





GBDT算法还存在一些缺点,如损失函数没有进行正则化,拟合上一轮强学习器损失函数的梯度存在精度问题,每个弱学习器只能基于CART决策树生成且耗时较长,未考虑缺失值的情况。
xgboost能够很好的解决上述问题,xgboost在最小化损失函数时进行了正则化,拟合上一轮强学习器损失函数的二阶导展开,精度提高了,xgboost算法的弱学习器生成采用了并行的方式划分最优特征,提高了算法运行效率,考虑了缺失值的情况。
1. xgboost算法的损失函数推导
xgboost的损失函数在GBDT的基础上加上了正则化,正则化项如下:
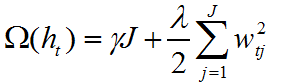
其中 γ 和  是 正则项系数,J表示叶子节点个数,
是 正则项系数,J表示叶子节点个数,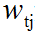 表示第t次迭代的弱学习器第j个叶子节点的值,正则化描述了弱学习器的复杂度。
表示第t次迭代的弱学习器第j个叶子节点的值,正则化描述了弱学习器的复杂度。
因此xgboost的损失函数为:
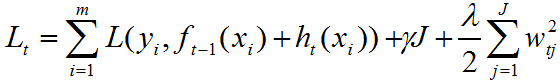
其中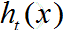 为第t次迭代的弱学习器,
为第t次迭代的弱学习器, 为第t-1次迭代的强学习器。
为第t-1次迭代的强学习器。
我们利用泰勒公式对上式进行二阶导展开:
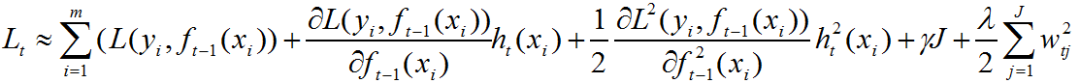
令第i个样本在第t个弱学习器的一阶导为:
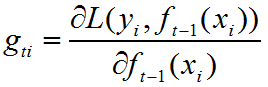
二阶导为:
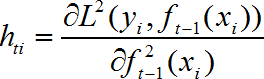
代入损失函数,得:
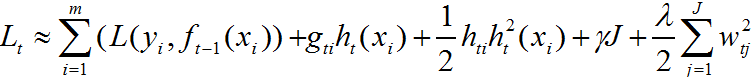
容易发现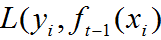 在第t次弱学习器的生成过程中为常数,因此可不用考虑。
在第t次弱学习器的生成过程中为常数,因此可不用考虑。
损失函数可化简为:
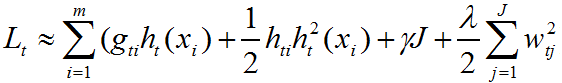
训练样本集输入给弱学习器中,以叶子节点的形式输出,每个样本对应特定的叶子节点。因此,损失函数等价于:
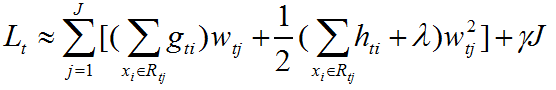
记每个叶子节点区域一阶导的和为:
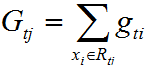
其中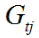 表示样本落在第t个弱学习器生成的第j个叶子节点区域的一阶导和。
表示样本落在第t个弱学习器生成的第j个叶子节点区域的一阶导和。
每个叶子节点区域二阶导的和为:
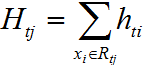
其中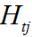 表示样本落在第t个弱学习器生成的第j个叶子节点区域的一阶导和。
表示样本落在第t个弱学习器生成的第j个叶子节点区域的一阶导和。
损失函数最终简化为:
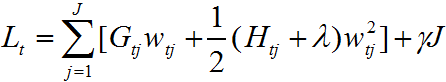
我们的目的是要计算每次迭代后的叶子节点个数和每个叶子结点的值,这一过程通过最优化损失函数求解。
2. xgboost损失函数的最优化方法
令
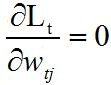
得:
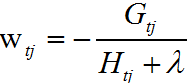
我们得到了叶子结点值的最优表达式,并代入损失函数Lt,得:
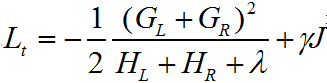
每次划分节点时,选择损失函数变化最大的特征切分点进行划分。
节点划分前后的损失函数变化记为deltaT,容易知道节点划分后的叶子节点比划分前多1个,有:
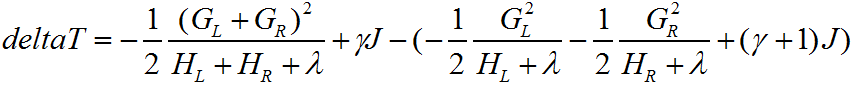
选择deltaT变化最大的特征切分点进行划分,得到叶子结点值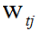 ,最后更新第t次迭代的强学习器,有:
,最后更新第t次迭代的强学习器,有:
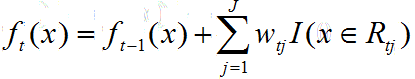
每次迭代后,我们都能计算所有样本的损失函数一阶导和二阶导。因此,按照上述介绍进行切点划分,每次划分都能最大化的减小损失函数。
3. xgboost和GBDT的比较
1) GBDT得到每次迭代的弱学习器需要两个步骤,首先拟合损失函数的负梯度,确定每个样本所对应的叶子节点区域,然后对每个节点再做一次线性搜索,确定每个叶子节点区域的值。xgboost只需要一次迭代就能计算每个样本对应的叶子节点区域和相应的值。
2)GBDT拟合上一轮强学习器损失函数的负梯度(一阶展开式),xgboost拟合上一轮强学习器损失函数的二阶导展开式,精度更高。
3)xgboost的损失函数包含了正则项,泛化能力更强。
4)xgboost每次迭代过程中,采用并行切分特征的方式,提高了算法运行效率。
5)xgboost处理特征缺失值时,根据缺失值样本放在左边或右边的损失函数的下降量,来决定缺失值的处理方式。
总之,xgboost是一种非常强大的模型构建方法,是kaggle算法竞赛中最热门的的算法,小编强烈推荐使用它。
参考
https://www.cnblogs.com/pinard/p/10979808.html
欢迎扫码关注:
















 399
399











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









