







目录
天小天:(一)Spark Streaming 算子梳理 — 简单介绍streaming运行逻辑
天小天:(二)Spark Streaming 算子梳理 — flatMap和mapPartitions
天小天:(三)Spark Streaming 算子梳理 — transform算子
天小天:(四)Spark Streaming 算子梳理 — Kafka createDirectStream
天小天:(五)Spark Streaming 算子梳理 — foreachRDD
天小天:(六)Spark Streaming 算子梳理 — glom算子
天小天:(七)Spark Streaming 算子梳理 — repartition算子
天小天:(八)Spark Streaming 算子梳理 — window算子
前言
本文主要讲解repartiion的作用及原理。
作用
repartition用来调整父RDD的分区数,入参为调整之后的分区数。由于使用方法比较简单,这里就不写例子了。
源码分析
接下来从源码的角度去分析是如何实现重新分区的。
DStream
/**
* Return a new DStream with an increased or decreased level of parallelism. Each RDD in the
* returned DStream has exactly numPartitions partitions.
*/
def repartition(numPartitions: Int): DStream[T] = ssc.withScope {
this.transform(_.repartition(numPartitions))
}从方法中可以看到,实现repartition的方式是通过Dstream的transform算子之间调用RDD的repartition算子实现的。
接下来就是看看RDD的repartition算子是如何实现的。
RDD
/**
* Return a new RDD that has exactly numPartitions partitions.
*
* Can increase or decrease the level of parallelism in this RDD. Internally, this uses
* a shuffle to redistribute data.
*
* If you are decreasing the number of partitions in this RDD, consider using `coalesce`,
* which can avoid performing a shuffle.
*
* TODO Fix the Shuffle+Repartition data loss issue described in SPARK-23207.
*/
def repartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope {
coalesce(numPartitions, shuffle = true)
}首先可以看到RDD的repartition的实现是调用时coalesce方法。其中入参有两个第一个是numPartitions为重新分区后的分区数量,第二个参数为是否shuffle,这里的入参为true代表会进行shuffle。
接下来看下coalesce是如何实现的。
def coalesce(numPartitions: Int, shuffle: Boolean = false,
partitionCoalescer: Option[PartitionCoalescer] = Option.empty)
(implicit ord: Ordering[T] = null)
: RDD[T] = withScope {
require(numPartitions > 0, s"Number of partitions ($numPartitions) must be positive.")
if (shuffle) {// 是否经过shuffle,repartition是走这个逻辑
/** Distributes elements evenly across output partitions, starting from a random partition. */
// distributePartition是shuffle的逻辑,
// 对迭代器中的每个元素分派不同的key,shuffle时根据这些key平均的把元素分发到下一个stage的各个partition中。
val distributePartition = (index: Int, items: Iterator[T]) => {
var position = new Random(hashing.byteswap32(index)).nextInt(numPartitions)
items.map { t =>
// Note that the hash code of the key will just be the key itself. The HashPartitioner
// will mod it with the number of total partitions.
position = position + 1
(position, t)
}
} : Iterator[(Int, T)]
// include a shuffle step so that our upstream tasks are still distributed
new CoalescedRDD(
new ShuffledRDD[Int, T, T](mapPartitionsWithIndex(distributePartition), // 为每个元素分配key,分配的逻辑为distributePartition
new HashPartitioner(numPartitions)), // ShuffledRDD 根据key进行混洗
numPartitions,
partitionCoalescer).values
} else {
// 如果不经过shuffle之间返回CoalescedRDD
new CoalescedRDD(this, numPartitions, partitionCoalescer)
}
}从源码中可以看到无论是否经过shuffle最终返回的都是CoalescedRDD。其中区别是经过shuffle需要为每个元素分配key,并根据key将所有的元素平均分配到task中。
CoalescedRDD
private[spark] class CoalescedRDD[T: ClassTag](
@transient var prev: RDD[T], // 父RDD
maxPartitions: Int, // 最大partition数量,这里就是重新分区后的partition数量
partitionCoalescer: Option[PartitionCoalescer] = None // 重新分区算法,入参默认为None)
extends RDD[T](prev.context, Nil) { // Nil since we implement getDependencies
require(maxPartitions > 0 || maxPartitions == prev.partitions.length,
s"Number of partitions ($maxPartitions) must be positive.")
if (partitionCoalescer.isDefined) {
require(partitionCoalescer.get.isInstanceOf[Serializable],
"The partition coalescer passed in must be serializable.")
}
override def getPartitions: Array[Partition] = {
// 获取重新算法,默认为DefaultPartitionCoalescer
val pc = partitionCoalescer.getOrElse(new DefaultPartitionCoalescer())
// coalesce方法是根据传入的rdd和最大分区数计算出每个新的分区处理哪些旧的分区
pc.coalesce(maxPartitions, prev).zipWithIndex.map {
case (pg, i) => // pg为partitionGroup即旧的partition组成的集合,集合里的partition对应一个新的partition
val ids = pg.partitions.map(_.index).toArray
new CoalescedRDDPartition(i, prev, ids, pg.prefLoc) //组成一个新的parititon
}
}
override def compute(partition: Partition, context: TaskContext): Iterator[T] = {
// 当执行到这里时分区已经重新分配好了,这部分代码也是执行在新的分区的task中的。
// 新的partition取出就的partition对应的所有partition并以此调用福rdd的迭代器执行next计算。
partition.asInstanceOf[CoalescedRDDPartition].parents.iterator.flatMap { parentPartition =>
firstParent[T].iterator(parentPartition, context)
}
}
override def getDependencies: Seq[Dependency[_]] = {
Seq(new NarrowDependency(prev) {
def getParents(id: Int): Seq[Int] =
partitions(id).asInstanceOf[CoalescedRDDPartition].parentsIndices
})
}
override def clearDependencies() {
super.clearDependencies()
prev = null
}
/**
* Returns the preferred machine for the partition. If split is of type CoalescedRDDPartition,
* then the preferred machine will be one which most parent splits prefer too.
* @param partition
* @return the machine most preferred by split
*/
override def getPreferredLocations(partition: Partition): Seq[String] = {
partition.asInstanceOf[CoalescedRDDPartition].preferredLocation.toSeq
}
}对于CoalescedRDD来讲getPartitions方法是最核心的方法。旧的parition对应哪些新的partition就是在这个方法里计算出来的。具体的算法是在DefaultPartitionCoalescer的coalesce方法体现出来的。
compute方法是在新的task中执行的,即分区已经重新分配好,并且拉取父RDD指定parition对应的元素提供给下游迭代器计算。
图示
写下来用两张图解释下是如何repartition
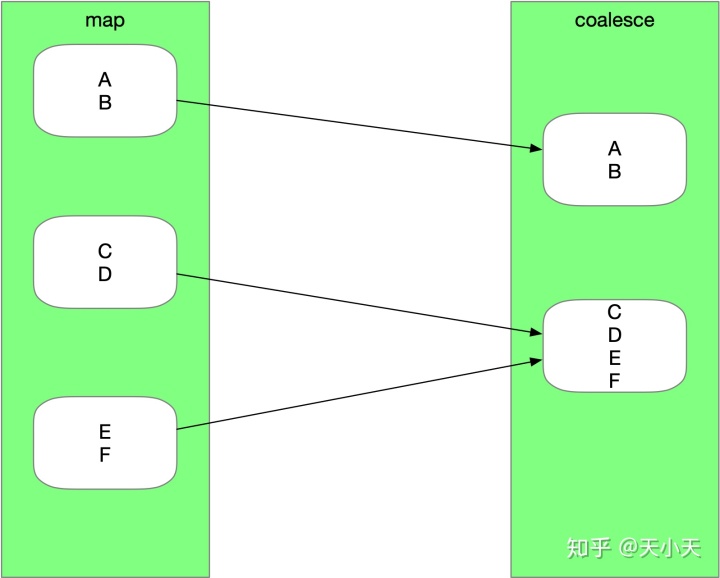
无shuffle
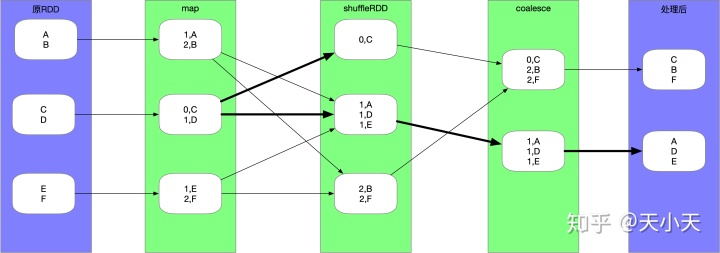
有shuffle
总结
以上repartition的逻辑基本就已经介绍完了。其中DefaultPartitionCoalescer中重新分区的算法逻辑并没有展开说。这里以后如果有时间会再写一篇详细介绍。















 1717
1717











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









