





1.传统的Hash
不管是做开发的同学,还是做DBA的同学,对Hash肯定不陌生。这里先回顾一下传统Hash的特性。 Hash解决了什么问题呢? 它解决的是查询的速度问题。比如从一张表中,查找到自己想要的那行数据,最直接的方法就是全表扫描,但这种方法太慢。原因是,从第一行数据查到最后一行,这个链条太长了。
有没有办法缩短这个查询链条呢?Hash就可以。 Hash为何能加快查询?

如果用Hash算法来实现索引,你会发现, 实现简单,查询迅速 。因为Hash算法是一个非常简单高效的算法。
但为啥主流数据库都采用BTree/变种BTree算法来实现索引,而不采用Hash算法来实现索引呢?
因为Hash算法本身有着它固有的缺点。 Hash算法的缺点1:
Hash提高查询速度的原因就是能够将长链表切成短链表,分散在每个Hash bucket上面的链表非常短,查询效率非常高。但是随着数据越来越多, 分散在每个Hash bucket上面的链表也越来越长,查询效率会越来越低 。 Hash算法的缺点2:
为了解决数据量增多,导致分散在每个Hash bucket上面的链表太长的问题,可以进行Hash bucket数量扩展。但扩展过程中,必须销毁原Hash表,将所有数据重新进行Hash运算,再放到对应的buckect中,形成新的Hash表。 这个扩展/缩小Hash bucket数量的操作,会大量的消耗资源 ,造成一定时间的卡顿。 Hash bucket的数量选择
从Hash算法的缺点,可以看出,选择合适的Hash bucket非常关键。
- Hash bucket少,数据量多,会导致bucket中的链表过长
- Hash bucket多,数据量少,会导致空间的浪费
数据量总是变化的,那么有没有方法能够动态扩展/缩小Hash bucket呢? 而且这个扩展和缩小要足够的丝滑,不会产生任何卡顿。
2.Mysql的动态Hash
阅读Mysql源码的时候发现,Mysql实现了一个动态Hash算法,它就能 在数据量不断变化的情况下,丝滑的动态扩展和缩小Hash bucket 。 动态Hash介绍 动态Hash算法的核心是,有多少数据,就分配多少内存,Hash bucket动态变化,Hash bucket的链表也会动态变化。 Hash bucket有两个动态Hash有两个Hash bucket,一个小于等于当前数据量,一个大于当前数量,都是2的倍数。
- 假设当前数据量为3,则小的Hash bucket为2,大的Hash bucket为4。
- 假设当前数据量为4,则小的Hash bucket为4,大的Hash bucket为8。
- 小的Hash bucket用来计算是否要移动旧数据。
- 大的Hash bucket用来计算新数据放在哪里。
扩展新的内存。
- 使用小Hash bucket计算特定位置数据的hash值,为0表示低位,还是在原位置上,不需要移动,否则需要移动,将该数据移动到新扩展的内存中。
- 使用大Hash bucket计算要插入的新数据的hash值,如果那个位置是empty(可能是新内存地址,也可能是旧数据移动后的内存地址),则直接放入即可。
- 如果不是empty(存在一个旧数据),则移动旧数据到empty位置上,将新数据放入旧数据的位置上。
- 计算新数据和旧数据的hash值是否一样,一样的话,将两个数据串在一个链表上。
- 如果不一样,则将新数据串到相同hash值链表的最后一个数据上。
- 初始的时候,没有数据,也没有给动态Hash分配任何的内存。
- 这个时候,来了一个数据A:

- 于是分配了一块内存,用来存放A,Hash表的数据量为1。此时,又来了一个数据B:

- 将A按照1取模,发现A不用动,然后将B按照2取模,得出应该放在位置2的内存上。于是新分配了一个内存,将B放入,Hash表的数据量为2。此时来了数据C:
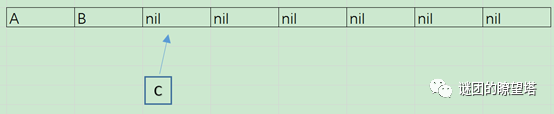
- 此时,算法将A按照2取模,发现A不用动,然后C按照4取模,得出应该放在位置3的内存上。于是新分配了一个内存,将C放入,Hash表的数据量为3。此时又来了一个重复的数据A:
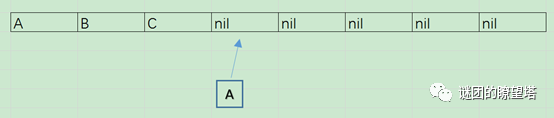
- 此时,算法将B按照2取模,发现B需要移动,则新分配一块内存,将B移动到新内存中:
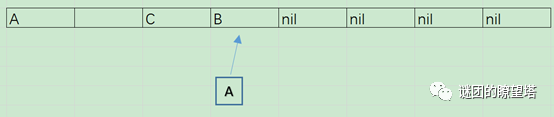
- 接着,对新数据A按照4取模,发现A要放到位置2的内存里,直接放入,同时将两个A串成链表,Hash表的数据量为4。此时又来了新数据D:
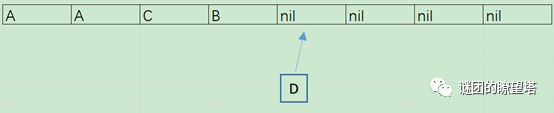
- 算法将内存位置1的A按照4取模,判断需要进行移动,然后分配新的内存,将A放入新内存中:
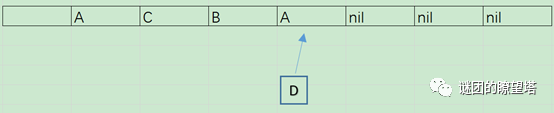
- 然后将新数据D按照8取模,发现要放到内存位置2中,但此时,内存位置2有一个旧数据A,所以要移动位置2的A数据到empty的内存位置1中,同时将D放入内存位置2中:

以上就是动态Hash算法,新增数据的示例。 可以发现,新来多少数据,就分配多少内存,同时,Hash bucket会随着数据量的增大而动态增大。
如果是删除数据的话,也是同样的算法,倒着做就可以了。 算法的优缺点
动态Hash算法的优点是,解决了在数据量不断变化的情况下,固定的Hash bucket大小带来的各种问题。
动态Hash算法的CPU耗费也很小,增减数据的时候,只需要2次Hash计算,再有几次指针修改而已,保证整个过程足够的丝滑,不卡顿。
缺点是算法较为复杂,理解起来需要耗费好大的时间和精力。
3.动态Hash算法模拟代码
以下是参考mysql源码,将源码简化后的动态Hash算法模拟代码,感兴趣的童鞋可以尝试一下:#include
main()
{int LOWFIND=1;int LOWUSED=2;int HIGHFIND=4;int HIGHUSED=8;/* 程序用的变量 */int flag,outputflag;int idx,halfbuff,first_index;int ptr_to_rec,ptr_to_rec2;int data,empty,gpos,gpos2,pos;int hash_nr_new = 0;
data = 0;printf("\n===需要修改的值===\n");/*第一次设置*/int blength=4; /* 当前的blength */int records=3; /* 当前的record */int hash_nr=4; /* 要插入元素的hash_nr *//*重新输入*/int inputflag1=2; /*0为不修改,1为第一次移动,2为循环*/int inputflag3=0; /*0为不修改,1为插入*/int pos_new1=1;int hash_nr_new1=3;int flag_new_loop=0;int empty_new_loop=0;int pos_new_loop=0;int hash_nr_new_loop=0;int hash_nr_new_insert=1;
flag = 0;
empty = records; /*empty为新分配的内存的地址*/
hash_nr_new=hash_nr;/*alloc_dynamic:为下一个元素分配内存空间,并返回下一个元素的起始地址*/printf("empty为新分配的内存的地址\n");printf("empty=%d\n",empty);printf("\n===要插入的元素hashcode和hash值===\n");int mask_value;printf("blength=%d\n",blength);printf("records=%d\n",records);printf("hash_nr=%d\n",hash_nr);printf("flag=%d\n",flag);printf("\n===开始移动元素===\n");
halfbuff= blength >> 1;
idx=first_index=records-halfbuff;printf("halfbuff=%d\n",halfbuff);printf("idx=first_index=%d\n",idx);printf("\n-判断1:idx != records \n");if (idx != records)
{printf("\n--判断1为true,array中有元素,继续 \n");
pos=data+idx;if (inputflag1==1) /*移动的重新输入*/
{printf("===第一次移动:重新输入pos和hash_nr值===\n");
pos = pos_new1;
hash_nr = hash_nr_new1;
}if (inputflag1==2) /*循环的重新输入*/
{printf("===循环:重新输入flag,empty,pos和hash_nr值===\n");
flag = flag_new_loop;
empty = empty_new_loop;
pos = pos_new_loop;
hash_nr = hash_nr_new_loop;
}if ((hash_nr & (blength-1)) {
mask_value = hash_nr & (blength-1);
}else
{
mask_value = hash_nr & ((blength >> 1) -1);
}printf("pos=%d---计算出来的pos\n",pos);printf("pos.hash_nr=%d\n",hash_nr);printf("pos.mask_value=%d\n",mask_value);if (flag==0)
{printf("\n--flag=0,判断pos.mask_value != first_index\n");printf("");if (mask_value != first_index)
{printf("判断为true,此处应该break\n");
}else {printf("判断为false,继续\n");
}
}printf("\n--判断case:!(hash_nr & halfbuff) \n");if (!(hash_nr & halfbuff))
{printf("\n---判断case为true,低位,进入case1 \n");printf("\n---判断case1:!(flag & LOWFIND) \n");if (!(flag & LOWFIND))
{printf("\n----判断case1为true,进入case1-a:同样的hash掩码,在低位还没有出现过 \n");printf("\n----判断case1-a:flag & HIGHFIND \n");if (flag & HIGHFIND)
{printf("\n-----判断case1-a为true,进入case1-a-1:在低位没有出现,但是过在高位出现了,这时只需要把这个元素恢复到空闲的位置 \n");
flag=LOWFIND | HIGHFIND;/* key shall be moved to the current empty position */
gpos=empty;
ptr_to_rec=pos;
empty=pos;printf("flag=LOWFIND | HIGHFIND=%d \n",flag);printf("gpos=empty:gpos为empty的位置 \n");printf("ptr_to_rec=pos->data \n");printf("empty=pos:empty为pos的位置 \n");
}else
{printf("\n-----判断case1-a为false,进入case1-a-2:表示低位没有出现过,高位也没有出现,那么当前的元素保持当前的位置 \n");
flag=LOWFIND | LOWUSED; /* key isn't changed */
gpos=pos;printf("flag=LOWFIND | LOWUSED;=%d \n",flag);printf("gpos=pos \n");printf("ptr_to_rec=pos->data \n");
}
}else
{printf("\n----判断case1为false,进入case1-b:表示当前元素的前一个低位元素占据新的空闲的位置 \n");printf("\n----判断case1-b:!(flag & LOWUSED) \n");if (!(flag & LOWUSED))
{printf("\n-----判断case1-b为true,进入case1-b-1 \n");/* Change link of previous LOW-key */
flag= (flag & HIGHFIND) | (LOWFIND | LOWUSED);printf("flag=(flag & HIGHFIND) | (LOWFIND | LOWUSED)=%d \n",flag);printf("gpos->data=ptr_to_rec \n");printf("gpos->next= (uint) (pos-data):修改next指针,指向low-key \n");
}
gpos=pos;printf("gpos=pos \n");printf("ptr_to_rec=pos->data \n");
}
}else
{printf("\n---判断case为false,高位,进入case2 \n");printf("\n---判断case2:!(flag & HIGHFIND) \n");if (!(flag & HIGHFIND))
{printf("\n----判断case2为true,进入case2-a:如果之前没有出现过高位元素,那么就把当前元素放到空闲的位置,如果不是第一个高位元素,就不需要移动了 \n");
flag= (flag & LOWFIND) | HIGHFIND;/* key shall be moved to the last (empty) position */
gpos2 = empty;
empty=pos;printf("flag= (flag & LOWFIND) | HIGHFIND=%d \n",flag);printf("gpos2 = empty:gpos2为empty的位置 \n");printf("empty=pos:empty为pos的位置 \n");printf("ptr_to_rec2=pos->data\n");
}else
{printf("\n----判断case2为false,进入case2-b:这种情况类似于1-b,就是设置第一个高位元素的next指针到第二个元素,后面的next指针都正确,不用管 \n");printf("\n----判断case2-b:!(flag & HIGHUSED) \n");if (!(flag & HIGHUSED))
{printf("\n-----判断case2-b为false,进入case2-b-1 \n");/* Change link of previous hash-key and save */
flag= (flag & LOWFIND) | (HIGHFIND | HIGHUSED);printf("flag= (flag & LOWFIND) | (HIGHFIND | HIGHUSED)=%d \n",flag);printf("gpos2->data=ptr_to_rec2 \n");printf("gpos2->next=(uint) (pos-data):修改next指针 \n");
}
gpos2=pos;printf("gpos2=pos \n");printf("ptr_to_rec2=pos->data \n");
}
}printf("flag=%d \n",flag);printf("\n--判断1-y:(flag & (LOWFIND | LOWUSED)) == LOWFIND \n");
outputflag = flag & (LOWFIND | LOWUSED);if (outputflag == LOWFIND)
{printf("\n---判断为1-y为true \n");printf("gpos->data=ptr_to_rec\n");printf("gpos->next=NO_RECORD\n");
}printf("\n--判断1-z:(flag & (HIGHFIND | HIGHUSED)) == HIGHFIND \n");
outputflag = flag & (HIGHFIND | HIGHUSED);if (outputflag == HIGHFIND)
{printf("\n---判断1-z为true \n");printf("gpos2->data=ptr_to_rec2:重新给gpos2的位置赋予元素\n");printf("gpos2->next=NO_RECORD\n");
}
}else
{printf("-判断1为false,array中无元素 \n");
}printf("\n===插入元素===\n");printf("===record+1,计算新元素的hash值===\n");
records = records + 1;if ((hash_nr_new & (blength-1)) {
mask_value = hash_nr_new & (blength-1);
}else
{
mask_value = hash_nr_new & ((blength >> 1) -1);
}printf("blength=%d\n",blength);printf("records=%d\n",records);printf("hash_nr_new=%d\n",hash_nr_new);printf("idx= mask_value=%d\n",mask_value);
idx = mask_value;
pos=data+idx;printf("pos=%d---计算出来的pos\n",pos);printf("empty=%d\n",empty);printf("\n-判断c:pos == empty \n");if (pos == empty)
{printf("\n--判断c为true,直接把元素放入到empty中 \n");printf("pos->data=(uchar*) record\n");printf("pos->next=NO_RECORD\n");
}else
{printf("\n--判断c为false \n");printf("empty[0]=pos[0],要移动元素,把当前pos里的元素放入empty中 \n");/* Check if more records in same hash-nr family */printf("gpos= data + my_hash_rec_mask(info, pos, info->blength, info->records + 1)\n");printf("===需要重新输入hash_nr值,以计算pos位置元素的hash mask\n");if (inputflag3==1) /*插入的重新输入*/
{
hash_nr = hash_nr_new_insert;
}if ((hash_nr & (blength-1)) {
mask_value = hash_nr & (blength-1);
}else
{
mask_value = hash_nr & ((blength >> 1) -1);
}
gpos = mask_value;printf("pos.hash_nr=%d\n",hash_nr);printf("gpos=pos.mask_value=%d\n",mask_value);if (pos == gpos)
{printf("pos = gpos ,掩码相同,插入元素到pos位置,同时把pos位置的next指针指到empty中的元素\n");printf("pos->data=(uchar*) record\n");printf("pos->next=(uint) (empty - data)\n");
}else
{printf("pos != gpos ,掩码不同,插入元素到pos位置,并把元素放在gpos的最后一个元素的next后面\n");printf("pos->data=(uchar*) record\n");printf("pos->next=NO_RECORD\n");printf("movelink(data,(uint) (pos-data),(uint) (gpos-data),(uint) (empty-data))\n");
}
}printf("\n--如果records+1达到了blength,则blength翻倍 \n");if (records == blength)
blength+= blength;printf("records=%d\n",records);printf("blength=%d\n",blength);
}














 6645
6645











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









