







递归实现:
//先序遍历
非递归实现:
基于栈的递归消除:
递归(recursion)就是子程序(或函数)直接调用自己或通过一系列调用语句间接调用自己。该执行过程要求每一次节点中断调用其他方法,必须记录下该中断节点的环境信息,作用是为了调用结束返回结果之后原程序能够从上次中断位置起继续执行,在计算机中,通过一个栈结构来实现该效果(栈:先进后出):
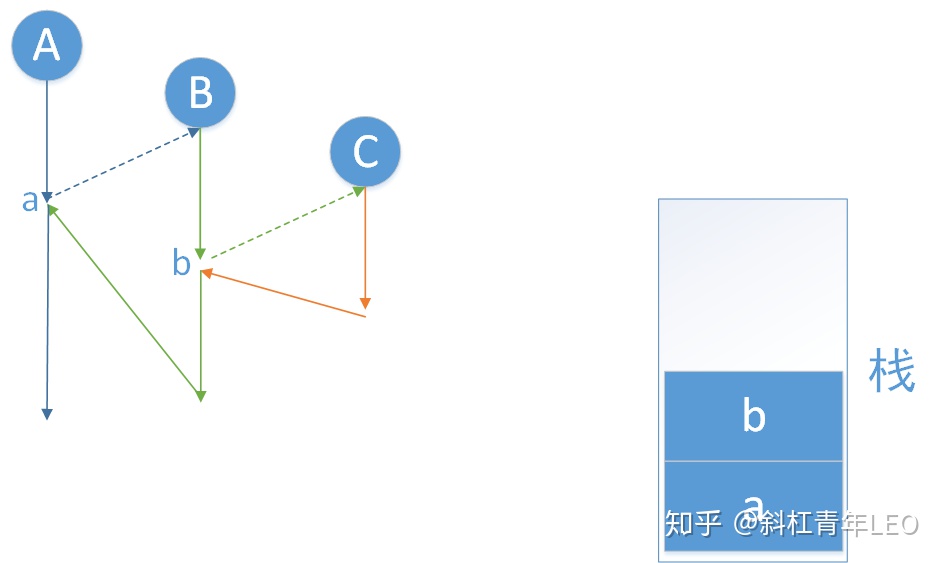
但递归算法的执行效率较低,这是因为递归需要反复入栈,时间和空间的开销都比较大。
(从本质上来看,递归其实是方便了程序员却难为了机器)
为了避免这种开销,需要消除递归,方法主要有两种:
1.针对简单递归,利用迭代代替递归;
2.利用栈的方式实现:利用人工栈模拟系统堆栈。(这种方法通用性强,但是本质上还是递归的,区别是将计算机做的事情改由人工来完成)
利用栈实现的非递归过程可分为 如下步骤:
- 设置一个工作栈,用于保存递归工作记录,包括实参、返回地址等;
- 将调用函数传递而来的参数和返回地址入栈;
- 利用循环模拟递归分解过程,逐层将递归过程的参数和返回地址入栈。当满足递归结束条件时,依次逐层退栈,并将结果返回给上一层,直至栈空为止。
非递归遍历二叉树:
先序遍历:根结点-左子树-右子树
算法思想:
从二叉树的根结点开始,将根结点设为当前结点p,执行以下操作:
- 边遍历边打印,并存入栈中(一开始当前结点p为根结点)→先打印当前结点p的数据→再将当前结点p入栈→若左孩子存在,将左孩子设为当前结点→重复执行此操作,直至到达二叉树左子树最左下角;
- 栈顶元素出栈,将栈顶元素设为当前结点p→若当前结点p的右孩子存在,将右孩子设为当前结点p(进入右子树)→回到步骤1,重复执行 1、2,直至栈空。
void 中序遍历:左子树-根子树-右子树
算法思想:
从二叉树的根结点开始,将根结点设为当前结点p,执行以下操作:
- 当前结点p入栈(一开始当前结点p为根结点)→若当前结点p存在左孩子→将左孩子设为当前结点p→重复此操作,直至到达二叉树左子树最左下角;
- 将栈顶元素出栈,将出栈元素设为当前结点p→打印该结点p的数据;
- 若当前结点p存在右孩子,则将右孩子设为当前 结点p→回到步骤1,重复执行 1、2、3,直至栈空。
void 后序遍历:左子树-右子树-根结点
算法思想:
声明两个结点指针(用于临时存储):当前结点-pCur;上一次访问的结点-pLast,将根结点设为当前结点pCur:
- 当前结点入栈(一开始当前结点为根结点)→若当前结点存在左孩子→将左孩子设为当前结点→重复此操作,直至到达二叉树左子树最左下角;
- 取栈顶元素,并设为当前结点pCur:
- 若当前结点pCur没有右孩子or右孩子刚刚访问过了(上一次访问的结点pLast就是右孩子)→栈顶元素出栈,打印当前结点pCur的数据→将当前结点pCur赋给pLast→将当前结点置空;
- 若当前结点pCur有右孩子→将右孩子设为当前结点(遍历右子树)→回到步骤1,重复执行 1、2,直至栈空。
void 














 1158
1158











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









