








对于web来说,是用户量和访问量支持项目技术的更迭和前进。随着服务用户提升。可能会出现一下的一些状况:
我们从一个算法问题开始了解缓存的意义。
问题1:
- 输入一个数n(n<20),求 n! ;
分析1:
- 单单考虑算法,不考虑数值越界问题。 当然我们知道 n!=n * (n-1) * (n-2) * ... * 1= n * (n-1)! ; 那么我们可以用一个递归函数解决问题。
static long jiecheng(int n){if(n==1||n==0)return 1;else { return n*jiecheng(n-1);}}复制代码这样每输入求一次需要执行 n 次。 问题2:
- 输入t组数据(可能成百上千),每组一个x(n<20),求 x! ;
分析2:
- 如果使用 递归 ,输入t组数据,每个位x,那么每次都要执行 X~i~
- 当X~i~过大或者n过大都会造成不小的负担! 时间复杂度 为 O(n^2^)
- 那么能否换个思想的。没错、是 打表 (也可以理解位 动态规划 )。打表常用于ACM算法中,常用于解决多组输入输出、图论搜索结果、路径储存问题。那么,对于这个求阶乘。我们只需要申请一个数组。每个数据为 前一个数据 * 当前index 。那么思想很明确啦!
import java.util.Scanner;public class test3 {public static void main(String[] args) {// TODO Auto-generated method stubScanner sc=new Scanner(System.in);int t=sc.nextInt();long jiecheng[]=new long[21];jiecheng[0]=1;for(int i=1;i<21;i++){jiecheng[i]=jiecheng[i-1]*i;} for(int i=0;i时间复杂度才 O(n) 。这里的思想就和 缓存 思想差不多。先将数据在jiecheng[21]数组中储存。执行一次计算。当后面继续访问的时候就相当于当问静态数组值。为O(1)。就能大大的减少查询、执行成本啦!
缓存的应用场景
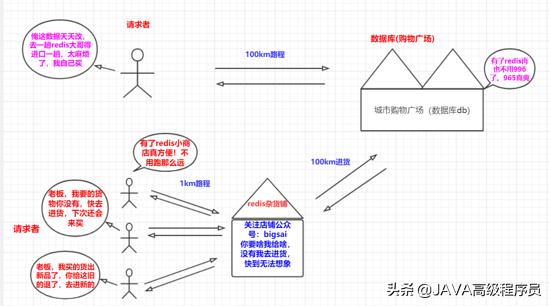
缓存适用于高并发的场景,提升服务容量。主要是将从 经常被访问的数据 或者查询 成本较高从慢的介质中存到比较快的介质中,比如从 硬盘 —> 内存 。我们知道大多数关系数据库是 基于硬
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 281
281











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









