






年轻即出发...
简书:https://www.jianshu.com/u/7110a2ba6f9e
知乎:https://www.zhihu.com/people/zqtao23/posts
GitHub源码:https://github.com/zqtao2332
个人网站:http://www.zqtaotao.cn/ (停止维护更新内容)
QQ交流群:606939954
咆哮怪兽一枚...嗷嗷嗷...趁你现在还有时间,尽你自己最大的努力。努力做成你最想做的那件事,成为你最想成为的那种人,过着你最想过的那种生活。也许我们始终都只是一个小人物,但这并不妨碍我们选择用什么样的方式活下去,这个世界永远比你想的要更精彩。
最后:喜欢编程,对生活充满激情
本节内容预告
本节图
实例1:图的存储方式
实例2:图的遍历:宽度优先遍历
实例3:图的遍历:深度优先遍历
实例4:图的常见算法:拓扑排序算法
实例5:图的常见算法:最小生成树-kruskal算法
实例6:图的常见算法:最小生成树-prim算法
实例1:图的存储方式
1、邻接表
2、邻接矩阵
3、from,to,weight 二维数组
图节点
import java.util.ArrayList;
/**
* @description: 图点,所有的考虑都是把当前节点作为 from
*/
public class Node {
public int value; // 当前节点值
public int in; // 入度:有多少个节点指向我(当前节点)
public int out; // 出度:我指向多少个节点 from ---> to
public ArrayList<Node> nexts; // 我作为from,从我出发能到达的下一级的邻接点的集合。简单说:我的所有邻居点
public ArrayList<Edge> edges; // 我作为from,从我出发能发散的边的集合。简单说:我的所有邻居边
public Node(int value) {
this.value = value;
this.in = 0;
this.out = 0;
this.nexts = new ArrayList<>();
this.edges = new ArrayList<>();
}
}图边
/**
* @description: 图边
*/
public class Edge {
public int weight; // 当前边的权重
public Node from; // 当前边起始点
public Node to; // 当前边尾节点
public Edge(int weight, Node from, Node to) {
this.weight = weight;
this.from = from;
this.to = to;
}
}图
import java.util.HashMap;
import java.util.HashSet;
/**
* @description: 图:就是所有的点集和边集
*/
public class Graph {
/**
* key: 点的编号
* value: 实际对应的Node
*/
public HashMap<Integer, Node> nodes; // 点集
public HashSet<Edge> edges; // 边集
public Graph() {
this.nodes = new HashMap<>();
this.edges = new HashSet<>();
}
}图生成器
/**
* @description: 图生成器
*/
public class GraphGenerator {
public static Graph createGraph(Integer[][] matrix) {
Graph graph = new Graph();
for (int i = 0; i < matrix.length; i++) { // 一位数组代表的是点和点直接的具体数据
Integer from = matrix[i][0];
Integer to = matrix[i][1];
Integer weight = matrix[i][2];
if (!graph.nodes.containsKey(from)) { // from 点不存在
graph.nodes.put(from, new Node(from));
}
if (!graph.nodes.containsKey(to)) { // to 点不存在
graph.nodes.put(to, new Node(to));
}
// 取出from点和to点
Node fromNode = graph.nodes.get(from);
Node toNode = graph.nodes.get(to);
// 构建from 点和to 点之间的边, 建立两点之间的联系
Edge newEdge = new Edge(weight, fromNode, toNode);
fromNode.nexts.add(toNode); // 建立from点和to点的关联
fromNode.out++; // 更新from点的出度
toNode.in++; // 更新to点的入度
fromNode.edges.add(newEdge); // from 点新增边
graph.edges.add(newEdge); // 整个图新增边
}
return graph;
}
}实例2:图的遍历宽度优先遍历:近先,远后
同一级别的点,无分先后。
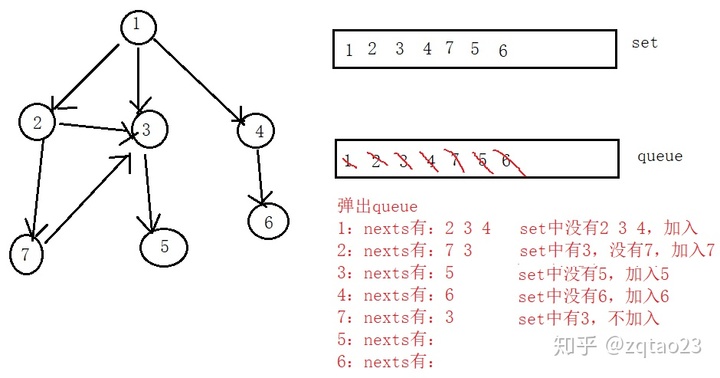
图的宽度优先遍历
1、利用栈实现
2、从源节点开始依次按照宽度进队列,然后弹出
3、每弹出一个点,把该节点所有没有进入过队列的邻接点放入队列
4、直到队列空
import cn.zqtao.learn.day8.graph.Node;
import java.util.HashSet;
import java.util.LinkedList;
import java.util.Queue;
/**
* @description: 宽度优先遍历
*/
public class Code_47_GraphBFS {
public static void bfs(Node node) {
if (node == null) return;
Queue<Node> queue = new LinkedList<>();
// 表示一个点进没进队列,set 是队列的一个注册 ,进过队列的用set保留下来
HashSet<Node> set = new HashSet<>();
queue.add(node);
set.add(node);
while (!queue.isEmpty()) {
Node cur = queue.poll();
System.out.println(cur.value);
for(Node next: cur.nexts) {
if (!set.contains(next)){ // 没有加入到队列的
// 加入并且注册
queue.add(next);
set.add(next);
}
}
}
}
public static void main(String[] args) {
// {from, to, weight}
Integer[][] matrix = {
{1, 2, 3},
{1, 3, 4},
{1, 4, 2},
{2, 7, 1},
{3, 5, 5},
{4, 6, 1}
};
Graph graph = GraphGenerator.createGraph(matrix);
bfs(graph.nodes.get(1));
// 1 2 3 4 7 5 6
}
}实例3:图的遍历:深度优先遍历
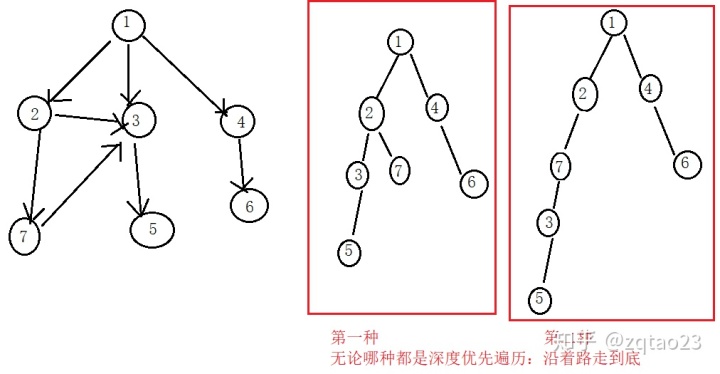
图的深度优先遍历
1、利用栈实现
2、从源节点开始把节点按照深度入栈,然后弹出
3、每弹出一个点,把该节点下一个没有进过栈的邻接点放入栈
4、直到栈空
import cn.zqtao.learn.day8.graph.Node;
import java.util.HashSet;
import java.util.LinkedList;
import java.util.Queue;
import java.util.Stack;
/**
* @description: 深度优先遍历
* 1、利用栈实现
* 2、从源节点开始吧节点按照深度放入栈,然后弹出
* 3、每弹出一个点,把该节点下一个没有进过栈的邻接点放入栈
* 4、直到栈空
*/
public class Code_47_GraphDFS {
public static void dfs(Node node) {
if (node == null) return;
Stack<Node> stack = new Stack<>();
// 表示一个点进没进队列,set 是队列的一个注册 ,进过队列的用set保留下来
HashSet<Node> set = new HashSet<>();
stack.add(node);
set.add(node);
System.out.println(node.value);
while (!stack.isEmpty()){
Node cur = stack.pop();
for(Node next: cur.nexts){
if (!set.contains(next)){ // 只要有一个邻接点不在set中,就break
stack.add(cur);// 重新入栈
stack.add(next);
set.add(next); // 注册next节点
System.out.println(next.value);
break;
}
}
}
}
public static void main(String[] args) {
// {from, to, weight}
Integer[][] matrix = {
{1, 2, 3},
{1, 3, 4},
{1, 4, 2},
{2, 7, 1},
{3, 5, 5},
{4, 6, 1}
};
Graph graph = GraphGenerator.createGraph(matrix);
dfs(graph.nodes.get(1));
// 1 2 7 3 5 4 6
}
}实例4:图的常见算法:拓扑排序算法
拓扑排序算法 适用范围:要求有向图,且有入度为0的节点,且没有环
有向无环图
拓扑排序的应用实例
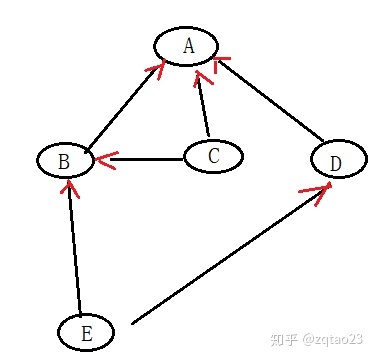
类A依赖于 BCD
类B依赖于 CE
类D依赖于 E
类E 不依赖于其他类, 仅仅给其他类提供支持
类C 不依赖于其他类, 仅仅给其他类提供支持
现在想要编译类A
想编译A,就需要先编译 B C D
想编译B,就需要先编译 C E
想编译D,就需要先编译 E
总结:做一件事必须先做好它的准备工作才能继续进行。
这里类的编译顺序可以是:
E C B D A
注意,顺序不一定,但是肯定是先编译好 E,或者E C,然后才是其他的类
拓扑排序算法实现
先决条件:有向无环
1、找到入度为0 的点
2、去掉入度为0 的点,会出现新的入度为0 的点
3、重复这个过程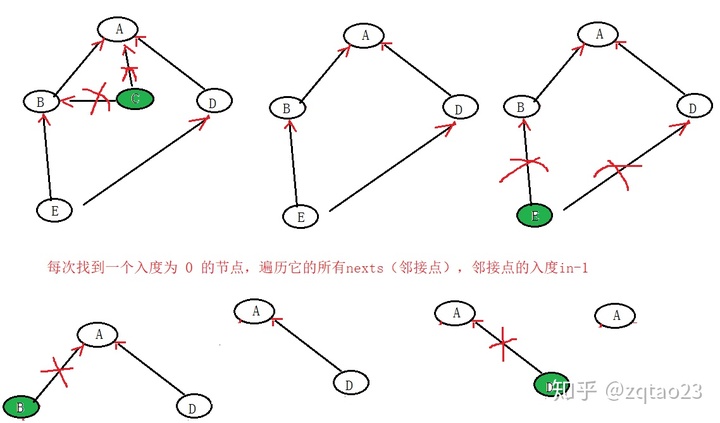
为了方便,将上图 ABCDE 分别换为 12345
矩阵表示
// {from, to, weight}
Integer[][] matrix = {
{2, 1, 3},
{3, 1, 4},
{4, 1, 2},
{3, 2, 1},
{5, 2, 5},
{5, 4, 1}
};
拓扑排序结果
3 5 2 4 1
package cn.zqtao.learn.day8;
import cn.zqtao.learn.day8.graph.Graph;
import cn.zqtao.learn.day8.graph.GraphGenerator;
import cn.zqtao.learn.day8.graph.Node;
import java.util.*;
/**
* @description: 图的常用排序算法:拓扑排序
*/
public class Code_48_GraphTopologySort {
public static List<Node> sortedTopology(Graph graph) {
HashMap<Node, Integer> inMap = new HashMap<>(); // 记录点和点的入度
Queue<Node> zeroInQueue = new LinkedList<>();// 0 入度队列,弹出顺序就是拓扑排序的顺序
for (Node node : graph.nodes.values()) { // 取出所有的节点
inMap.put(node, node.in); // key : node value: in
if (node.in == 0) {
zeroInQueue.add(node);// node的入度为0,如队列
}
}
List<Node> res = new ArrayList<>();
while (!zeroInQueue.isEmpty()) {
Node zeroInNode = zeroInQueue.poll(); // 弹出队列中入度为0的节点
res.add(zeroInNode);
for (Node next : zeroInNode.nexts) { // 遍历它所有的邻接节点
inMap.put(next, inMap.get(next) - 1);
if (inMap.get(next) == 0) { // 当邻接节点入度为0时,如队
zeroInQueue.add(next);
}
}
}
return res;
}
public static void main(String[] args) {
// {from, to, weight}
Integer[][] matrix = {
{2, 1, 3},
{3, 1, 4},
{4, 1, 2},
{3, 2, 1},
{5, 2, 5},
{5, 4, 1}
};
Graph graph = GraphGenerator.createGraph(matrix);
List<Node> nodes = sortedTopology(graph);
for(Node n: nodes)
System.out.println(n.value);
// 3 5 2 4 1
}
}实例5:图的常见算法:最小生成树-kruskal算法
最小生成树:在保证图所有的点都连通的情况下,需要的权重最小的边的集合。
1、所有点联通
2、权值总和最低
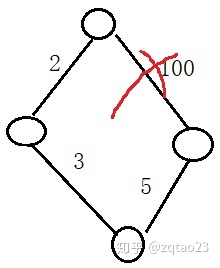
如图联通4个点,只需要2 3 5 三个边就行,100权重的边可以去掉。
1、图的几个点之间不需要联通成环
2、并查集:点与点之间是否属于同一个集合
3、kruskal算法针对的是边,一个边产生两个有效点
import cn.zqtao.learn.day8.graph.Edge;
import cn.zqtao.learn.day8.graph.Graph;
import cn.zqtao.learn.day8.graph.Node;
import java.util.*;
/**
* @description: 并查集解决图的 kruskal 算法
* @version: 1.0
*/
public class Code_49_KruskalMST_By_UnionFindSet {
public static class UnionFindSet {
public HashMap<Node, Node> fatherMap;
public HashMap<Node, Integer> sizeMap;
public UnionFindSet() {
this.fatherMap = new HashMap<>();
this.sizeMap = new HashMap<>();
}
// make sets
public void makeSets(Collection<Node> nodes) {
this.fatherMap.clear();
this.sizeMap.clear();
for (Node node : nodes) {
this.fatherMap.put(node, node);
this.sizeMap.put(node, 1);
}
}
// 是否是同一个个集合
public boolean isSameSet(Node a, Node b) {
return findHead(a) == findHead(b);
}
// 查找代表节点(父节点等于子节点),同时对结构进行扁平化
public Node findHead(Node node) {
Node fatherNode = this.fatherMap.get(node);
if (fatherNode != node) { // 不是代表节点,继续递归
fatherNode = findHead(fatherNode);
}
this.fatherMap.put(node, fatherNode);// 扁平化处理
return fatherNode;
}
// 合并两个节点所在的集合
public void union(Node a, Node b) {
Node headA = findHead(a);
Node headB = findHead(b);
if (headA != headB) {
Integer sizeA = this.sizeMap.get(headA);
Integer sizeB = this.sizeMap.get(headB);
if (sizeA >= sizeB) { // 短链挂长链
this.fatherMap.put(headB, headA);
this.sizeMap.put(headA, sizeA + sizeB);
} else {
this.fatherMap.put(headA, headB);
this.sizeMap.put(headB, sizeA + sizeB);
}
}
}
}
// 边,小根堆比较器
public static class MinEdgeComparator implements Comparator<Edge> {
@Override
public int compare(Edge o1, Edge o2) {
return o1.weight - o2.weight;
}
}
// kruskal 算法求最小生成树
public static Set<Edge> kruskalMST(Graph graph) {
UnionFindSet unionFindSet = new UnionFindSet();
unionFindSet.makeSets(graph.nodes.values()); // 所有节点加入并查集
// 小根堆
PriorityQueue<Edge> edgePriorityQueue = new PriorityQueue<>(new MinEdgeComparator());
for (Edge edge : graph.edges) { // 所有边,入小根堆
edgePriorityQueue.add(edge);
}
Set<Edge> res = new HashSet<>();
while (!edgePriorityQueue.isEmpty()) {
Edge minEdge = edgePriorityQueue.poll();
if (!unionFindSet.isSameSet(minEdge.from, minEdge.to)) { // 不是同一个集合,即没有形成环路
res.add(minEdge);
unionFindSet.union(minEdge.from, minEdge.to);
}
}
return res;
}
public static void main(String[] args) {
Integer[][] graphMatrix = {
{1,2,6},
{1,3,1},
{1,4,5},
{2,1,6},
{2,3,5},
{2,5,3},
{3,1,1},
{3,2,5},
{3,4,5},
{3,5,6},
{3,6,4},
{4,1,5},
{4,3,5},
{4,6,2},
{5,2,3},
{5,3,6},
{5,6,6},
{6,3,4},
{6,4,2},
{6,5,6},
};
Graph graph = GraphGenerator.createGraph(graphMatrix);
Set<Edge> kruskalMST = kruskalMST(graph);
Iterator<Edge> iterator = kruskalMST.iterator();
while (iterator.hasNext()) {
Edge next = iterator.next();
System.out.println("from : " + next.from.value + " to : " + next.to.value + " weight : " + next.weight);
}
}
}测试图
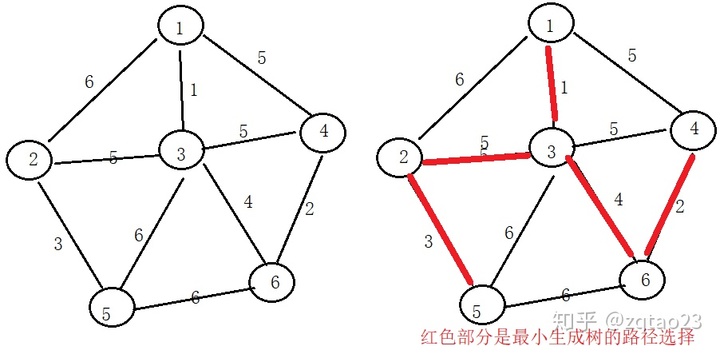
测试结果
from : 6 to : 4 weight : 2
from : 5 to : 2 weight : 3
from : 6 to : 3 weight : 4
from : 2 to : 3 weight : 5
from : 1 to : 3 weight : 1实例6:图的常见算法:最小生成树-prim算法
1、prim算法针对的是点,每次选取一个最短边,产生一个有效点
2、每一个有效点会解锁新的邻接边
import cn.zqtao.learn.day8.graph.Edge;
import cn.zqtao.learn.day8.graph.Graph;
import cn.zqtao.learn.day8.graph.GraphGenerator;
import cn.zqtao.learn.day8.graph.Node;
import java.util.*;
/**
* @auther: zqtao
* @description: 图最小生成树:prim算法
* @version: 1.0
*/
public class Code_50_PrimMST {
// 最小权重边,小根堆比较器
public static class MinEdgeComparator implements Comparator<Edge> {
@Override
public int compare(Edge o1, Edge o2) {
return o1.weight - o2.weight;
}
}
public static Set<Edge> primMST(Graph graph){
HashSet<Node> set = new HashSet<>(); // 注册节点:哪些节点已经选取过
PriorityQueue<Edge> queue = new PriorityQueue<>(new MinEdgeComparator()); // 小根堆,每次弹出可选边中最小权重值的边
Set<Edge> res = new HashSet<>();
// 任意选取一点 node --> v1
Node randNode = graph.nodes.get(1); // 这里为了方便选取 节点值为 1 的点
if (!set.contains(randNode)){
set.add(randNode);
for(Edge edge: randNode.edges) { // 解锁该节点的所有可选临边
queue.add(edge);
}
while (!queue.isEmpty()) {
Edge minEdge = queue.poll();
Node to = minEdge.to;
if (!set.contains(to)) {
set.add(to);
res.add(minEdge);
for (Edge nextEdge: to.edges) {
queue.add(nextEdge);
}
}
}
}
return res;
}
public static void main(String[] args) {
Integer[][] graphMatrix = {
{1,2,6},
{1,3,1},
{1,4,5},
{2,1,6},
{2,3,5},
{2,5,3},
{3,1,1},
{3,2,5},
{3,4,5},
{3,5,6},
{3,6,4},
{4,1,5},
{4,3,5},
{4,6,2},
{5,2,3},
{5,3,6},
{5,6,6},
{6,3,4},
{6,4,2},
{6,5,6},
};
Graph graph = GraphGenerator.createGraph(graphMatrix);
Set<Edge> primMST = primMST(graph);
Iterator<Edge> iterator = primMST.iterator();
while (iterator.hasNext()) {
Edge next = iterator.next();
System.out.println("from : " + next.from.value + " to : " + next.to.value + " weight : " + next.weight);
}
}
}测试结果
from : 6 to : 4 weight : 2
from : 5 to : 2 weight : 3
from : 6 to : 3 weight : 4
from : 2 to : 3 weight : 5
from : 1 to : 3 weight : 108_算法初级_图论.md














 1623
1623











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









