






SPSS作为老牌强大数据分析软件,对于笔者这样的小白而言,非常易用,10秒完成一个one-way anova不成问题,唯手熟尔。当因为某些原因不得不用R语言做anova分析时,却碰到诸多问题,通过层层搜索和整理,最终还是完成了与SPSS输出完全一致的R代码,仅供参考。本文主要关注三种最简单的方差分析:one-way anova(单因素方差分析),two-way anova(二因素方差分析)和repeated anova(重复测量方差分析),分别使用SPSS和R语言进行分析对比。
1 one-way anova(单因素方差分析)
数据集:不同种类的饲料对小鼠似乎有不同的增肥效果,如果仅考虑体重,哪一种最好?自变量为饲料种类,因变量为小鼠体重。

SPSS分析过程:
选择[Analyze]-[Compare Means]-[One-Way ANOVA]
将fodder变量放入Factor,weight变量放入Dependent List
在[Post Hoc]选项中勾选Tukey进行事后检验
在[Options]中勾选Descriptive,Homogeneity of variance test,和Means plot

点击[OK]输出结果:

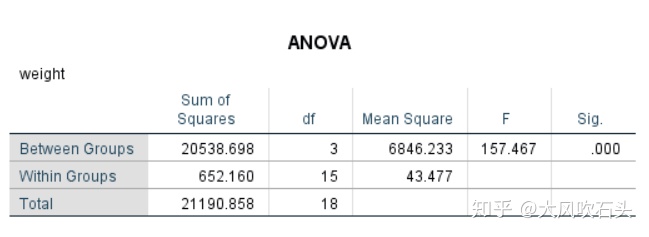
在one-way anova的输出结果中,F(3, 15) = 157.467,p < .001,表明吃不同饲料的老鼠的体重的确有差异,那么到底吃哪一种饲料增肥效果最好呢?接下来看事后检验的结果:
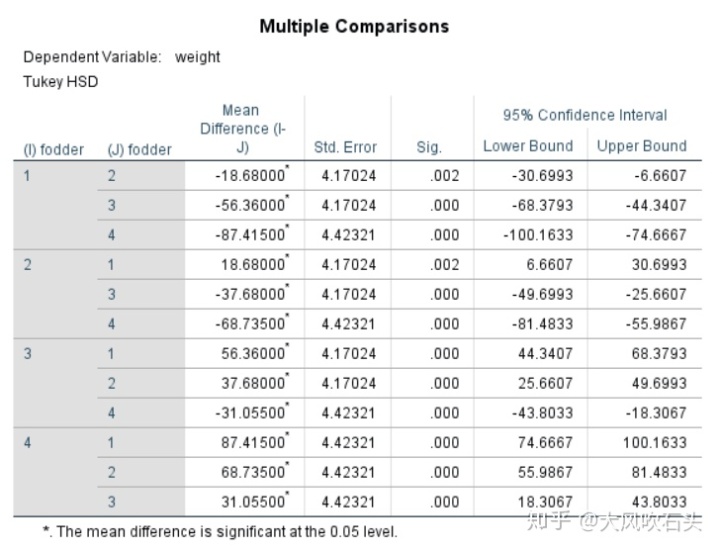
可以看到第4种饲料增肥效果最好,为了可视化性更好,看下SPSS出的祖传图:
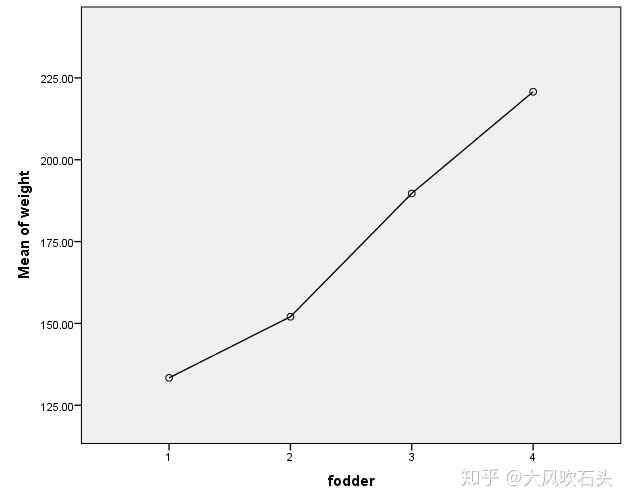
R语言分析过程:
# 安装和引用库
library(readxl)
library(car)
library(ggpubr)
# 读取数据与数据整理
data <- read_excel("one_way_anova_data.xlsx", sheet = 1)
one_way_dataframe <- as.data.frame(data)方差同质性检验:
# 方差同质性检验
fodder <- as.factor(one_way_dataframe$fodder)
weight <- one_way_dataframe$weight
leveneTest(weight, fodder, center = "mean")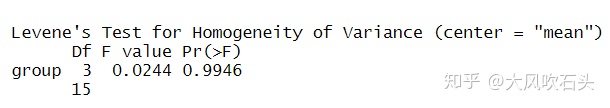
方差分析:
# 主效应检验
fit_model <- aov(weight ~ fodder)
anova(fit_model)
事后检验(TukeyHSD):
TukeyHSD(fit_model)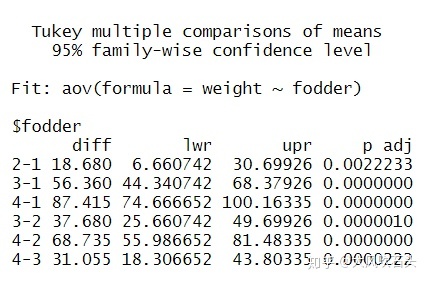
请欣赏R语言出的图:
# 箱图可视化
ggboxplot(one_way_dataframe, x = "fodder", y = "weight", add = "point")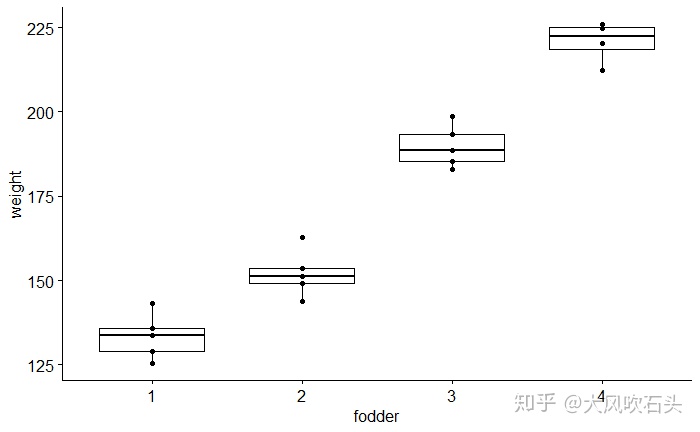
2 two-way anova(二因素方差分析)
数据集:不同的药物和食物搭配对激素水平有着怎样的影响(数据系编造,无任何意义)?自变量为药物种类和食物种类,因变量为激素水平。
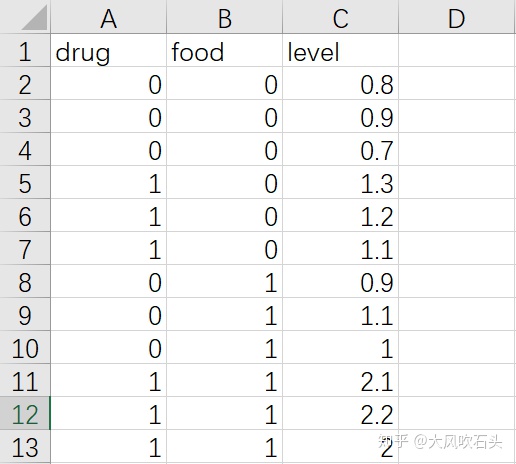
SPSS分析过程:
选择[Analyze]-[General Linear Model]-[Univariate]

将drug和food变量放入Fixed Factor,weight变量放入Dependent Variable
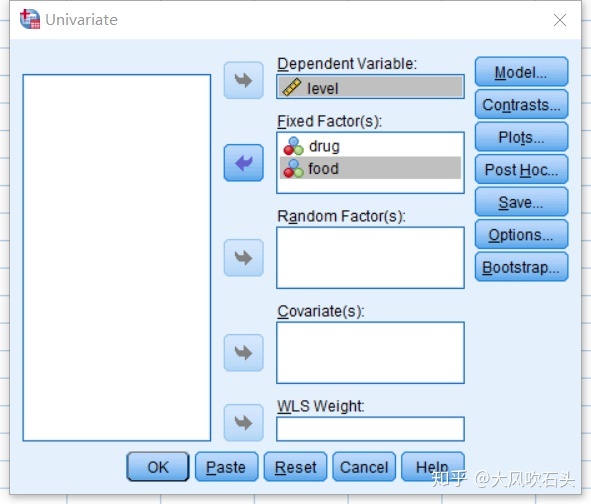
在[Plots]选项中将drug放入Horizontal Axis,将food放入Separate Lines,并点击[Add]加入绘图序列
由于drug和food均只有两个水平,不用选择事后检验。
在[Options]中勾选Descriptive statistics,Estimates of effect size,Observed power,和Homogeneity test
点击[OK]输出结果。
同质性检验结果:

二因素方差分析检验结果:
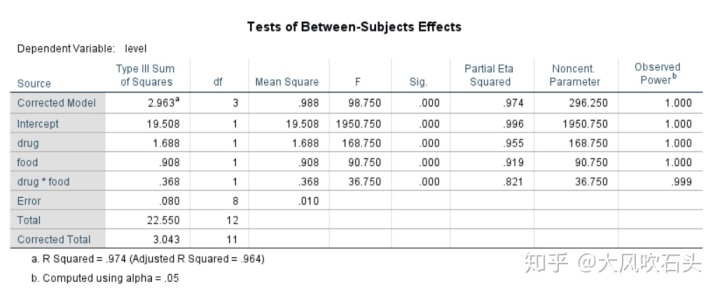
结果显示不同种类的药物和不同种类的食物对激素水平均有显著影响,且二者的交互作用显著,表明不同药物和食物的搭配会影响激素水平。看下SPSS出的图:
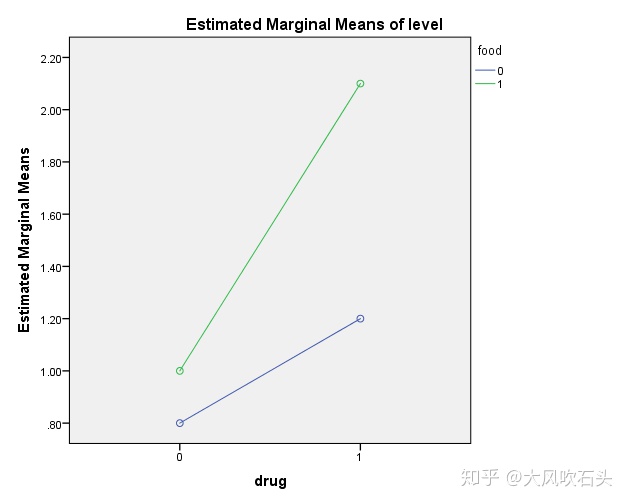
R语言分析过程:
# 安装和引用库
library(readxl)
library(car)
library(ggpubr)
library(rstatix)
# 读取数据与数据整理
data <- read_excel("two_way_anova_data.xlsx", sheet = 1)
two_way_dataframe <- as.data.frame(data)
two_way_dataframe <- two_way_dataframe %>%
convert_as_factor(drug, food)方差同质性检验:
drug <- two_way_dataframe$drug
food <- two_way_dataframe$food
level <- two_way_dataframe$level
leveneTest(level ~ drug*food, center="mean") 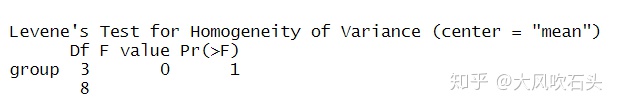
二因素方差分析结果:
# 主效应检验
fit_model <- aov(level ~ drug*food)
anova(fit_model)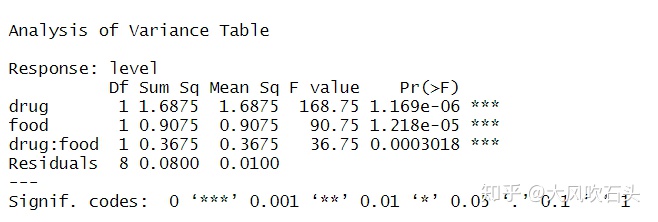
事后检验:
# 事后检验
TukeyHSD(fit_model, which = "drug") # 针对drug自变量的事后检验
TukeyHSD(fit_model, which = "food") # 针对food自变量的事后检验
R语言可视化结果:
# 绘制箱图
ggboxplot(two_way_dataframe, x = "drug", y = "level", color = "food", palette = "jama", add = "point")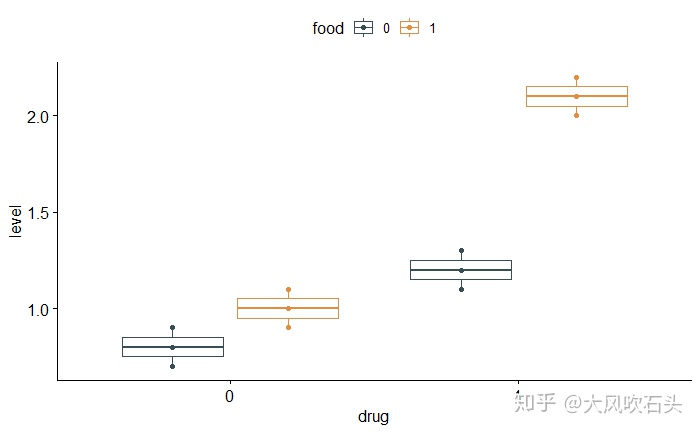
3 repeated anova(重复测量方差分析)
数据集:一群人不同时间段的情感水平是否有差异?自变量测量时间,因变量为情感水平。
SPSS分析过程:
选择[Analyze]-[General Linear Model]-[Repeated Measures]
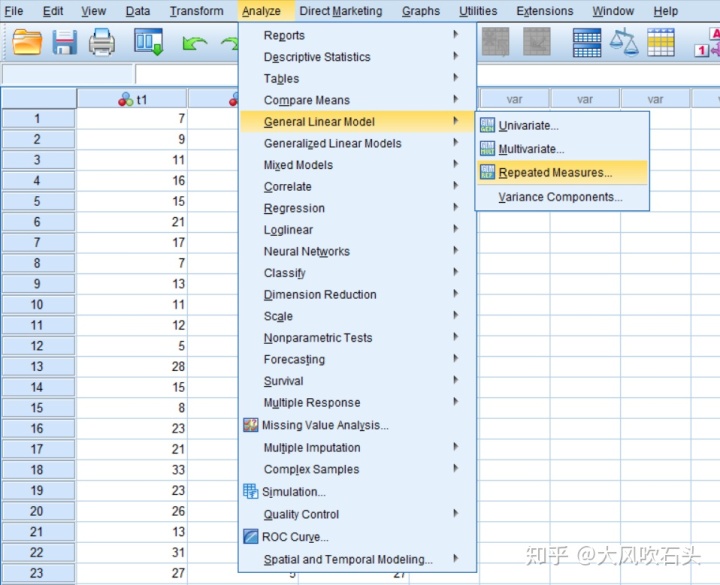
设定重复度量因子time,因子个数为3个
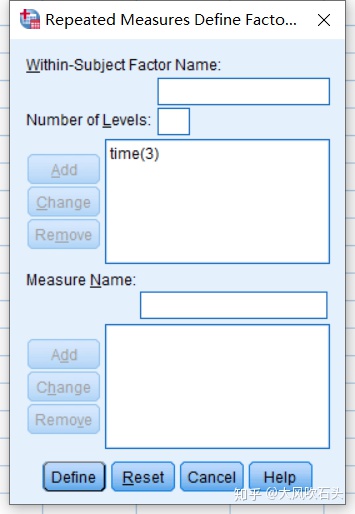
将3次测量的数据放入重复测量的3个水平上
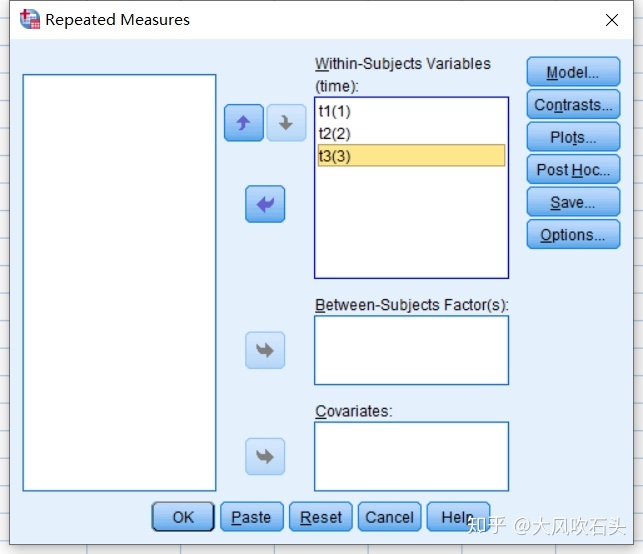
在[Plots]选项中将time放入Horizontal Axis,并点击[Add]加入绘图序列
在Estimated Marginal Means将time导入右侧,勾选Compare main effects,选择Bonferroni校正,在下方Display栏中勾选Descriptive statistics,Estimates of effect size,Observed power,和Homogeneity test
点击[OK]输出结果。
球形度检验结果:

球形度检验不显著,表明数据符合球形度假设。
重复测量方差分析结果:
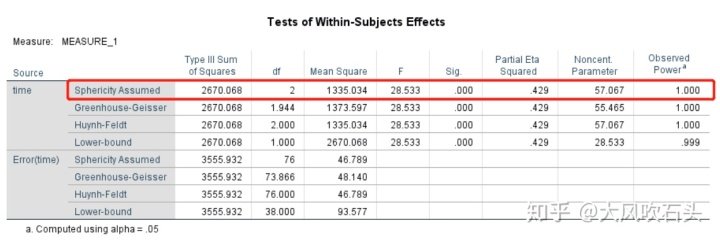
球形度假设符合时,应读取第一行结果,可以看出time的主效应显著,表明不同时间测量的情感水平存在差异。
成对比较结果:
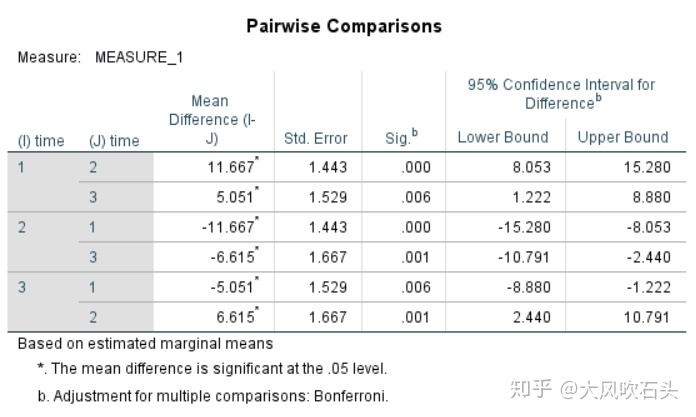
从成对比较的结果中可以看出,时间1的情感水平最高,时间2的情感水平最低。再看下SPSS出的图:
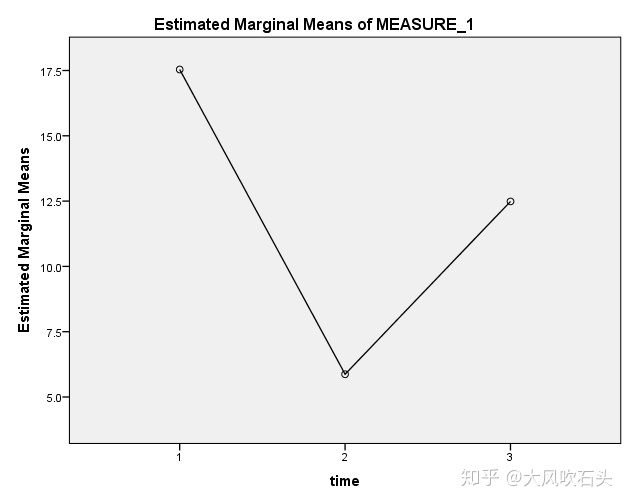
R语言分析过程:
# 安装和引用库
library(ggpubr)
library(rstatix)
library(readxl)
library(car)
# 读取数据与数据整理
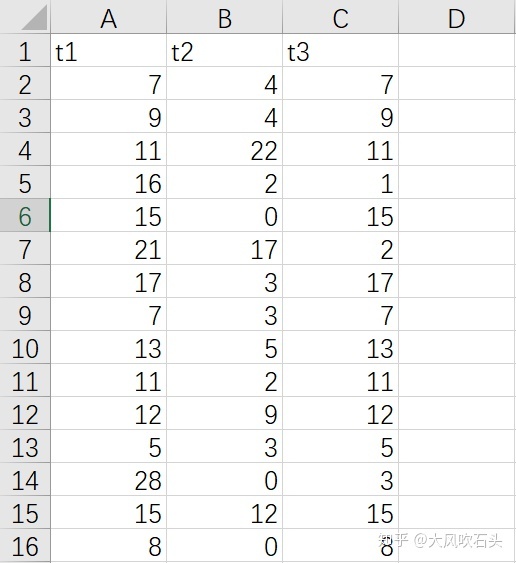
data <- read_excel("repeated_anova_data.xlsx", sheet = 1)
subjectID <- rep(c(1:39), times = 3) # 被试编号
time <- c(rep(1,39),rep(2,39),rep(3,39)) # 重复测量
score <- c(data$t1, data$t2, data$t3)
repeated_dataframe <- data.frame(subjectID, time, score)球形度检验与重复测量方差分析:
repeated_fit <- anova_test(data = repeated_dataframe, dv = score, wid = subjectID, within = time)
repeated_fit
两两比较,对应SPSS的估计边界均值:
# 使用rstatix库中的pairwise_t_test函数,读取p.adj结果
pwc <- pairwise_t_test(data = repeated_dataframe, score ~ time, paired = T, p.adjust.method = "bonferroni")
pwc
R绘图:
# 箱图
ggboxplot(repeated_dataframe, x = "time", y = "score", add = "point")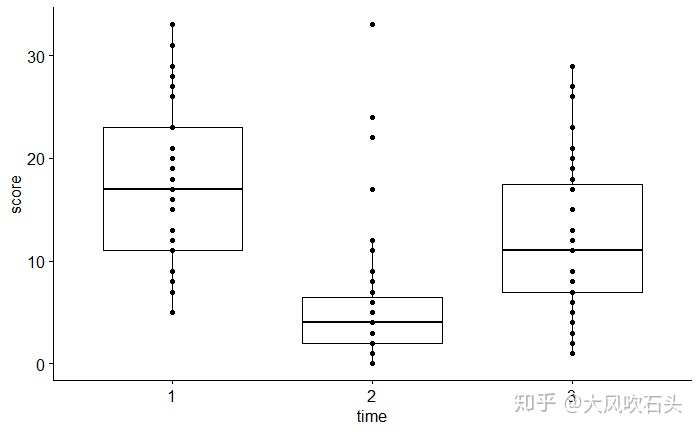
这是SPSS和R语言进行三种anova分析的过程,只看数据分析过程的话,SPSS仍然是真爱~















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









