






【多任务】能同时并发地交互执行多个进程的OS。无论在单处理器or多处理器上,多任务OS都能使多个进程处于阻塞or睡眠状态,即实际上不被投入执行直到工作确实就绪。可以划分以下2类:
1.非抢占式任务cooperative multitasking:除非进程自己主动停止运行,否则它会一直执行。 进程主动挂起自己的操作称为让步yielding。理想情况下,进程通常做出让步,以便让每个可运行进程享有足够的处理器时间。 ~缺点:调度程序无法对每个进程该执行多长时间做出统一规定,所以进程独占的CPU时间可能超出用户的预料;更坏的情况是一个决不做出让步的悬挂进程使系统崩溃。 例如Mac OS9、Windows 3.1采用此方式。 2.抢占式任务preemptive multitasking:由调度程序来决定什么时候停止一个进程的运行,以便其他进程能够得到机会。 进程在被抢占之前能够运行的时间是预先设置好的,即进程的时间片timeslice(分配给每个可运行进程的CPU时间段)。有效管理timeslice能使调度程序从系统全局的角度做出调度决定。 像所有Unix的变体和许多其他现代OS一样,Linux提供了抢占式多任务模式。 |
⚠️️Linux2.5内核采用了时间复杂度为O(1)的新调度程序。O(1)调度器虽然在拥有数以十计的多处理器环境下尚能表现出近乎完美的性能和可扩展性。但是时间证明该调度算法对于调度那些响应时间敏感的程序却有一些先天不足。
Linux2.6采用CFS(完全公平调度算法)为了提高对交互程序的调度性能引入新的调度算法—反转楼梯最后期限调度算法RSDL(Rotating StaircaseDeadline scheduler),该算法汲取了队列理论,将公平调度理念引入Linux调度程序。
策略决定调度程序在何时让什么进程运行。
I/O消耗型:进程的大部分时间用来提交I/O请求or等待I/O请求。 这样的进程经常处于可运行状态,但通常会运行一会儿。因为它在等待更多的I/O请求(如键盘输入、网络I/O等)时最后总会阻塞。 多数用户图形界面程序GUI都属于I/O密集型,即使从不读取or写入磁盘,也会在多数时间里等待来自鼠标or键盘的用户交互操作。 处理器消耗型:进程把时间大多用在执行代码上。 除非被抢占,否则它们通常都一直不停地运行,因没有太多的I/O需求。因为它们不属于I/O驱动类型,所以从系统响应速度考虑,调度器不应该经常让它们运行。 【调度策略】尽量降低它们的调度频率,而延长其运行时间。其极端就是无限循环地执行。代表例子如那些执行大量数学计算程序,sshkeygen或MATLAB ~I/O消耗 or 处理器消耗? A.X Window服务器既是I/O消耗型,也是处理器消耗型。 B.字处理器进程是I/O消耗型,但属于处理器消耗型活动的范围。其通常坐以等待键盘输入,但在任一时刻可能又粘住处理器疯狂的进行拼写检查or宏计算。 进程响应迅速(响应时间短)和最大系统利用率(高吞吐量)寻找平衡。 ~Unix系统的调度程序更倾向于I/O消耗型程序,以提供更好的程序响应速度。 ~Linux为了保证交互式应用和桌面系统的性能,所以对进程的响应做了优化(缩短响应时间),更倾向于优先调度I/O消耗型进程。 |
进程优先级:根据进程的价值和其对处理器时间的需求来对进程分级 做法:(并未被Linux系统完全采用)优先级高的进程先运行,低的后运行,相同优先级的进程按轮转方式进行调度(一个接一个,重复进行)。在某些系统中,优先级高的进程使用的时间片timeslice也较长。调度程序总是选择时间片timeslice未用尽而且优先级最高的进程运行。用户和系统都可以通过设置进程的优先级来影响系统的调度。Linux采用了两种不同的优先级范围,如下:
|
时间片:表明进程在被抢占前所能持续运行的时间,默认10ms 调度程序必须规定一个默认的时间片。多长为好?太长响应欠佳:太短消耗CPU。 ⚠️I/O消耗型不需要长timeslice;处理器消耗型则timeslice越长越好。 Linux的CFS调度器并没有直接分配时间片到进程,而是将处理器的使用比划分给了进程。这样进程所获得得处理器时间其实是和系统负载密切相关的。nice值作为权重将调整进程所使用的处理器时间使用比。
Linux系统是抢占式的,且Linux 中使用新CFS完全公平调度器,其抢占时机取决于新的可运行程序消耗了多少处理器使用比。若消耗的使用比< 当前进程,则新进程立刻投入运行,抢占当前进程。否则将推迟其运行。 |
【Linux调度算法】
1.调度器类 Linux调度器是以模块方式提供的,目的是允许不同类型的进程可以有针对性地选择调度算法。 scheduler classes 调度器类允许多种不同的可动态添加的调度算法并存,调度属于自己范畴的进程。每个调度器都有一个优先级,基础的调度器代码定义在kernel/sched.c文件中,它会按照优先级顺序遍历调度器类,拥有一个可执行进行的最高优先级的调度器类胜出。 完全公平调度CFS是一个针对普通进程的调度类,Linux中称为SCHED_NORMAL,CFS算法实现定义在文件kernel/sched_fair.c中。 |
2.Unix系统中的进程调度 在Unix系统上,优先级以nice值形式输出给用户空间。分配绝对的时间片引发的固定的切换频率,给公平性造成了很大变数。 CFS采用的方法是对时间片timeslice分配方式进行根本性的重新设计(就进程调度器而言)即完全摒弃时间片而是分配给进程一个处理器使用比重!。通过这种方式,CFS确保了进程调度中能有恒定的公平性,而将切换频率置于不断变动中。 |
3.公平调度 CFS出发点是进程调度的效果应如系统具备一个理想中的完美多任务处理器。在这种系统中,每个进程将能获得1/n的处理器时间,其中n是指可运行进程的数量。若有2个运行进程,理想情况下,同时运行这两个进程且各自使用50%的处理器。 CFS允许每个进程运行一段时间、循环轮转、选择运行最少的进程作为下一个运行进程,而不再采用分配给每个进程timeslice方式,在所有可运行进程总数基础上计算出一个进程应该运行多久,而不是依靠nice值来计算时间片。nice值在CFS中被作为进程获得的处理器运行比的权重:
⚠️CFS限制了每个进程获得的时间片底线即最小粒度,默认情况下是1ms。绝对的nice值不再影响调度决策:只有相对值才会影响处理器时间的分配比列。 |
【Linux调度实现】
1.时间记账 所有的调度器都必须对进程运行时间做记账。多数Unix系统会分配一个时间片给每一个进程。当一个进程的时间片被减少到0时,就会被另一个尚未减到0的时间片可运行进程抢占。 A.调度器实体结构 CFS不再有timeslice,但它必须维护每个进程运行的时间记账,因为它需要确保每个进程只在公平分配给它的处理器时间内运行。如下:
B.虚拟实时(单位为ns) vruntime变量存放进程的虚拟运行时间,该运行时间(花在运行上的时间和)的计算是经过了所有可运行进程总数的标准化。优先级相同的所有进程的虚拟运行时间都是相同的—所有任务都将接收到相等的处理器份额。
| ||||
2.进程选择 算法核心~当CFS要选择下一个运行进程时,会挑一个具有最小vruntime的进程。 CFS采用自平衡二叉搜索树的红黑树rbtree组织可运行进程队列,并利用其迅速找最小vruntime值的进程。 A.挑选下一个任务 运行rbtree中最左边叶子结点所代表的那个进程,_pick_next_entity()函数:
B.向Tree中加入进程 发生在进程变为可运行状态(被唤醒) or 通过fork()调用第一次创建进程时。
其中缓存rb->leftmost为A步骤中的参数。 C.从Tree中删除进程 删除动作发生在进程阻塞(变为不可运行态)or终止时(结束运行)。
| ||||
3.调度器入口 进程调度的主要入口点是scheduler()函数,在kernel/sched.c文件中。选择哪个进程可以运行,何时将其投入运行。该函数会找到一个最高优先级的调度类,pick_next_task()会以优先级有序,从高到低,依次检查每一个调度类,并且从最高优先级的调度类中选择最高优先级的进程:
函数优化:因CFS是普通进程的调度类,而系统运行的绝大多数进程都是普通进程。 前提条件:所有可运行进程数量 = CFS类对应的可运行进程数 | ||||
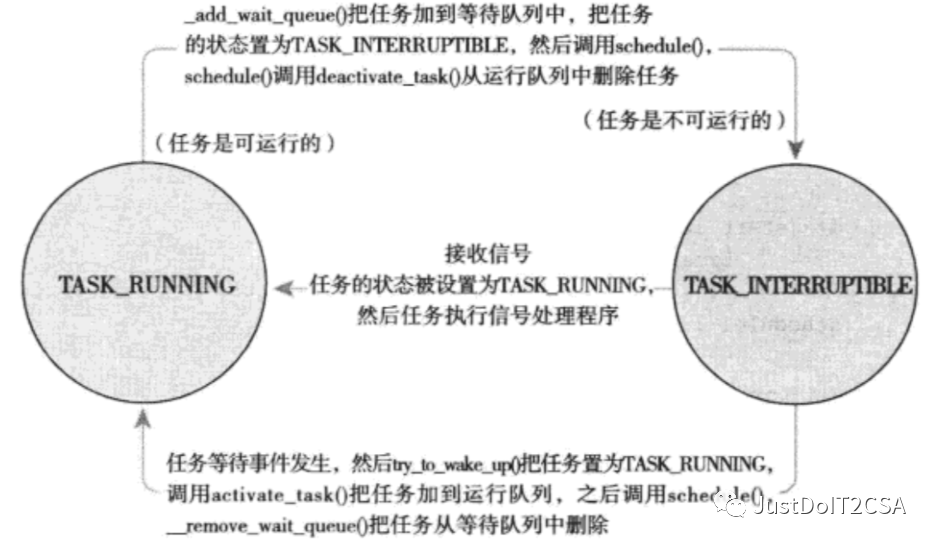
4.睡眠和唤醒 1.睡眠 因文件I/O(read()需从磁盘读取)、键盘输入等,进程会标记为休眠状态,从可执行红黑树中移出,放入等待队列,然后调用scheduler()选择和执行一个其他进程。 进程被设置为可执行状态,然后再从等待队列中移到可执行红黑树中。——唤醒
A.等待队列:由等待某些事件发生的进程组成的简单链表。 内核用wake_queue_head_t来代表等待队列,可通过DECLARE_WAITQUEUE()静态创建,也可由init_waitqueue_head()动态创建。
进程通过执行以下步骤加入到一个等待队列中:
等待队列典型用法:fs/notify/inotify/inotify_user.c中的inotify_read函数负责从通知文件描述符中读取信息。
⚠️mutex_lock和mutex_unlock函数,想到了DCL-Double Check Lock。 2.唤醒 通过wake_up()函数唤醒制定的等待队列上的所有进程。调用try_to_wake_up()将进程设置为TASK_RUNNING状态,调用enqueue_task()将此进程放入红黑树rbtree中,若被唤醒的进程优先级 > 当前执行的进程的优先级,要设置need_resched标志。 通常哪段代码促使等待条件满足,它就要负责随后调用wake_up函数。 |















【抢占和上下文切换】
上下文切换:从一个可执行进程切换到另一个可执行进程,由kernel/sched.c中的context_switch()函数负责。主要完成:
1.调用声明在中的switch_mm(),负责把虚拟内存从上一个进程映射切换到新进程中。
2.调用声明在中的switch_to(),负责从上一个进程的处理器状态切换到新进程的处理器状态。包含保存、恢复栈信息和寄存器信息,以及其他任何与体系结构相关的状态信息,都必须以每个进程为对象进行管理和保存。
内核通过need_resched标志来表明是否需要重新执行一次调度。当某个进程应被抢占时,scheduler_tick()就会设置这个标志;当一个优先级高的进程进入可执行状态时,try_to_wake_up()会设置这个标志,内核检查该标志确认其被设置,调用scheduler()切换到一个新的进程。
函数 | 目的 |
set_tsk_need_resched() | 设置指定进程中的need_resched标志 |
clear_tsk_need_resched() | 消除指定进程中的need_resched标志 |
need_resched() | 检查need_resched标志的值 若设置则返回真,否则返回假 |
⚠️每个进程都包含一个need_resched标志,因为访问进程描述符内的数值要比访问一个全局变量快(因为current宏速度很快且描述符通常都在高速缓存中)。
【用户抢占】 内核即将返回用户空间时,若need_resched标志被设置,会导致scheduler()被调用,此时会发生用户抢占。以下情况会发生用户抢占:
|
【内核抢占】 Linux完整地支持内核抢占,可在任何时间抢占正在执行的task。 ~什么时候重新调度才是安全的呢?~ 答:只要没有持有锁,内核就可以进行抢占。 thread_info中的preempt_count计数器表示使用锁的次数。若从中断返回内核空间时,内核会检查need_resched和preempt_count值,情况如下:
内核抢占会发生在如下情况:
|
【实时调度策略】
Linux提供了2种实时调度策略:SCHED_FIFO和SCHED_RR。普通的、非实时的调度策略是SCHED_NORMAL。
SCHED_FIFO实现了一种简单的、先入先出的算法:它不使用时间片timeslice。 处于可运行状态的SCHED_FIFO级的进程会比任何SCHED_NORMAL级的进程都先得到调度,由于它不基于时间片可一直执行下去。只有更高优先级的SCHED_FIFO or SCHED_RR任务才能抢占SCHED_FIFO任务。 |
SCHED_RR级的进程在耗尽事先分配给它时间后就不能再继续执行了,即它是带有时间片的SCHED_FIFO。当SCHED_RR任务耗尽它的时间片时,在同一优先级的其他实时进程被轮流调度。 时间片只用来重新调度同一优先级的进程。对于SCHED_FIFO进程,高优先级总是立即抢占低优先级,但低优先级进程绝不能抢占SCHED_RR任务,即使它时间片耗尽 ⚠️这两种实时算法实现的都是静态优先级。内核不为实时进程计算动态优先级。这能保证给定优先级别的实时进程总能抢占优先级比它低的进程。 |
软实时:内核调度进程,尽力使进程在它的限定时间到来前运行,但内核不保证总能满足这些进程的要求。 |
实时优先级范围为[0, 99(即MAX_RT_PRIO-1)],默认情况下,MAX_RT_PRIO为100。 ⚠️默认情况下,nice值[-20, +19]直接对应的是[100, 139]的实时优先级范围。 |















 995
995











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









