







XGBoost是现在一种非常高效的boosting集成学习的算法,被广泛的应用在各种数据与机器学习的比赛中。XGBoos是GBDT算法的一种高效的实现。
1.算法原理
给定一个数据集D,其中有n个样本与m个特征,
这里的
举个例子:假如现在我们有5个人的样本数据,包括年龄,性别,等等特征,如图所示,我们构建一棵回归树:

根据划分规则,样本数据会落在决策树的叶子节点上,这是一棵决策树的结果。我们都知道,回归树的叶子结点是一个连续的值,
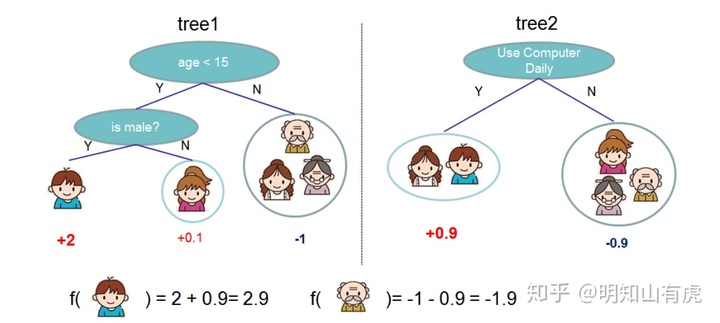
上图表示有两棵树,通过tree1对小男孩的预测,结果是2,通过tree2对小男孩的预测,结果是0.9,所以将两棵树的结果进行相加,最终结果为:2+0.9 = 2.9。其他样本同理。
1.1 目标函数
定义目标函数为:
其中,
对于train lossing来说,
- Square loss:
- Logistic loss:
为了后文公式推导方便,我们使用Square loss来进行推导。
对于正则项来说,也有多种选择:
- L1 norm(lasso):
- L2 norm:
一般在对树模型进行探究得时候,通常会涉及到以下几点:
- 叶子结点的分割
- 对树的剪枝
- 树的最大深度
- 平滑叶子结点的值
其实上述几点就是也正是说明了我们在学习什么:
实际的操作学习的内容叶子结点的分割training loss对树的剪枝由节点定义的正则化项树的最大深度对特征空间的约束平滑叶子结点的值叶子结点值的L2正则化
根据上面提到的,我们将以下函数作为目标函数:
其中,l是损失函数,用于计算预测值
1.2 模型学习
我们使用boosting tree模型,实际上采用的是加法模型(基函数的线性组合),这一点与Adaboost非常类似。在每次训练的时候在之前预测的基础上,添加一个新的基函数。
其中,
如果我们每轮加的基函数能够尽量保证是最优的话,那在训练集上,也就能保证训练误差最优,那如何选择最优的基函数呢?
对于第t轮的预测
我们如何找到最优的
对于我们第t轮的目标函数来讲,我们的目标就是要找到一个
以square loss为例:
写到这,其实我们只需要将上述目标优化,就能求得最优的
现在将损失函数与
为了表示方便,令
由于我们需要求最优解,所以删去式中的常数项对最后结果并没有影响,简化后的式子为:
「问题」:为什么
「答」:因为我们求的是第t轮的损失函数,根据之前的叙述,是在第t-1轮的结果上进行的,故
为了能够求解更加方便,我们重新细化树的定义:通过叶子结点的权重和将样本映射到叶子结点来定义树:
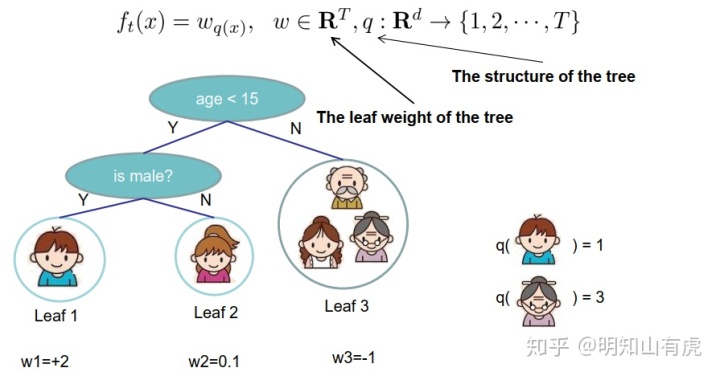
继续将正则项展开,又因为
对上式求导可得:
这就是最终求解的树的叶子结点(树结构),将
1.3 结点分裂规则(树结构得分)
可能大家在学习的过程中一直有一个疑问,在xgboost中树到底长什么样?作者给出了一种贪心的算法:「枚举所有的可能的树结构」。不断的枚举树的结构,找出其中最好的那一种,根据在1.1 模型学习中的所推出的公式,可以用作评分函数来给树的结构评分。

但是通常不可能列举出所有的树结构,取而代之的是一种贪心算法,该算法从单个叶子开始,然后迭代的分裂叶子结点。假设
令
1.3.1 精确的贪婪算法(预排序算法)
第一部分是分割后左孩子的分数,第二部分是分割后右孩子的分数,第三部分是不分割的分数。这种贪婪的算法需要枚举连续特征的所有可能分割,有了有效做到这一点,该算法首先需要按照特征值对数据进行预排序,并按照排序顺序访问数据,所以有的文章也称之为“预排序算法”:

「算法特点」:这种贪心算法能够枚举所有可能的分裂点,但是如果数据过大的话,就不能完全加在到内存中,所以一边都会使用一种近似算法。
1.3.2 近似算法(百分位算法、直方图算法)
该算法根据特征分布的百分位数提出候选分割点,然后,将连续的特征映射到这些候选点划分的bin中。这与lightGBM中的直方图算法是相通的。

1.3.3 加权分位数草图算法
文章中还介绍了一种近似算法,定义数据集
对于此算法将会再出一篇文章专门介绍该算法,这里不做解释。
1.4 稀疏感知分裂查找
在实际问题当中,我们往往输入的数据是稀疏的,造成此情况的原因有以下几种;
- 数据中存在缺失值
- 数据中存在大量的0
- 在特征工程中做过数据映射,如one-hot encoding
稀疏感知分裂查找算法就是在每个树节点中添加一个默认方向,当稀疏矩阵中缺少相应的值的时候,该样本将被分到默认的方向,如图所示:
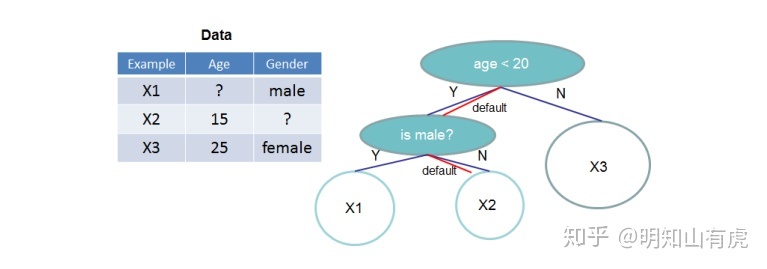
其中一个「关键的点是我们的默认方向是学出来的」。如以下算法所示,在叶子节点进行分裂的时候,直接将存在缺省值的点样本单独拿出来,具体放在左分支还是右分支通过计算出的增益来决定。这样做能够不需要对存在缺省值的点在分裂的时候进行遍历,从而提高算法的效率,而且能够将缺失作为一种隐性的特征进行学习。

1.5 防止过拟合的方法
- 「正则化目标函数」。其中包括两个部分:一个是对树里面叶子结点个数的T的惩罚,另一个是对叶子结点的权重的L2正则化,使之平滑,从而避免过拟合。
- 「引入收缩率」。在树生长的每个步骤之后,收缩率将新增加的权重按照参数
「就如同随机优化中的学习率一样」,这样能减少单棵树的影响,并为将来的树留出空间来对模型进行改进,进而防止过拟合。如下所示:
进行缩放,
- 「列采样操作」。如同随机森林一样,xgboost也进行了列采样操作,并且能够加快并行计算。
- 「设置树的最大深度」:设置超参数max_depth,避免单棵树学习的太深,从而过拟合(预剪枝操作)。
2.总结
个人认为,xgboost是学习集成学习理论中一个非常好的例子,算法涉及到boosting思想,正则化操作,以及树模型的节点分裂操作等等。论文中还涉及到了对大数据如何设计并行系统使之能够加速计算,本文中没有涉及到相关的介绍,我打算专门写一篇文章来介绍xgboost中的并行系统设计。如果想要真正的掌握xgboost的算法思想以及原理,个人以为仅仅看论文、作者ppt还有博客是远远不够的,还要去看源码,目前我还没看源码,估计并行系统设计那一块需要看。所以相关内容将会放到下一篇文章中。
3.参考内容
- [1]:Tianqi Chen and Carlos Guestrin. Xgboost: A scalable tree boosting system. In Proceedings of the 22Nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pages 785–794. ACM, 2016.
- [2]:[xgboost github文档] (https://github.com/dmlc/xgboost )
欢迎大家关注我的微信公众号:哦呦明知山有虎
或者公众号微信:Geralt_U
一个IT界的小学生,分享自己的一些LeetCode刷题记录,以及一些学习笔记,长得好看的同学都关注了呢~
















 2476
2476











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









