






原本打算把 Pandas 放在后面教程讲,但是这个库实在是太常用了,后面的教程都依赖于此,所以先带大家初学 Pandas库。
在学习 Pandas 之前,先阅读完前两篇教程:
多多教Python:Python 基本功: 3. 数据类型zhuanlan.zhihu.com

教程需求:
- Mac OS (Windows, Linux 会略有不同)
- 安装了 Python 3.0 版本以上, PyCharm, Microsoft Office Excel
- 阅读了多多教Python:Python 基本功: 2. 学会调用库, 多多教Python:Python 基本功: 3. 数据类型,多多教Python:Python 基本功: 4. 读写文件
介绍 Pandas
按照 Pandas 的官方介绍,这是一个建立在 Python 之上的一个高效的,简单易用的数据结构和分析工具。
Python Data Analysis Librarypandas.pydata.orgPandas 的核心就是一个高效易用的数据类型:DataFrame。这个数据类型有点类似 R 语言的数据框 (Data Frame),也有点类似于 Excel 表格,但是比这两种更加适合在 Python 的语言环境内操作数据。在这个数据结构之下,我们可以轻松的对数据进行清洗,整理,归纳总结,合并,转换,计算等等。现在我们先从 DataFrame 这个结构开始讲起。
DataFrame 数据框
Pandas 数据框类是一个表(Table)类的数据结构:首行是栏目 (Column),最左侧是行数 (Row Number),也可以叫索引 (Index),下面我们来看看如何建立一个数据框,首先打开 Anaconda Jupyter 笔记本:
In [1]:import pandas as pd
In [2]:df = pd.DataFrame(columns=['A', 'B', 'C'], index=['id 1', 'id 2', 'id 3'])
In [3]:df
Out[3]:
A B C
id 1 NaN NaN NaN
id 2 NaN NaN NaN
id 3 NaN NaN NaN
In [4]:df['A']
Out[4]:
id 1 NaN
id 2 NaN
id 3 NaN
Name: A, dtype: object
In [5]:df.iloc[1]
Out[5]:
A NaN
B NaN
C NaN
Name: id 2, dtype: object
In [6]:df.loc['id 1']
Out[6]:
A NaN
B NaN
C NaN
Name: id 1, dtype: object
In [7]:df.loc['id 1', 'A']
Out[7]:
nan
In [8]:df.loc['id 1', 'A'] = 5
In [9]:df
Out[9]:
A B C
id 1 5 NaN NaN
id 2 NaN NaN NaN
id 3 NaN NaN NaN
我们来一行行解读一下:
- 调用了 Pandas 库,并且取名叫 pd, 参考: 多多教Python:Python 基本功: 2. 学会调用库。
- 通过 Pandas 里面的 DataFrame 类,传入参数 columns 和 index, 创建了一个数据为空的三排三列数据框,赋予变量 df。
- 查看df,这里 df 的栏目 columns, 索引 index 都打印出来了,内容为 ''Nan" 类,表示空。
- 通过索引,在 多多教Python:Python 基本功: 10. 面对对象-类 Class 里介绍过,类可以提供索引功能,这里索引的是栏目中的一项,回复是整个一栏。
- 这里查看的是第二行 (DataFrame 的第一行从0开始),调用的是 iloc 子类,也提供了索引。这里 iloc 的参数是行数,和我们定义的 index ['id 1', 'id 2' ...] 无关,这也是为什么我特地写了这样的索引来区分行数。
- 这里根据我们定义的索引来查看某一行,用的是 loc 子类。loc 和 iloc 的区别是,loc 传入的索引参数是我们定义的索引,而 iloc 永远传入的是数字,也就是行数。如果索引和行数是一样的都是行数,那用哪一个都可以。
- 这里通过 loc,传入两个参数,一个是行数的索引,一个是栏目的名字,返回的是一个单元格,数据仍然是空。
- 这里我们给某一个指定的单元格写入一个数值。
- 再次打印 df 变量,发现这个数值已经被写入。
给 DataFrame 添加数据
这里查找数据挺方便的,但是一个数据一个数据写入就显得很麻烦,那如何把一组数据一起写入 DataFrame 呢?这里介绍两种方案:一种是从程序内部的另外一个数据类型直接拷贝进去,另外一种是从程序外部例如文件读取进去。
现在我们先来看第一种,从程序内部转换:
import 这里我们创建了一个字典,字典里的钥匙 Key 是股票的字符串,数值是另外一个字典,里面有价格 Price 和 股票数量 Shares 两个钥匙。这种结构的数据很适合转换成 DataFrame 的数据框形式,因为本质上读取一个数值也需要两层索引:一层是第一个字典的,二层是内部第二个字典的。转换的方法函数是 Pandas 的 from_dict()。但是这里有一个方向问题:因为创建 DataFrame 的时候我们的栏目是股票字符串,而行的索引是价格和股票数量,这和我们直觉上的查看方式:先查股票再看价格是相反的,那该如何纠正呢?
df 这里在从字典转换的时候标注方向: orient 可选参数就可以了。注意 Python 函数的可选参数是不一定要传入的,所以要了解函数的全部参数需要去读文档:
Pandas 官方文档pandas.pydata.org在 PyCharm IDE 中会也会给你函数的全部参数提示,之后我们会介绍如何去查询。Pandas 还提供另外两种转换函数: from_item() 和 from_records(),有需要的小伙伴我给了外部链接在教程结尾。
然后看第二种,从外部文件读取:
在多多教Python:Python 基本功: 4. 读写文件 这篇教程中,我们了解了如何通过 Python 原生的方法来读取一个包含日期,价格的金融文件。类似于这样的数据是非常符合 Pandas DataFrame 的数据格式的,并且Pandas 提供了非常方便的方法来读取这样的数据。首先我们创建一个数据源 .csv 格式文件:
Date,Open,High,Low,Close,Adj Close,Volume
9/3/19,136.61,137.2,135.7,136.04,136.04,18869300
9/4/19,137.3,137.69,136.48,137.63,137.63,17995900
9/5/19,139.11,140.38,138.76,140.05,140.05,26101800
9/6/19,140.03,140.18,138.2,139.1,139.1,20824500
9/9/19,139.59,139.75,136.46,137.52,137.52,25773900
9/10/19,136.8,136.89,134.51,136.08,136.08,28903400
9/11/19,135.91,136.27,135.09,136.12,136.12,24726100
9/12/19,137.85,138.42,136.87,137.52,137.52,27010000
9/13/19,137.78,138.06,136.57,137.32,137.32,23363100
9/16/19,135.83,136.7,135.66,136.33,136.33,16731400
9/17/19,136.96,137.52,136.43,137.39,137.39,17814200
9/18/19,137.36,138.67,136.53,138.52,138.52,23982100
9/19/19,140.3,142.37,140.07,141.07,141.07,35772100
9/20/19,141.01,141.65,138.25,139.44,139.44,39167300
9/23/19,139.23,139.63,138.44,139.14,139.14,17139300
9/24/19,140.36,140.69,136.88,137.38,137.38,29773200
9/25/19,137.5,139.96,136.03,139.36,139.36,21382000
9/26/19,139.44,140.18,138.44,139.54,139.54,17456600
9/27/19,140.15,140.36,136.65,137.73,137.73,22477700
9/30/19,138.05,139.22,137.78,139.03,139.03,17280900这个文件包含了微软股票,代号 "MSFT" 从 2019/9/3 到 2019/9/30 的日交易数据,在这里因为长度限制我只截取了一部分,但是足够用来示范了。
用 .csv 文件格式来保存是因为他比较适合保存表(Table)结构的源数据,而且比较 .xlsx Excel 格式更加轻量级,容易跨平台携带。现在我们来把这个文件直接读入 DataFrame 中:
In 这里用了一行非常简单的函数 read_csv() 就实现了我们在读写文件里用了5-6行实现的功能。参数包含了文件名,和一个可选参数 index_col,这个参数是告诉 Pandas 用文件中的某一个栏目来当作行数的索引。这里因为每一行数据代表了某一天的股票交易,所以用日期 Date 来索引会比较容易查询。注意虽然我们只用了一个日期做索引,但是这里的 index_col 输入的是一个列表,在后面的教程会讲到 DataFrame 支持 多重索引。
打印出 msft_df,因为显示的数据太多,Jupyter 笔记本会很人性化的加上省略号,最后再给出了一共有 2265 行数据,6个栏目,我们用日期 Date 当作了行索引所以就自动不算做栏目了。
DataFrame 做数据分析
尽管这篇教程并不是具体讲数据分析的,我们还是来调用一下 DataFrame 提供的界面 (Interface),来看看这个神奇的数据结构可以给我们带来怎么样便利的操作:
In - 第一个函数 head() 是查看 DataFrame 的前5行,如果你不传入参数,就是默认看5行。一般在做数据清洗 (Data Cleaning) 之前,先会看一下这个数据库的采样得到一个大致的了解。
- describe() 是用来描述 DataFrame 里面每一栏目,也就是每一列的描述性统计分析。通过调用这个函数,同样我们会对数据库的整体样本有一个统计了解。
- 这里用到了另外一个常用库: Matplotlib,是用来绘图和做数据可视化的,这里的 inline 意思是在之后的绘图过程中讲直接在 Jupyter 笔记本里呈现。具体意思在之后教程中会提到。
- 这里是绘图的输出,图片拷贝在了下面。
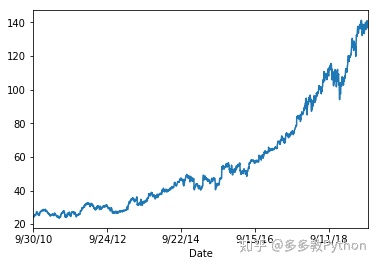
不看不知道,原来微软在过去10年表现那么厉害,翻了将近7倍?哈哈 。现在我们来做一些进阶的金融分析:
import 这里通过调用 pct_change(1) 函数,DataFrame 返还了微软股票每日 Close 价格的百分比变化,也就是股价的日回报率。然后通过调用 numpy 库的计算 mean(),std(), sqrt() 来计算股票分析中常用的夏普比率,波动率。
这里 pct_change(1) 中的1,代表了是一行隔一行的计算,也就是今天和昨天的 Close 价格的百分比变化,同样的我们可以用 shift() 函数:
r shift(1) 函数是指把 DataFrame 中的每一行往后移动一行。这样就相当于 今天的 Close 价格除以 昨天的 Close 价格,再减去1,同样的实现了百分比变化。
从 DataFrame 导出数据
当我们通过 DataFrame 完成了数据处理,分析之后,我们希望把数据保存下来,或者导出结果。在上文 多多教Python:Python 基本功: 5. 数据序列化 中,我们介绍了两种 Python 自带的方法。这里我想要介绍的是 Pandas 提供的方案:
- 保存到剪贴板 (Clipboard)
Pandas 可以让你把 DataFrame 里面的数据直接复制到电脑的黏贴版里。这个方法出奇的效率,只需要调用一个函数,你就可以把所有数据复制黏贴到想要保存的文件里:
msft_df在调用了这个函数之后,打开 Excel 或者某个IDE,直接黏贴就可以了。虽然 Pandas 功能很丰富,但是 Excel 丰富的绘制工具也可以利用起来。这里我通过 Excel 的股票绘制工具来很轻松的画出了 K 线:
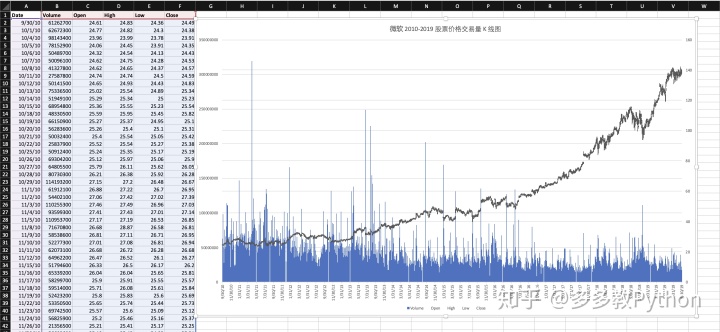
同样的,你可以把计算出来的数据保存到剪贴板:
r黏贴到 Excel 里之后,绘制散点图:

- 保存到 .csv,和其他格式
这个方法就是把 DataFrame 里的数据保存到指定的文件格式中,这里介绍的是 .csv 格式:
r然后在同一个文件夹目录下就会看到写好的文件,这个方法也非常方便,而且你可以反复的通过 Pandas 提供的界面 read_csv() 和 to_csv() 来保存,读取数据。
小结:
这篇文章仅仅是初次介绍 Pandas, 小伙伴们就会发现里面功能多样,玩法很多。相比直接用 Python 自带的数据类,用 Pandas几行代码就可以实现原本需要几十行代码完成的任务。并且通过 Pandas 的 DataFrame,读写数据,清洗处理,计算分析和可视化全部在一个数据结构类里完成。之后的教程会在更加专业的 金融,医疗 等领域介绍如何使用 Pandas 来做科学计算。下面提供几个外部的链接:
- 列表或字典转化成 DataFrame:

- 如何用 Excel 来绘制 K 线图:
















 542
542

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









