






鲁春利的工作笔记,好记性不如烂笔头
如下配置参照了http://hbase.apache.org/book.html,详见:hbase-1.0.1.1/docs/book.html

环境配置
1、安装JDK1.6或更高版本
略
2、下载HBase
解压 % tar -xzv -f hbase-x.y.z.tar.gz
3、配置HBase环境变量# hadoop体系的软件均通过hadoop用户来运行
vim /home/hadoop/.bash_profile
# 新增HBase环境变量
# HBase
export HBASE_HOME=/lucl/hbase-1.0.1.1
export PATH=$HBASE_HOME/bin:$PATH
4、配置文件hbase-env.sh[hadoop@nnode conf]$ pwd
/lucl/hbase-1.0.1.1/conf
[hadoop@nnode conf]$ vim hbase-env.sh
export JAVA_HOME=/lucl/jdk1.7.0_80
export HBASE_HOME=/lucl/hbase-1.0.1.1
# 由于hbase使用到了HDFS的HA地址,需要配置为Hadoop的conf目录(hadoop2.0为etc/hadoop)
export HBASE_CLASSPATH=/lucl/hadoop-2.6.0/etc/hadoop
# HBase的日志
export HBASE_LOG_DIR=/lucl/storage/hbase/logs
# 禁用hbase自带的zookeeper
export HBASE_MANAGES_ZK=false
5、修改配置文件hbase-site.xml
hbase.cluster.distributed
true
true for fully-distributed
hbase.tmp.dir
/lucl/storage/hbase/tmp
本地文件系统的临时文件夹,hbase运行时使用
hbase.local.dir
/lucl/storage/hbase/local
本地文件系统的本地存储
hbase.rootdir
hdfs://cluster/hbase
在hdfs上存储的根目录(fs.defaultFS+目录名称),在单机模式下存储
在本地目录(file:///Directory)。
hbase.zookeeper.quorum
nnode,dnode1,dnode2
zk服务器列表
hbase.zookeeper.property.dataDir
/lucl/storage/zk/data
Property from ZooKeeper config zoo.cfg.
zookeeper.session.timeout
120000
2 minute, the minute from RegionServer to Zookepper
hbase.zookeeper.property.tickTime
2000
Property from Zookeeper config zoo.cfg
hbase.zookeeper.property.clientPort
2181
Property from Zookeeper config zoo.cfg
hbase.master.info.bindAddress
nnode
HBase Master Web UI的绑定地址,默认0.0.0.0
hbase.master.info.port
16010
HBase Master Web UI端口,-1表示不运行Web UI
hbase.regionserver.port
16020
The port the HBase RegionServer binds to.
hbase.regionserver.info.port
16030
The port for the HBase RegionServer web UI
hbase.regionserver.info.bindAddress
nnode
The address for the HBase RegionServer web UI
说明:
hbase.regionserver.info.bindAddress必须注意修改,否则RegionServer将无法启动成功。
如果在hbase-site.xml文件中未指定hbase.master的配置,则从那台机器启动hbase那台机器自动成为HMaster,而HRegionServer则依赖于conf/regionservers文件。
6、修改配置regionservers文件[hadoop@nnode conf]$ pwd
/usr/local/hbase1.0.1/conf
# 定义RegionServer
[hadoop@nnode conf]$ cat regionservers
dnode1
dnode2
[hadoop@nnode conf]$
7、分发hbase程序
将该hbase目录拷贝到另外两台主机dnode1和dnode2上# 分发程序
[hadoop@nnode hbase]$ scp -r hbase dnode1:/lucl/storage/
[hadoop@nnode hbase]$ scp -r hbase dnode2:/lucl/storage/
# 分发目录
[hadoop@nnode hbase]$ ll
总用量 12
drwxrwxr-x 2 hadoop hadoop 4096 1月 18 15:49 local
drwxrwxr-x 2 hadoop hadoop 4096 1月 18 15:47 logs
drwxrwxr-x 2 hadoop hadoop 4096 1月 18 15:49 tmp
[hadoop@nnode hbase]$
[hadoop@nnode storage]$ scp -r hbase dnode1:/lucl/storage/
[hadoop@nnode storage]$ scp -r hbase dnode2:/lucl/storage/
8、配置dnode1和dnode2的HBase环境变量# HBase
export HBASE_HOME=/lucl/hbase-1.0.1.1
export PATH=$HBASE_HOME/bin:$PATH
启动集群
1、在nnode节点启动HBase[hadoop@nnode hbase-1.0.1.1]$ start-hbase.sh
master running as process 8404. Stop it first.
dnode2: starting regionserver, logging to /lucl/storage/hbase/logs/hbase-hadoop-regionserver-dnode2.out
dnode1: starting regionserver, logging to /lucl/storage/hbase/logs/hbase-hadoop-regionserver-dnode1.out
说明:HBase依赖于ZK、Hadoop,启动过程如下:# 启动zookeeper
# 启动hadoop
# 启动HBase
bin/start-hbase.sh
2、验证安装-- HMaster
[hadoop@nnode ~]$ jps
12969 ResourceManager
12800 DFSZKFailoverController
13413 HMaster
12328 JournalNode
12281 QuorumPeerMain
12514 NameNode
13513 Jps
[hadoop@nnode ~]$
-- RegionServer
[hadoop@dnode1 ~]$ jps
12477 DFSZKFailoverController
12179 QuorumPeerMain
12309 NameNode
12233 JournalNode
12637 Jps
12377 DataNode
3、访问master节点的Web界面
http://nnode:16010
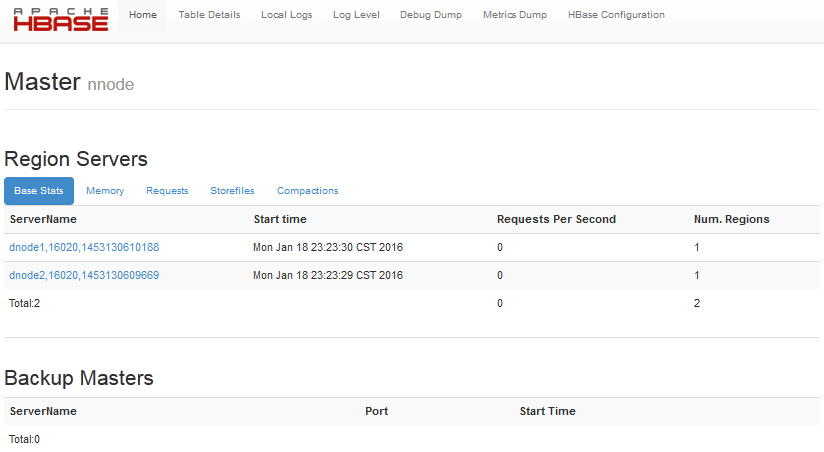
说明:这里Backup Mastrs后面介绍。
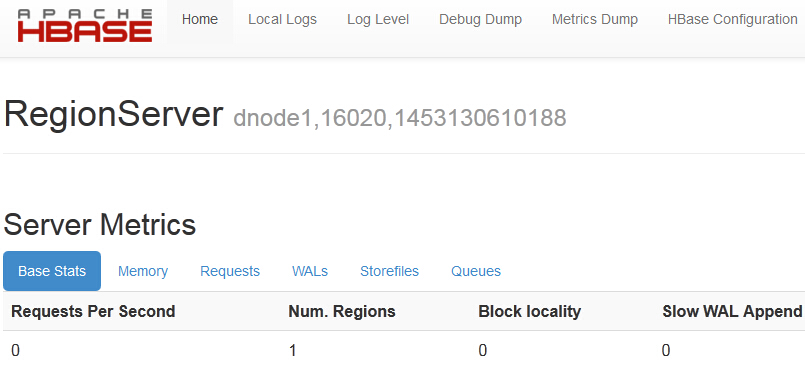
4、访问regionserver节点的Web界面
http://dnode1:16030或http://dnode2:16030
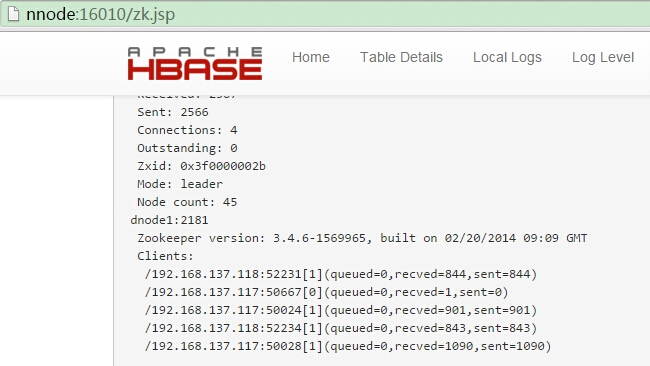
5、查看master节点web目录下zk的状态
6、命令行工具HBase shell使用bin/hbase shell
连接成功后进入HBase的执行环境HBase Shell; enter 'help' for list of supported commands.
Type "exit" to leave the HBase Shell
Version 1.0.1, r66a93c09df3b12ff7b86c39bc8475c60e15af82d, Fri Apr 17 22:14:06 PDT 2015
hbase(main):001:0>
输入help可以看到命令的详细帮助信息,需要注意的是,在使用命令引用到表名、行和列时需要加单引号。
创建一个名为test的表,只有一个column family(列族)为cf。# 创建表
hbase(main):004:0> create 'test', 'cf'
0 row(s) in 0.7540 seconds
=> Hbase::Table - test
# 查看表
hbase(main):005:0> list 'test'
TABLE
test
1 row(s) in 0.0150 seconds
=> ["test"]
# 插入数据
hbase(main):006:0> put 'test', 'row1', 'cf:id', '1000'
0 row(s) in 0.3310 seconds
hbase(main):007:0> put 'test', 'row1', 'cf:name', 'lucl'
0 row(s) in 0.0250 seconds
hbase(main):008:0> put 'test', 'row2', 'cf:c', 'val001'
0 row(s) in 0.0220 seconds
# 以上命令分别插入了三行数据,第一行rowkey为row1,列为cf:id,值为1000。HBase中的列是又
# column family前缀和列的名字组成的,以冒号分割。
# 扫描表的数据
hbase(main):009:0> scan 'test'
ROW COLUMN+CELL
row1 column=cf:id, timestamp=1440335878007, value=1000
row1 column=cf:name, timestamp=1440335886167, value=lucl
row2 column=cf:c, timestamp=1440335892630, value=val001
2 row(s) in 0.1560 seconds
# 获取单行数据
hbase(main):010:0> get 'test', 'row1'
COLUMN CELL
cf:id timestamp=1440335878007, value=1000
cf:name timestamp=1440335886167, value=lucl
2 row(s) in 0.0610 seconds
# 停用表
hbase(main):011:0> disable 'test'
0 row(s) in 2.2920 seconds
# 删除表
hbase(main):012:0> drop 'test'
0 row(s) in 0.7670 seconds
# 查看表
hbase(main):013:0> list 'test'
TABLE
0 row(s) in 0.0090 seconds
=> []
# 退出
hbase(main):014:0> quit
7、通过ZK查看hbase的数据WATCHER::
WatchedEvent state:SyncConnected type:None path:null
[zk: localhost:2181(CONNECTED) 0] ls /
[hbase, hadoop-ha, zookeeper]
[zk: localhost:2181(CONNECTED) 1] ls /hbase
[meta-region-server, backup-masters, table, draining, region-in-transition, running, table-lock, master, namespace, hbaseid, online-snapshot, replication, splitWAL, recovering-regions, rs, flush-table-proc]
[zk: localhost:2181(CONNECTED) 2]
说明:HBase天生就具备了HA机制。ZK中记录了HBase的状态信息,如果出现org.apache.hadoop.hbase.TableExistsException: hbase:namespace的问题,可以删除该/hbase目录,再启动时会重新生成。
8、在hdfs上也记录了hbase的数据
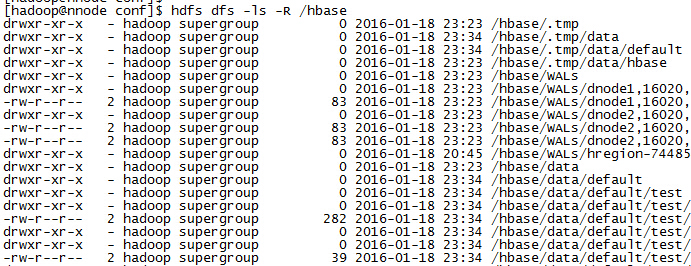
说明:HBase的数据是以HDFS作为存储的。
9、停止HBase./bin/stop-hbase.sh
10、HBase的HA
Hbase默认只有一个Master,我们可以也启动多个Master:# hbase-daemon.sh start master
#
# 不过,其它的Master并不会工作,只有当主Master down掉后其它的Master才会选择接管Master的工作。















 6024
6024











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









