






选择排序
选择排序(Selection sort)是一种简单直观的排序算法。它的工作原理如下。
首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。
选择排序的主要优点与数据移动有关。
如果某个元素位于正确的最终位置上,则它不会被移动。选择排序每次交换一对元素,它们当中至少有一个将被移到其最终位置上,因此对 n 个元素的表进行排序总共进行至多 (n-1) 次交换。
在所有的完全依靠交换去移动元素的排序方法中,选择排序属于非常好的一种。

原地操作几乎是选择排序的唯一优点,当空间复杂度要求较高时,可以考虑选择排序;实际适用的场合非常罕见。
package com.github.houbb.sort.core.api;
import com.github.houbb.log.integration.core.Log;
import com.github.houbb.log.integration.core.LogFactory;
import com.github.houbb.sort.core.util.InnerSortUtil;
import java.util.List;
/**
* 选择排序
* @author binbin.hou
* @since 0.0.3
*/
public class SelectSort extends AbstractSort {
private static final Log log = LogFactory.getLog(SelectSort.class);
@Override
@SuppressWarnings("all")
protected void doSort(List> original) {
// 遍历,从 0,n-1
final int size = original.size();
for(int i = 0; i
int minIndex = i;
// 比较,找到最小的一个。
for(int j = i+1; j
if(InnerSortUtil.lt(original, j, minIndex)) {
minIndex = j;
}
}
// 进行交换
if(minIndex != i) {
InnerSortUtil.swap(original, i, minIndex);
}
}
}
}
可见选择排序的实现其实非常简单,也很容易理解。
直接一个循环,找到后面最小的一个元素,如果不是当前位置的元素,则进行一次交换即可。
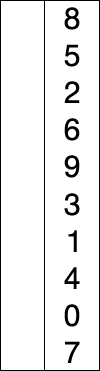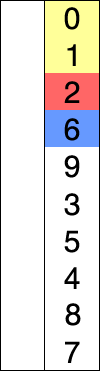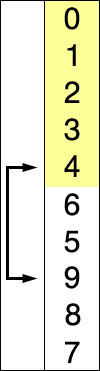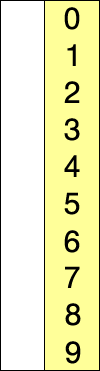
比较方法
为了便于复用,我们把小于的比较方法抽成工具方法,实现如下:
/**
* 是否小于元素
* @param original 原始
* @param i 索引
* @param j 指定元素索引
* @since 0.0.3
*/
@SuppressWarnings("all")
public static boolean lt(List original, int i, int j) {
Comparable source = (Comparable) original.get(i);
Comparable target = (Comparable) original.get(j);
return source.compareTo(target)
}
静态化
为了让这个排序使用起来更加方便,我们将其封装为静态方法:
/**
* 选择排序
* @param 泛型
* @param list 列表
* @since 0.0.3
*/
public static > void select(List list) {
Instances.singleton(SelectSort.class).sort(list);
}
测试
测试代码
List list = RandomUtil.randomList(5);
System.out.println("开始排序:" + list);
SortHelper.select(list);
System.out.println("完成排序:" + list);
测试日志
日志如下:
开始排序:[6, 11, 79, 77, 50]
完成排序:[6, 11, 50, 77, 79]
复杂度与稳定性
从代码中可以看出一共遍历了n + n-1 + n-2 + … + 2 + 1 = n * (n+1) / 2 = 0.5 * n ^ 2 + 0.5 * n,那么时间复杂度是 O(N^2)。
所以性能还是比较差的,一般不建议使用。
因为在无序部分最大元素和有序部分第一个元素相等的时候,可以将无序部分最大元素放在前面,所以选择排序是稳定的。
开源地址
为了便于大家学习,上面的排序已经开源,开源地址:
https://github.com/houbb/sort
欢迎大家 fork/star,鼓励一下作者~~
小结
快速排序之所比较快,因为相比冒泡排序,每次交换是跳跃式的。
每次排序的时候设置一个基准点,将小于等于基准点的数全部放到基准点的左边,将大于等于基准点的数全部放到基准点的右边。这样在每次交换的时候就不会像冒泡排序一样每次只能在相邻的数之间进行交换,交换的距离就大的多了。
只能说,分治算法,永远滴神!
希望本文对你有帮助,如果有其他想法的话,也可以评论区和大家分享哦。
各位极客的点赞收藏转发,是老马持续写作的最大动力!















 7064
7064











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









