹(2D Trajectories)
- 颜色分级(Color Grading)
- 交互标记(Interaction Markers)
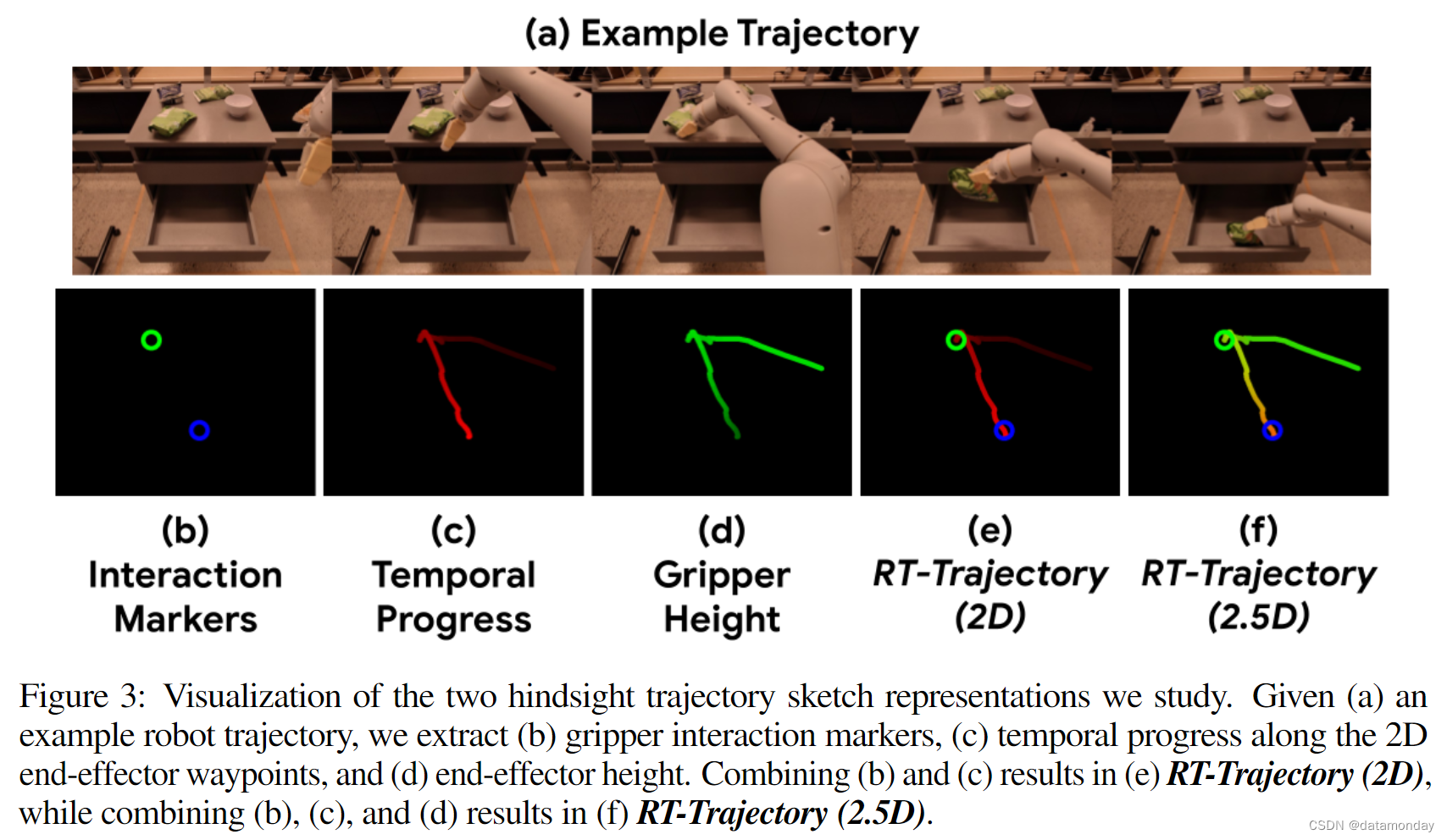
2D Trajectory
对于数据集中的每一个 episode,提取机器人末端执行器中心点的2D轨迹。具体来说,根据每一个 episode 记录的本体感觉信息,可以获得机器人末端执行器中心点的3D位置,该位置定义在每个时间步长的机器人底座帧中,并根据已知的摄像头外在和内在参数将其投影到摄像头空间。假设机器人底座和摄像头在 episode 中不会移动,这在静态操作中很常见。给定2D轨迹(像素位置序列)后,通过直线连接相邻时间步长的2D机器人末端执行器中心点,在空白图像上绘制曲线。
Color Grading
为了表达相对时间运动(如速度和方向),还探索使用轨迹图像的红色通道来指定归一化时间步长 t + 1 T \frac{t+1}{T} Tt+1,其中 t 为当前时间步长,T 为 episode 总计长度。此外,还建议将高度信息纳入轨迹表示中,利用轨迹图像的绿色通道编码相对于机器人基座的归一化高度 h t + 1 − h m i n h m a x − h m i n \frac{h_{t+1}-h_{min}}{h_{max}-h_{min}} hmax−hminht+1−hmin。
Interaction Markers
对于机器人操作任务而言,末端执行器与环境交互的时间步尤为重要。因此,我们探索了视觉标记,以明确突出抓手开始抓取和释放物体的时间步骤。具体来说,我们首先通过检查感知( p t p_t pt)和目标( p ^ t \hat{p}_t p^t)抓手关节位置之间的差值 δ t = p ^ t − p t δ_t = \hat{p}_t -p_t δt=p^t−pt,计算抓手是否与物体接触。如果差值 δ t > 0 δ_t > 0 δt>0,且 p ^ t > ε \hat{p}_t >ε p^t>ε,其中 ε 是闭合行动的阈值(ptin随着抓手闭合而增加),则表明抓手正在闭合并抓取某些物体。如果状态发生变化,例如δt <0∨ˆpt ≤ε,但δt+1 >0∧ˆpt+1>ε,我们就将时间步 t 视为闭合行动的关键步骤。同样,也可以找到开启动作的关键时间步。在关闭(或打开)抓手的所有关键时间步的2D机器人末端执行器中心点上画绿色(或蓝色)圆圈。
Trajectory Representations
在这项工作中,根据基本要素的不同组合提出了两种轨迹表示形式。
- 第一种是 RT-轨迹(2D),构建了一个 RGB 图像,其中包含带有时间信息的 2D 轨迹和交互标记,用于指示特定的机器人交互(图 3 (e))。
- 第二种表示法中引入了更详细的轨迹表示法 RT-Trajectory(2.5D),其中包括 2D 轨迹中的高度信息(图 3 (f))。
POLICY TRAINING
由于模仿学习在多任务机器人模仿学习中取得了巨大成功,利用了模仿学习。假定可以获得一系列成功的机器人演示。每个episode τ 包含一对观察结果 ot 和行动 at 的序列:τ ={(ot,at)} 。观察结果包括从头部摄像头获取的 RGB 图像 xt 和事后轨迹草图 ctraj。根据 RT-1 框架,利用行为克隆,通过最小化输入图像和轨迹草图中预测行动的对数似然,学习由Transformer表示的策略 π。为了支持轨迹调节,我们对 RT-1 架构进行了如下修改。轨迹草图与输入序列(6 幅图像的历史记录)中沿特征维度的每幅 RGB 图像串联,由图像标记器(ImageNet 预训练 EfficientNet-B3)处理。对于图像标记器的额外输入通道,我们将第一个卷积层中的新权重初始化为零。由于不使用语言指令,我们删除了原始 RT-1 中使用的 FiLM 层。
TRAJECTORY CONDITIONING DURING INFERENCE
在推理过程中,需要轨迹草图作为 RT-Trajectory 的条件。我们研究了生成轨迹草图的 4 种不同方法:人类绘画,人类视频,以代码为策略的 LLM 提示以及图像生成模型。
Human-drawn Sketches
人画草图是生成轨迹草图的一种直观而实用的方法。为了可扩展地生成这些草图,我们设计了一个简单的图形用户界面(GUI),让用户根据机器人的初始摄像头图像绘制轨迹草图,如 App.B.1 所示。
Human Demonstration Videos with Hand-object Interaction
第一人称人体演示视频是另一种输入方式。我们从视频中估算出人类手部姿态的轨迹,并将其转换为机器人末端执行器姿态的轨迹,随后可用于生成轨迹草图。
Prompting LLMs with Code as Policies
大型语言模型已经证明了编写代码以执行机器人任务的能力。我们采用与 Gonzalez Arenas 等人中描述的类似方法来构建一个提示,其中包含有关 VLM 检测到的场景中的物体,机器人约束条件,抓手方向和坐标系以及任务指令的文本描述。通过使用该提示,LLM 会编写代码来生成一系列3D姿态——这些姿态原本是要通过运动规划器来执行的,然后我们可以重新利用这些姿态,在初始图像上绘制轨迹草图,为 RT-Trajectory 提供条件。
Image Generation Models
由于轨迹调节是以图像的形式表示的,因此可以使用文本引导的图像生成模型来生成轨迹草图,但前提是要有初始图像和描述任务的语言指令。在我们的工作中,我们使用了 PaLM-E 风格模型,该模型可生成由 ViT-VQGAN 衍生的向量量化标记,代表轨迹图像。解码后,生成的图像可用于 RT 轨迹的条件。
实验结果
真实机器人实验旨在研究以下问题:
- RT-Trajectory 能否泛化到训练数据集以外的任务?
- 根据事后轨迹草图训练的 RT-Trajectory 能否在测试时泛化到各种人类指定或自动轨迹生成方法?
- RT-Trajectory 能够实现哪些新兴功能?
- 我们能否定量测量评估轨迹运动与训练数据集运动的差异程度?
EXPERIMENTAL SETUP
在实验中使用的是 Everyday Robots 公司生产的移动机械手机器人,它有一个 7 自由度机械臂,一个双指抓手和一个移动底座。
Seen Skills
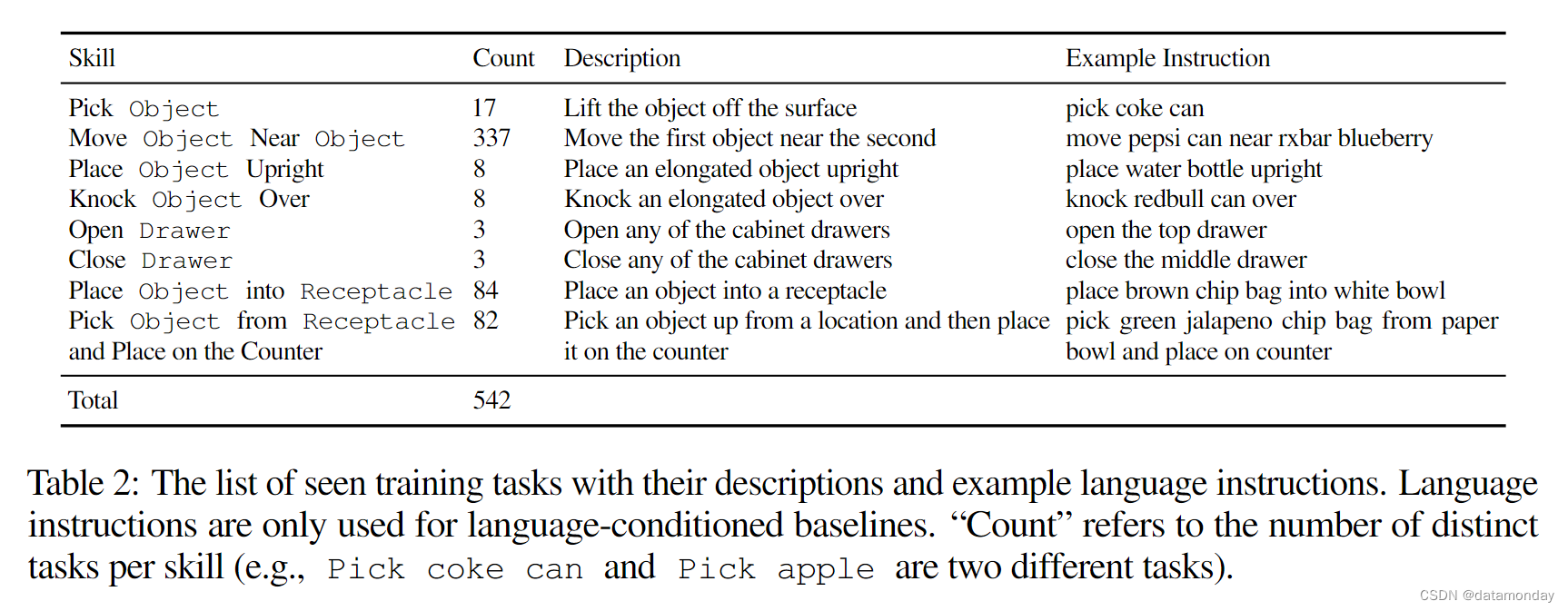
使用 RT-1 演示数据集进行训练。语言指令包括 8 种不同的操作技能(如移动靠近),操作物体是一组 17 种家用厨房用品;该数据集总共包括约 73K 个真实的机器人演示,涉及 542 个可见任务,这些任务都是通过人工远程操作收集的。更详细的概况见表 2。
Unseen Skills
如表 3 和图 4 所示,我们提出了 7 种新的评估技能,其中包括未见物体和操作工作区。直立和移动以及在抽屉内移动都会考察策略是否能将不同的可见技能组合成一个新技能。例如,在抽屉内移动研究的是该策略是否能够在抽屉内移动物体,而移动到附近(seen skillMove Near)只包括在桌面高度上的移动。重新装入抽屉要求机器人将零食放入抽屉的空槽中。它考察的是策略是否能够精确地将物体放置到目标位置。从椅子上拾取则考察机器人是否能够在看不见的操作工作区内,从看不见的高度拾取物品。Fold Towel 和 Swivel Chair 展示了操作可变形物体和与欠驱动系统交互的能力。
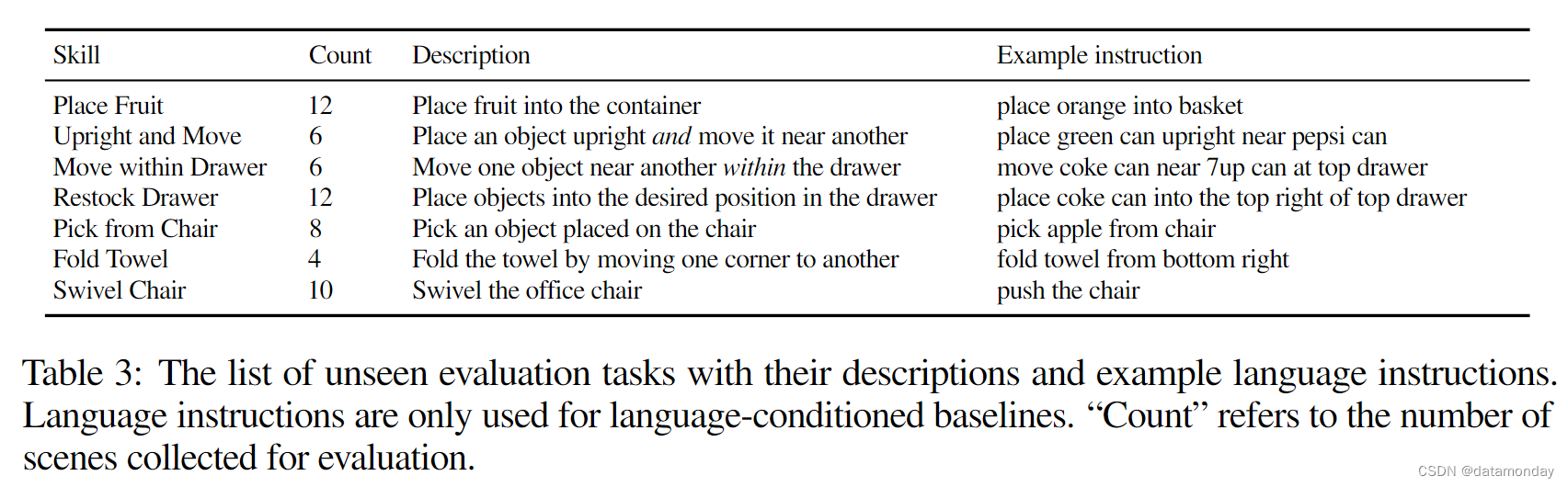

Evaluation Protocol
不同的轨迹草图会促使 RT-Trajectory 有不同的表现。为了尽可能公平地对不同方法进行定量比较,我们提出了以下评估方案。对于要评估的每种技能,我们都要收集一组场景。每个场景都定义了任务的初始状态,由机器人头部摄像头拍摄的 RGB 图像描述。在评估过程中,我们首先将相关物体对齐到其在场景中的原始位置,然后运行策略。对于调理轨迹,我们在第 4.2 节中使用人类绘制的草图来完成未见任务。在第 4.3 节中,我们将评估第 3.4 节中描述的其他轨迹草图生成方法。
UNSEEN TASK GENERALIZATION
比较 RT 轨迹与其他基于学习的基线对第 4.1 节中介绍的未见任务场景的泛化能力。
- RT-1:基于相同训练数据训练的语言条件策略;
- RT-2:基于我们的训练数据和互联网规模 VQA 数据混合训练的语言条件策略;
- RT-1-Goal:基于相同训练数据训练的目标条件策略。
对于 RT-Trajectory,我们通过图形用户界面手动生成轨迹草图(见 B.1 节)。有关轨迹生成的详细信息,请参见附录 B.2。B.2. 对于 RT-1-目标,实施细节和目标条件生成见附录 B.4。B.4. 结果如图 5 和表 4 所示。我们的 RT-Trajectory(2D)和 RT-Trajectory(2.5D)方法的总体成功率分别为 50%和 67%,远远优于我们的基线方法: RT-1 (16.7%),RT-2 (11.1%),RT-1-Goal (26%)。语言条件策略很难泛化到带有语义未见过的语言指令的新任务,即使在训练过程中看到了实现这些任务的行动(见第 4.5 节)。RT-1-Goal 的泛化效果优于其语言条件对策。然而,在新场景中进行推理时,目标条件比轨迹草图更难获得,而且对与任务无关的因素(如背景)很敏感。在高度信息有助于减少模糊性的任务中,RT-轨迹(2.5D)优于 RT-轨迹(2D)。例如,仅使用2D轨迹时,RT-轨迹(2D)很难推断出正确的采摘高度,而这对于从椅子上采摘至关重要。
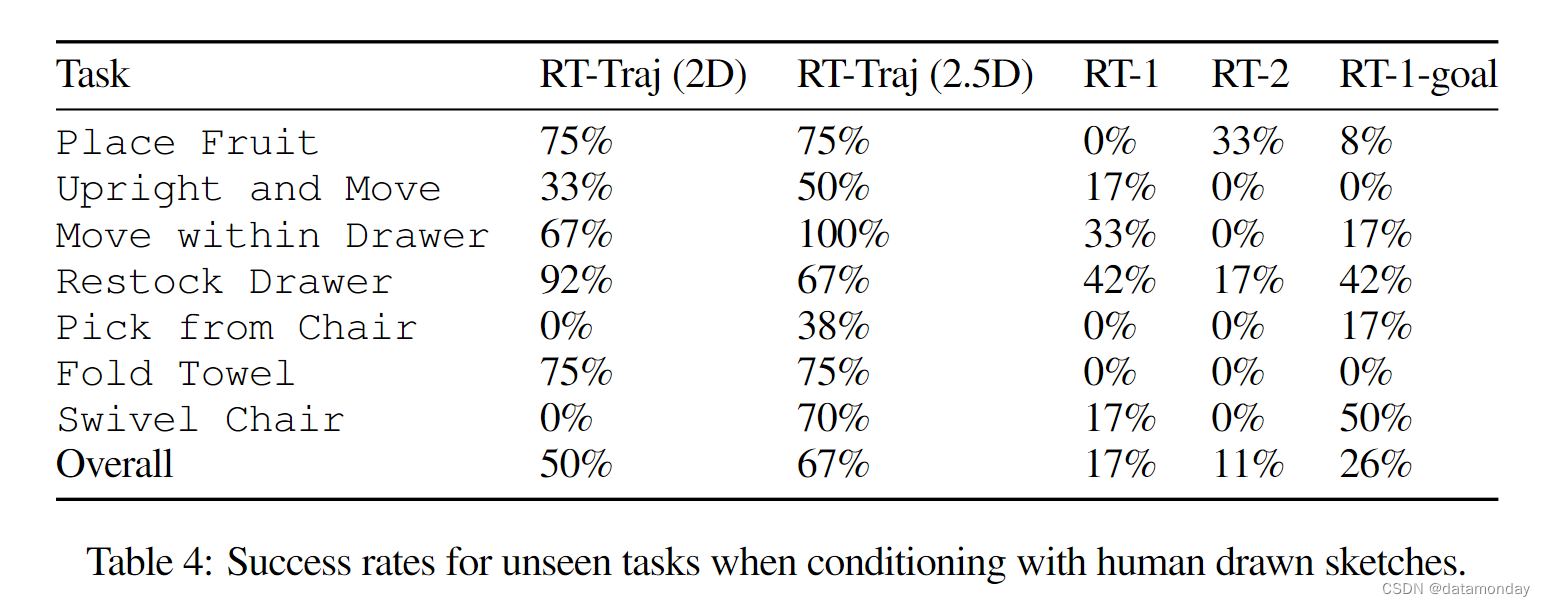
DIVERSE TRAJECTORY GENERATION METHODS
研究 RT 轨迹是否能够在推理时泛化到来自更自动化和更通用流程的轨迹。具体来说,我们将定量评估 RTTrajectory 在人类视频演示生成的粗略轨迹草图,通过以代码为策略的提示生成的 LLMs 条件下的表现,并展示图像生成 VLMs 的定性结果。此外,我们还将 RT 轨迹与非学习基线(IK Planner)进行了比较,以跟踪生成的轨迹:应用反运动学(IK)求解器将末端执行器姿态转换为关节位置,然后由机器人执行。
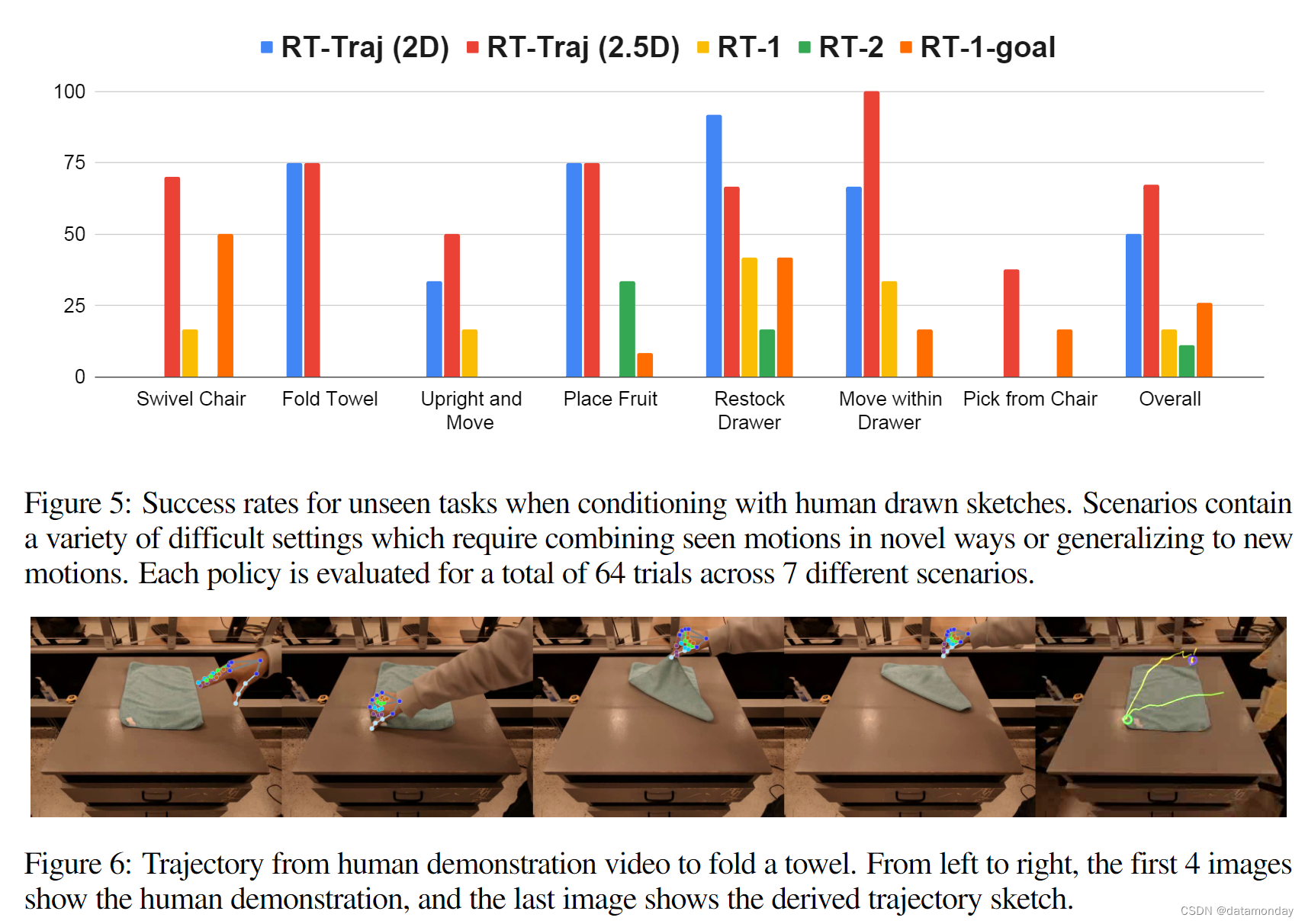
Human Demonstration Videos
我们分别收集了 18 个和 4 个第一人称演示视频,其中有摘取(见训练技能)和折叠毛巾的手物交互。图 6 显示了一个示例。
Prompting with Code as Policies
我们让一个 LLM(OpenAI,2023)编写代码,根据任务指令和所看到的两个技能(拾取和打开抽屉)的物体标签生成轨迹。执行 LLM 编写的代码后,我们会得到一系列目标机器人航点,然后将其处理为轨迹草图。与人类指定的轨迹不同,LLM 生成的轨迹是为由 IK 规划器执行而设计的,因此是精确的线性轨迹,如图 20 所示。虽然这些轨迹也与训练数据中的后视轨迹不同,但 RT-Trajectory 能够正确执行这些轨迹,并在各种拾取任务中表现优于 IK 规划器,这是因为 RT-Trajectory 能够使运动适应物体方向等场景细微差别。结果如表 1b 所示。
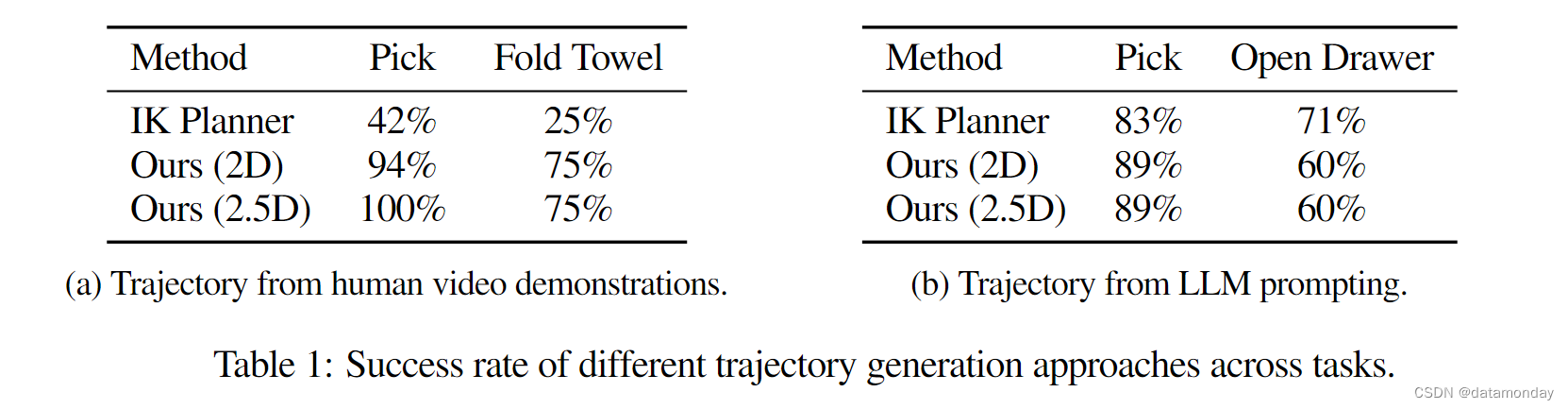
Image Generation Models
我们用语言指令和初始图像作为 VLM 的条件,以输出轨迹标记,这些标记被去标记化为绘制轨迹的2D像素坐标。定性示例如图 7 所示。虽然我们看到生成的轨迹草图噪声较大,与训练后视轨迹草图有很大差异,但我们发现 RT-Trajectory 的表现还是很不错的。随着图像生成 VLM 的快速改进,我们预计它们生成轨迹草图的能力在未来也会自然提高,并可用于 RT-Trajectory。

EMERGENT CAPABILITIES
Prompt Engineering for Robot Policies
与 LLM 在响应语言提示工程时做出不同反应的方式类似,RT-Trajectory 可实现视觉提示工程,当初始场景固定但粗轨迹提示得到改进时,轨迹条件策略可能会表现出更好的性能。我们发现,改变轨迹草图可诱导 RT-Trajectory 以可重复的方式改变行为模式,这就提供了一个有趣的机会:如果以轨迹为条件的机器人策略在某些场景中失效,实践者可能只需要用不同的轨迹提示 “询问机器人”,而不需要重新训练策略或收集更多数据。从本质上讲,这与以语言为条件的机器人策略的标准开发实践大相径庭,可视为对机器人操作的零样本指令微调的早期探索,类似于语言建模的能力。示例见附录 E.1。
Generalizing to Realistic Settings
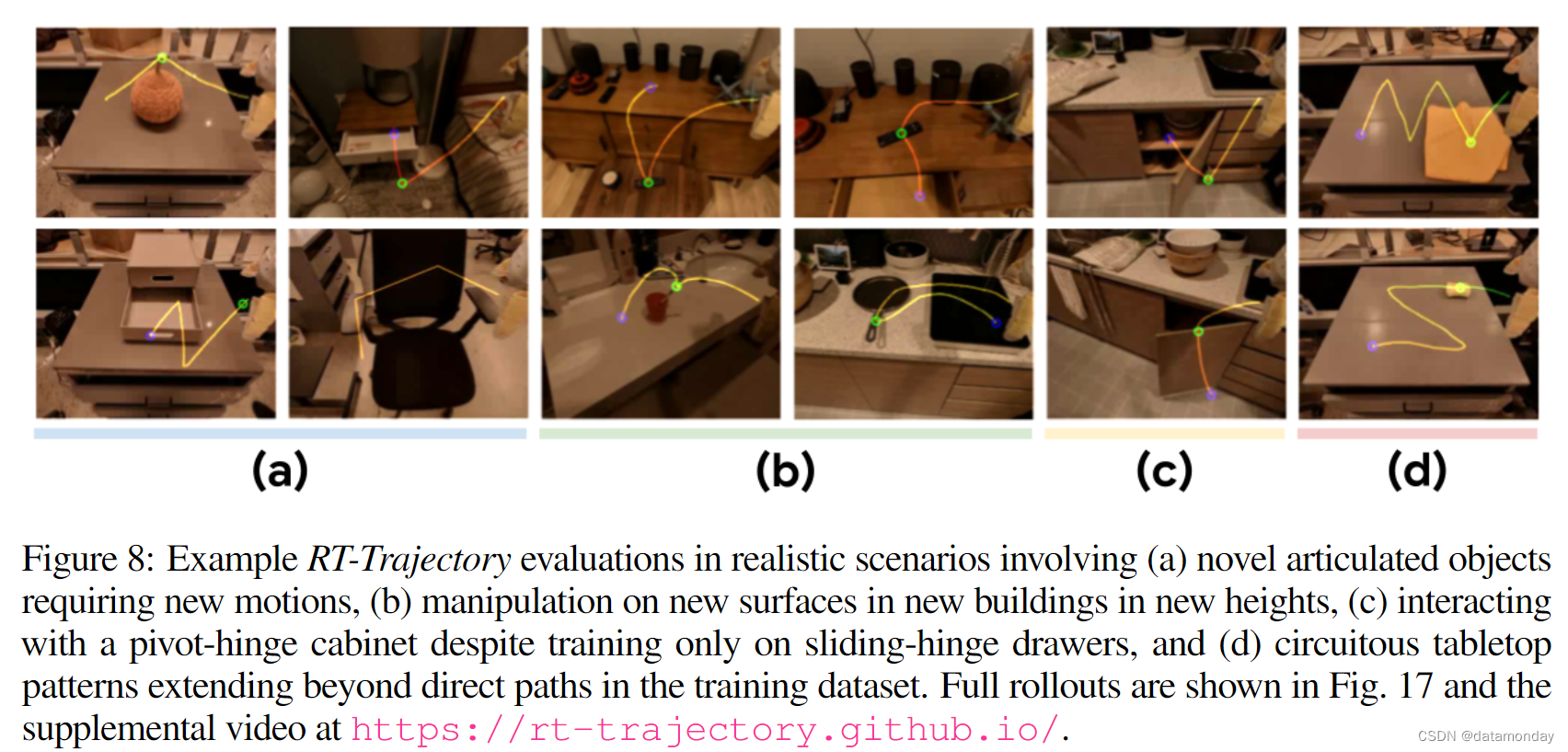
之前研究机器人泛化的作品通常只能一次性评估几种分布变化,因为泛化到同时发生的物理和视觉变化具有挑战性;然而,这些类型的同时分布变化在现实世界中非常普遍。作为一项定性案例研究,我们在 2 栋新建筑的 4 个逼真新颖的房间中对 RT 轨迹进行了评估,这些房间包含全新的背景,照明条件,物体,布局和家具几何形状。我们发现,只需少量或适度的轨迹提示工程,RT-Trajectory 就能成功执行各种要求新颖运动泛化和鲁棒性的任务,以应对分布外视觉分布偏移。图 8 展示了这些任务,图 17 则全面展示了滚动过程。
MEASURING MOTION GENERALIZATION
我们希望明确测量运动相似性,以便更好地了解 RT 轨迹如何能够泛化到未见过的场景中,以及它能在多大程度上应对新运动泛化的挑战。为此,我们打算将评估轨迹与训练期间看到的最相似轨迹进行比较。为此,我们建议利用离散的 Frechet 距离来测量轨迹相似性(详情见附录 C.1)。通过计算查询轨迹与训练数据集中所有轨迹之间的距离,我们可以检索出我们的策略所训练过的最相似的轨迹。我们将在第 3.4 节中对未见任务评估的滚动轨迹进行这种查询。图 9 展示了选定查询轨迹的 10 个最相似的训练轨迹。
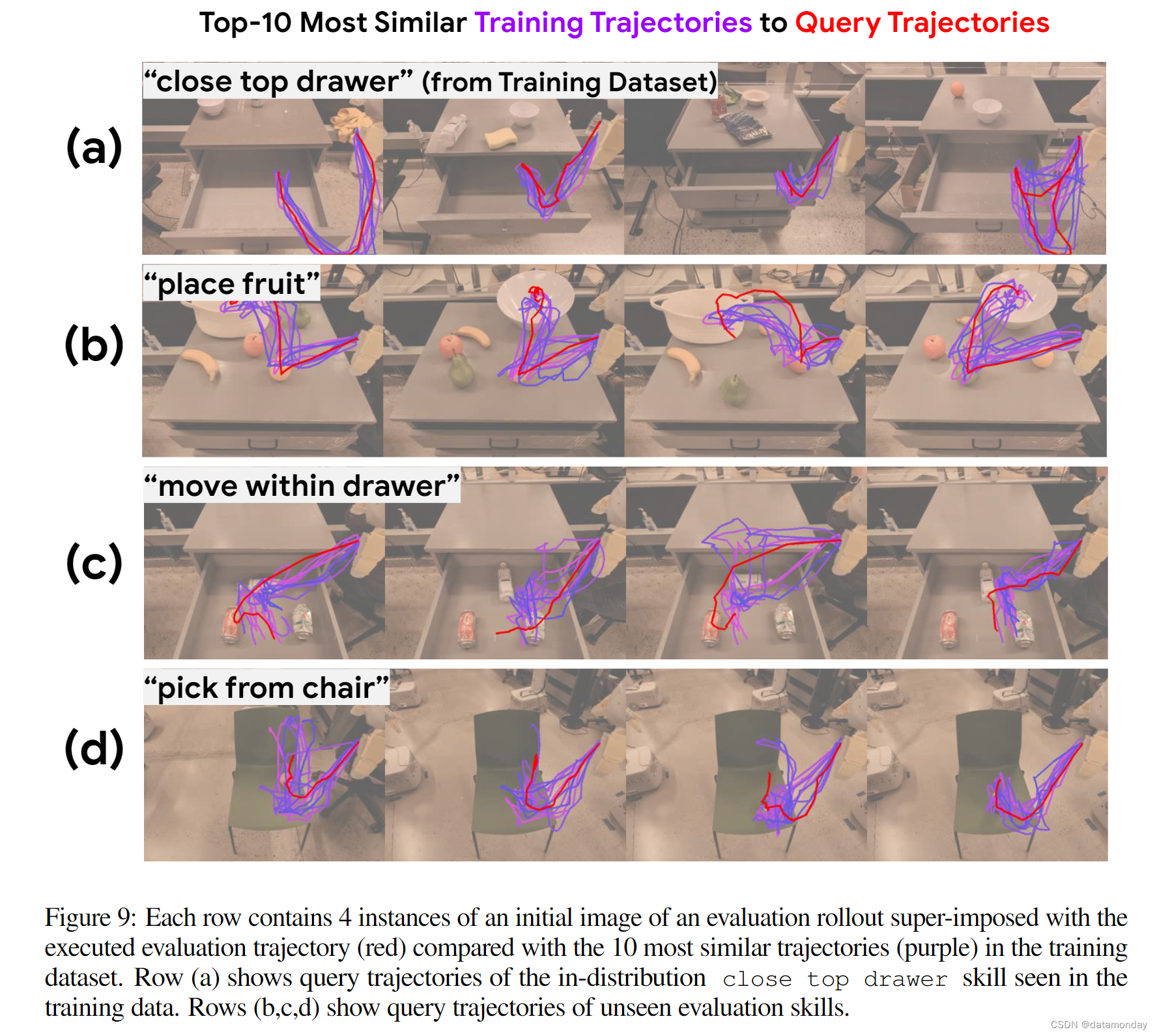
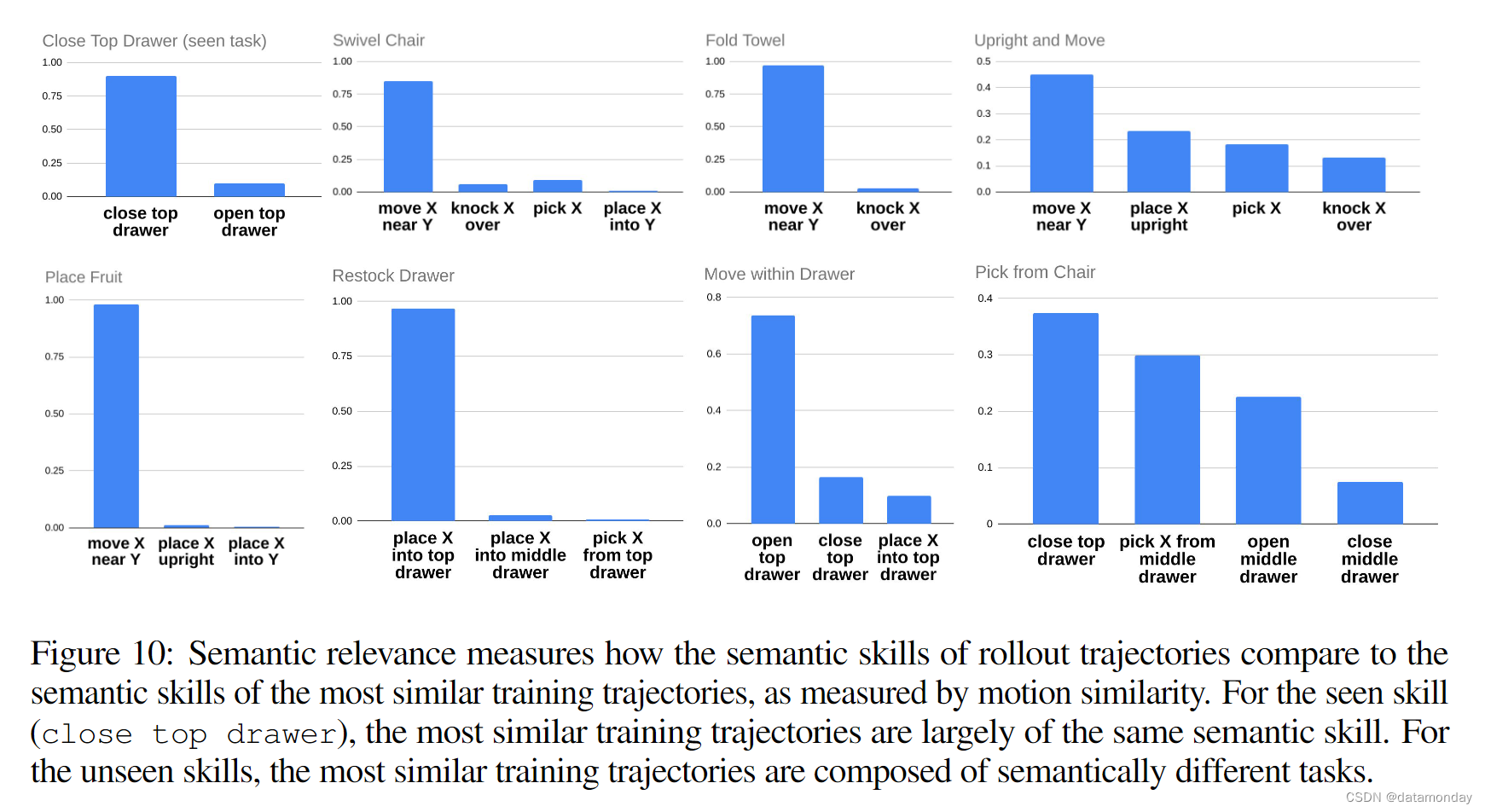
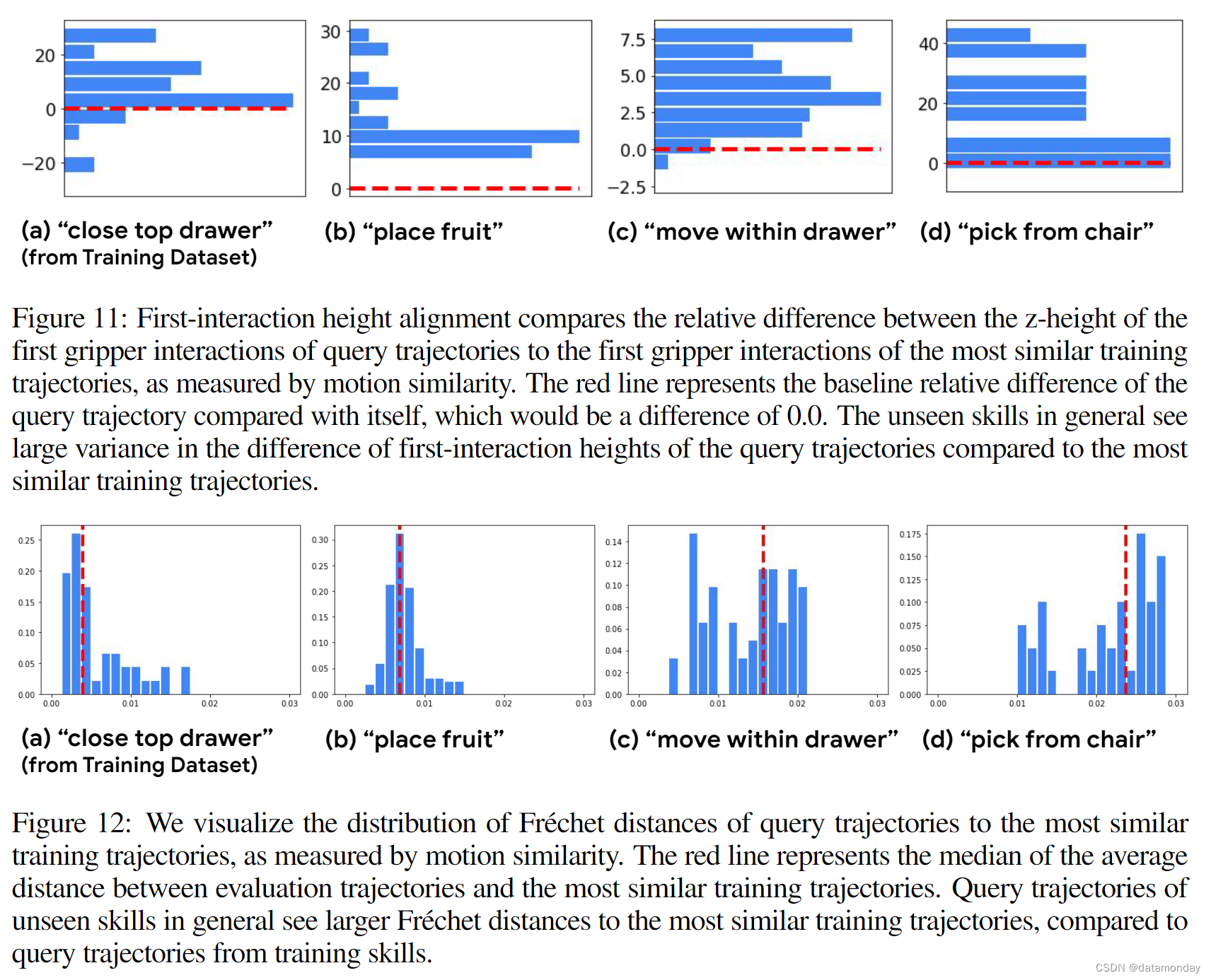
图 10,图 11 和图 12 还显示了最相似训练样本的统计数据,例如技能语义的分布情况。我们发现,未见任务的轨迹与训练轨迹显示出不同程度的相似性。例如,将水果放入一个高碗中的行动可能与特定的 X 靠近 Y 的移动实例惊人地相似。此外,即使是那些看起来与最相似的训练轨迹形状接近的评估轨迹,我们也会发现在精度关键因素上存在差异,例如抓手交互的 z 高度(误差几厘米的拾取就不会成功)或语义相关性(最相似的训练轨迹描述的技能与目标轨迹不同)。因此,我们预计所提出的新技能评估确实需要对已见行动进行插值,同时对新行动进行概括。
实验结论
在这项工作中,我们提出了一种新颖的策略调节方法,用于训练机器人操作策略,使其能够泛化到大大超出训练数据的任务和运动中。我们提出的方法的关键是用于指定操作任务的2D轨迹草图表示法。我们经过训练的轨迹草图条件策略具有视觉轨迹草图引导的可控性,同时保留了基于学习的策略在处理模糊场景和泛化到新语义方面的灵活性。我们对训练中从未见过的 7 种不同操作技能进行了评估,并与三种基准方法进行了比较。我们提出的方法成功率高达 67%,明显优于之前最先进方法的 26%。
虽然我们证明了我们提出的方法在新颖的操作任务中实现了令人鼓舞的泛化能力,但仍存在一些局限性。首先,我们目前假设机器人保持静止不动,仅使用末端执行器执行有用的操作行动。将这一想法扩展到移动操作场景,让机器人通过全身控制进行操作,是一个很有前景的探索方向。其次,我们训练有素的策略会尽最大努力遵循轨迹草图指导。不过,用户可能希望指定空间区域,在这些区域中更严格地执行指导,例如在移动过程中何时避开易碎物体。因此,一个有趣的未来方向是让系统能够使用轨迹草图来处理不同类型的限制。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











