




Dremio是一款专注于数据湖分析的创新引擎,通过其独特的数据虚拟化技术和列式存储加速机制,彻底改变了传统大数据查询的方式。作为Apache Arrow的创始人团队打造的产品,Dremio已从一个开源项目发展成为估值140亿人民币的全球独角兽企业,为超过86%寻求数据统一的企业提供了革命性的解决方案。Dremio的核心价值在于它能够直接在原始数据湖上执行SQL查询,无需进行ETL数据迁移,同时通过Data Reflections预聚合技术将复杂查询的响应时间从分钟级压缩至亚秒级,在金融、制造业和互联网等多个领域展现出卓越的性能和灵活性。
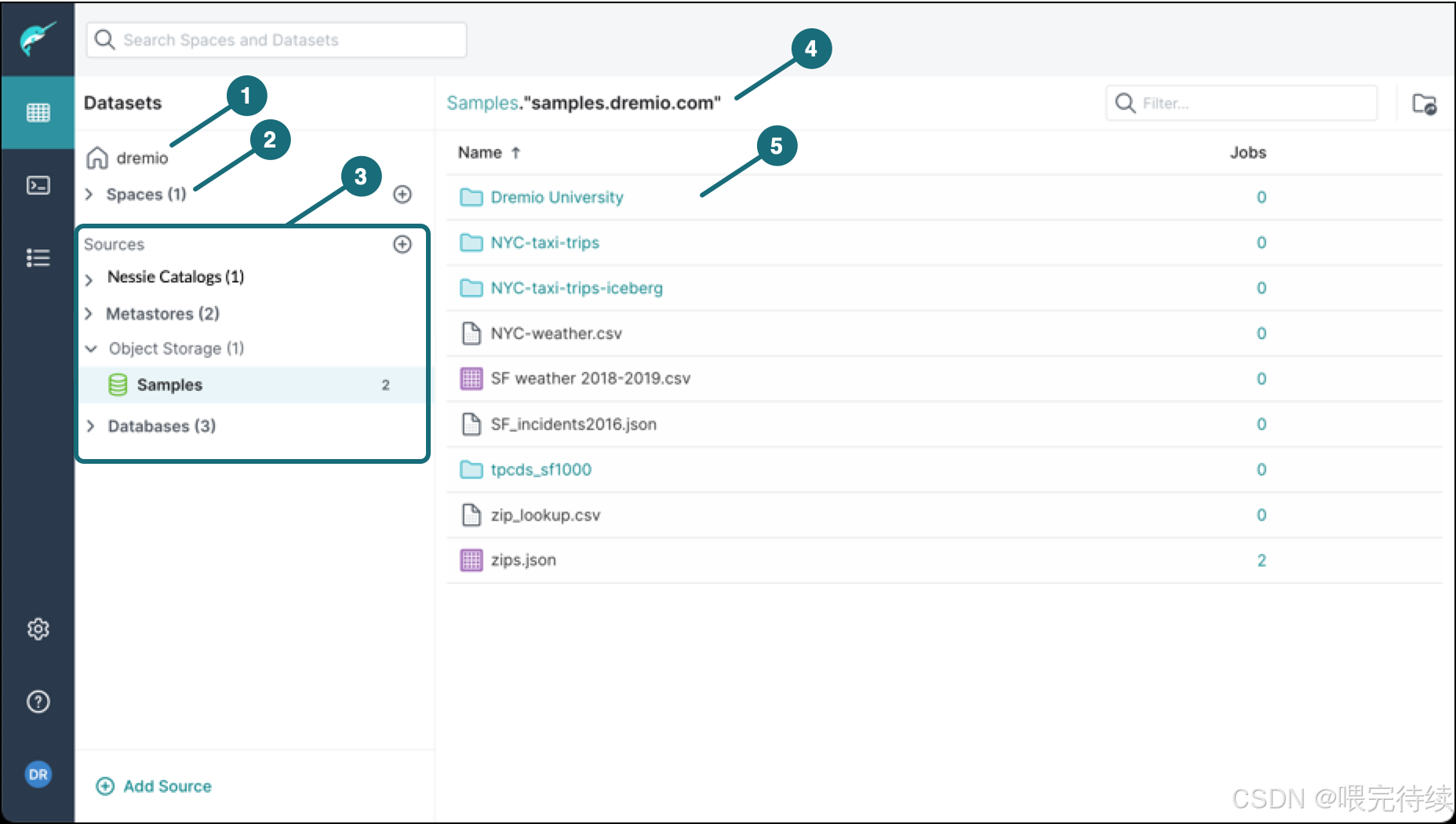
1. Dremio是什么?
Dremio是一个开源数据湖查询引擎,专为加速云数据湖(如AWS S3、Azure Blob Storage)上的SQL查询而设计。它通过数据虚拟化技术创建逻辑数据层,使用户能够直接查询原始数据湖中的数据,而无需将数据移动到专门的分析系统或数据仓库中。Dremio本质上是一个数据即服务平台(DaaS),允许业务分析师和数据科学家随时探索和分析任何数据,无论其位置、大小或结构如何 。它不仅实现了任何数据量的交互式性能,还使IT人员、数据科学家和业务分析师能够根据业务需求无缝调整数据,从而显著提高数据价值的实现效率。
Dremio的核心架构由两个主要部分组成:Dremio Sonar(查询引擎)和Dremio Arctic(元数据服务)。Sonar负责数据湖的实时查询和加速,而Arctic则专注于管理Iceberg格式的元数据,提供类似AWS Glue的目录服务。这种分离设计使Dremio能够灵活适应不同规模和复杂度的数据分析需求。
2. Dremio的诞生背景
Dremio的创立源于数据湖分析领域的一个根本性挑战:如何在不移动数据的情况下,实现对云数据湖的高性能SQL查询。随着大数据技术的发展,数据湖因其低成本、高扩展性和灵活性而受到广泛欢迎,但直接在数据湖上进行高效查询一直是一个难题。传统方法通常需要将数据从数据湖移动到专门的数据仓库或ETL系统中进行处理,这不仅增加了数据移动的开销,还导致了延迟和资源浪费。
Dremio由Apache Arrow创始人Jacques Nadeau与Tomer Shiran于2015年在美国硅谷创立,其核心理念是通过创新技术解决这一挑战。2021年,Dremio完成了1.35亿美元的E轮融资,估值达到20亿美元。截至2024年4月,企业估值已增长至140亿人民币,累计融资总额超过4.05亿美元。这些资金主要用于云原生架构研发与全球市场拓展,使Dremio能够持续创新并扩大其市场影响力。
Dremio的诞生也顺应了数据湖仓一体化(Lakehouse)的行业趋势。随着企业数据量的快速增长和分析需求的多样化,传统的数据仓库和数据湖架构各有利弊:数据仓库提供了结构化管理和高性能查询,但扩展性和成本较高;数据湖则提供了灵活性和低成本,但查询性能和管理能力较弱。Dremio通过结合两者的优势,成为Lakehouse架构中不可或缺的查询引擎,帮助企业实现数据湖的高效分析。
3. Dremio的技术架构
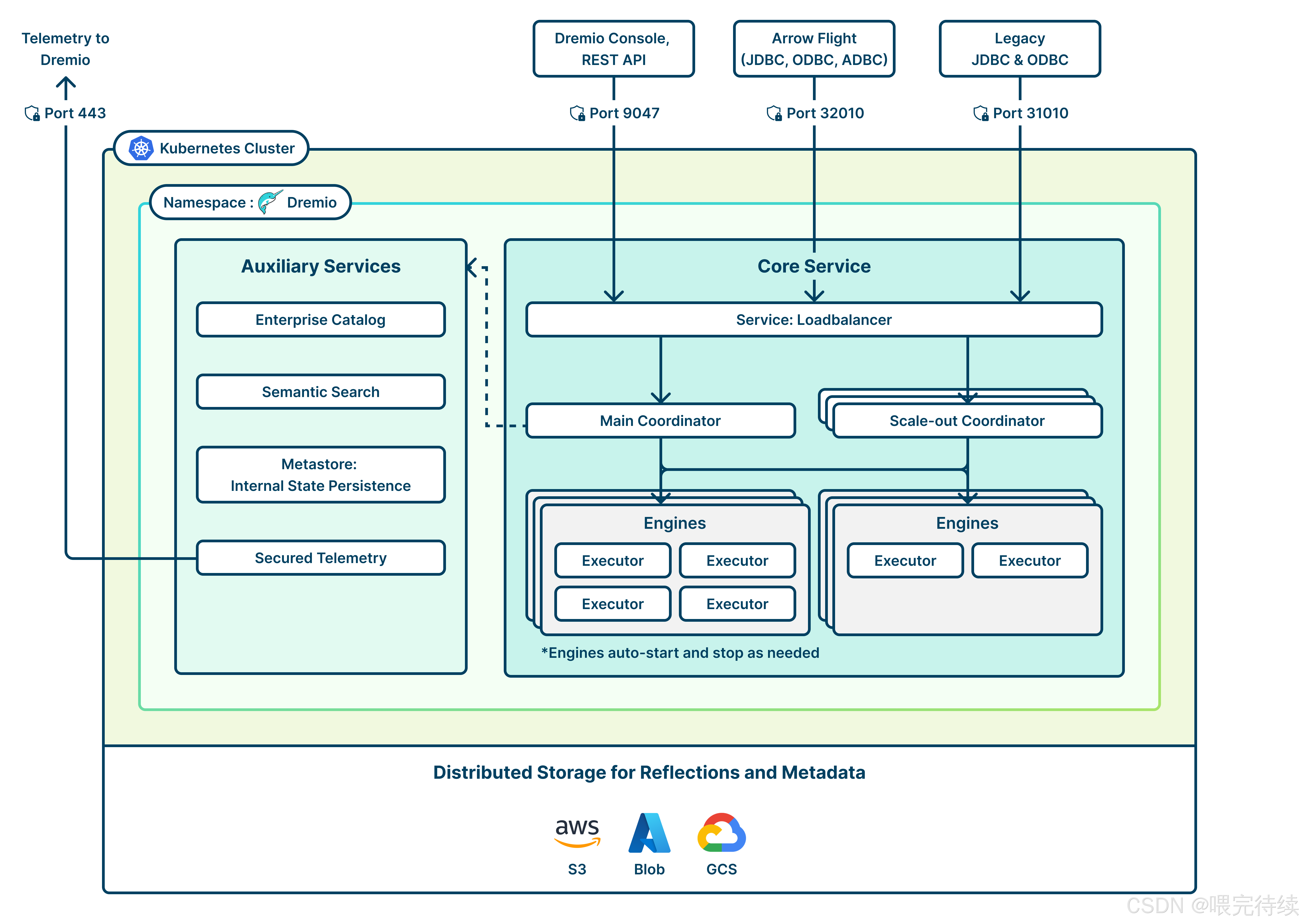
Dremio采用了一种创新的云原生架构设计,将系统分为Control Plane(控制平面)和Execution Plane(执行平面)两个独立的组件,这种分离设计既保障了数据安全,又实现了查询性能的优化。
Control Plane负责处理元数据管理、查询规划、任务调度和认证鉴权等核心功能。它部署在Dremio VPC中,为用户提供统一的查询端口、UI/REST API接口和SQL代理服务。Control Plane还包括Planner组件,用于生成查询的逻辑执行计划,并将其分发到Execution Plane的计算节点上执行。
Execution Plane则部署在客户VPC中,负责实际的数据处理和计算。它通过Kubernetes动态管理Compute Engine节点,根据查询需求自动扩缩容资源。这些计算节点直接访问客户的数据湖(如S3、HDFS、Kafka等),执行数据扫描、查询计算和结果返回等任务。
在查询处理流程方面,Dremio采用了一种高效的分布式架构,包括以下核心组件:
| 组件 | 功能 | 技术特点 |
|---|---|---|
| Coordinator节点 | 处理查询请求、协调任务分配、维护元数据 | 支持Multi Coordinator依赖Zookeeper的高可用架构 |
| Engine节点 | 执行实际的数据处理任务 | 利用Apache Arrow的列式内存计算和向量化执行技术 |
| 客户端 | 提供用户与Dremio交互的接口 | 支持JDBC/ODBC、REST API等多种连接方式 26 |
Dremio的查询优化器能够智能地将查询下推到数据源(如Presto、Spark等),减少数据移动,并利用Data Reflections技术对常用查询进行预聚合和加速,最高可提升100倍以上的查询性能。
此外,Dremio还支持Columnar Cloud Cache,将远端存储上的Parquet文件缓存在Engine节点的本地磁盘(如NVMe/SSD)上,进一步降低查询的资源开销。用户可以根据需要自定义缓存策略和配额,优化查询性能和成本。
4. Dremio解决的问题
Dremio主要解决企业在数据湖分析中面临的以下核心问题:
数据孤岛问题:企业数据通常分散在多个不同的系统和存储中,如关系型数据库、NoSQL数据库、云存储和Hadoop等。Dremio通过其数据虚拟化技术创建一个逻辑抽象层,将这些异构数据源统一到一个单一的逻辑视图中,使用户能够使用标准SQL查询跨多个源的数据,无需了解底层数据源或执行任何ETL过程 。
查询性能问题:直接在数据湖上执行复杂查询通常面临高延迟和低吞吐量的挑战。Dremio通过列式存储、向量化执行和Data Reflections预聚合技术,将查询性能提升10-100倍,复杂查询响应时间从分钟级压缩至亚秒级。
数据治理复杂性:随着数据量的增长,数据治理和安全控制的复杂度也随之增加。Dremio提供强大的数据治理功能,包括数据注释、数据安全、数据版本控制和行级权限管理等,帮助企业确保数据合规并简化数据访问控制 。
资源管理挑战:传统的查询引擎如Presto需要用户手动配置和管理资源,增加了运维复杂度。Dremio通过Kubernetes动态管理Compute Engine节点,实现资源的自动扩缩容和优化调度,降低运维成本。
数据访问门槛:许多业务人员不具备SQL技能,难以直接访问和分析数据。Dremio通过提供统一的SQL接口和自助分析平台,使业务人员能够直接探索和分析数据,减少对IT团队的依赖,提高分析效率 。
5. Dremio的关键特性
数据虚拟化:Dremio的核心特性之一是其数据虚拟化能力,通过Universal Semantic Layer将多源数据映射为逻辑数据集,支持跨格式(Parquet/JSON)的联合查询。这种虚拟化技术允许用户直接访问原始存储层的数据,无需物理迁移或复制。
Data Reflections加速:Data Reflections是Dremio的另一项关键特性,类似于外部数据表上的物化视图。与传统物化视图不同,Dremio的Reflections支持自动路由,系统管理员只需定义加速策略,业务团队无需修改任何查询即可获得加速效果。Reflections可以重新定义子列、分区策略、排序策略和分桶策略,甚至针对特定指标列进行预聚合,显著提升查询性能。
云原生弹性:Dremio采用BYOC(Bring Your Own Cloud)架构,自身不提供存储和计算资源,而是通过Kubernetes动态管理客户提供的计算资源(如AWS EC2实例),实现资源的弹性扩缩容。这种架构使企业能够按需使用云资源,降低基础设施成本。
多源连接:Dremio支持连接多种数据源,包括云存储(S3、Azure Blob)、关系型数据库(MySQL、PostgreSQL、Oracle)、NoSQL数据库(MongoDB)和流数据源(Kafka、Kinesis)等。通过专用的数据湖连接器框架,Dremio能够解析不同数据源的存储格式和访问协议,提供统一的查询接口。
实时分析:Dremio不仅支持对静态数据湖的查询,还能够实时分析流数据。用户可以通过Dremio消费来自Kafka的客户事件流,创建虚拟数据集并使用SQL进行实时查询,实现对业务动态的即时洞察 。
简化数据治理:Dremio通过集中化的元数据管理和权限控制,简化了数据治理流程。它支持与Azure AD、AWS IAM等云服务商的集成,实现细粒度的数据访问控制,并自动记录数据转换路径,提供数据血缘追踪能力,满足合规审计需求。
6. 与同类产品的对比
Dremio与市场上其他数据湖查询引擎(如Presto、Trino)相比,具有以下显著优势:
性能优化:Dremio通过Data Reflections预聚合技术和列式存储优化,实现了比Presto高20-30倍的查询性能。在TPC-H测试中,Dremio的查询性能也显著优于传统数据仓库解决方案,如某案例中将查询响应时间从分钟级压缩至亚秒级,延迟降低45%。
云原生弹性:Dremio基于Kubernetes的BYOC架构支持计算资源的动态扩缩容,而Presto等传统引擎需要用户手动配置和管理资源,增加了运维复杂度。Dremio的Control Plane与Execution Plane分离设计也提供了更好的安全性和可扩展性。
数据虚拟化:Dremio的数据虚拟化技术通过元数据抽象层直接连接多源数据,无需物理迁移,而Presto虽然也支持跨源查询,但缺乏类似的数据抽象层和预聚合加速能力 。
易用性:Dremio提供统一的SQL接口和自助分析平台,降低了技术门槛,使业务人员能够直接访问和分析数据,而无需依赖IT团队。相比之下,Presto需要用户具备更专业的SQL技能和数据处理知识。
数据治理:Dremio内置强大的数据治理功能,包括数据注释、安全控制和行级权限管理等,而Presto等传统引擎需要额外集成治理工具,增加了系统复杂度 。
实时分析能力:Dremio不仅支持对静态数据湖的查询,还能够实时分析流数据,而Presto在流数据处理方面相对薄弱,需要与其他流处理框架(如Kafka)集成才能实现类似功能。
7. Dremio的使用方法
安装与部署:Dremio提供多种部署方式,包括云原生部署(如AWS、Azure、GCP)、本地部署和混合部署。对于云环境,Dremio采用BYOC模式,用户需要自己提供计算资源(如EC2实例)和存储资源(如S3存储桶),Dremio则负责管理这些资源并提供查询加速能力。
数据源连接:Dremio支持连接多种数据源,包括云存储、关系型数据库、NoSQL数据库和流数据源等。连接数据源的步骤如下:
- 登录Dremio Web UI,进入"Sources"页面。
- 点击"+"按钮,选择要连接的数据源类型(如S3、MySQL等)。
- 输入数据源的访问信息(如访问密钥、端点URL等)。
- 测试连接,确保Dremio能够成功访问数据源。
- 保存连接,完成数据源配置。
创建数据集:在Dremio中,用户可以通过SQL查询或可视化界面创建数据集,将原始数据转换为适合分析的格式。创建数据集的示例如下:
-- 连接到S3数据源
USE `s3://my-bucket/my-data`;
-- 创建数据集视图
CREATE VIEW `Sales` AS
SELECT *
FROM `s3://my-bucket/sales_data.csv`
WHERE sale_date BETWEEN '2024-01-01' AND '2024-12-31';
-- 创建预聚合Reflection
CREATE Refection `Sales_Aggregate`
ON `Sales`
AS
SELECT region, SUM(sales_amount) AS total_sales
FROM `Sales`
GROUP BY region;查询优化:Dremio的查询优化器能够自动识别查询模式并应用适当的加速策略。用户可以通过以下方式进一步优化查询性能:
- 创建合适的Reflections,预聚合常用查询结果。
- 使用Columnar Cloud Cache缓存高频访问的数据。
- 调整查询计划,减少数据移动和冗余计算。
- 利用Dremio的分布式执行引擎,实现并行查询处理。
BI工具集成:Dremio可以与多种商业智能工具集成,如Power BI、Tableau和Apache Superset等。以Power BI为例,集成步骤如下:
- 在Power BI中选择"获取数据",然后选择"Dremio"。
- 输入Dremio服务器的IP地址和端口(默认为31010或SSL端口443)。
- 提供Dremio的用户名和密码,或配置Azure AD等云服务商的集成认证。
- 选择要连接的数据库模式和表,完成数据集创建。
- 在Power BI中使用Dremio数据集创建可视化报表。
实时数据处理:Dremio还支持实时数据流处理,可以与Kafka等流处理平台集成,实现对实时数据的分析和可视化 。用户可以通过Dremio消费Kafka主题数据,创建虚拟数据集并使用SQL进行实时查询,无需将数据先写入数据湖。
8. 实际应用场景
制造业预测性维护:某汽车制造商使用Dremio分析生产线传感器数据,实时检测设备异常并预测维护需求。通过Dremio的数据虚拟化技术,将分布在HDFS、S3和关系型数据库中的设备数据整合为统一视图,业务人员可以直接通过Power BI创建可视化报表,无需依赖IT团队。Dremio的列式存储和向量化执行技术使查询性能提升了50倍,从分钟级响应时间缩短至秒级。
金融行业欺诈检测:北美一家大型银行使用Dremio分析来自多个来源的交易数据,实时识别欺诈活动。通过Dremio的Data Reflections技术,对高频查询的交易模式进行预聚合,查询延迟降低了80%。Dremio的元数据抽象层使银行能够直接查询原始数据湖中的交易记录,无需将数据迁移至专门的数据仓库,节省了大量ETL时间和成本。
医疗临床分析:犹他大学医疗保健系统通过Dremio统一来自不同来源的患者数据,支持实时临床分析。Dremio的数据虚拟化技术使医疗团队能够直接查询原始数据湖中的患者记录、检查结果和用药信息,无需进行数据迁移。Dremio的列式存储和内存计算技术使查询性能提升了100倍,医生能够快速获取患者历史数据,制定更精准的治疗方案。
零售业客户洞察:一家大型在线零售商使用Dremio分析来自各种来源的客户数据,个性化产品推荐,提高销售额和客户保留率。通过Dremio的自助分析平台,营销团队可以直接查询数据湖中的客户行为数据,创建可视化报表并进行实时分析。Dremio的云原生弹性架构使零售商能够在促销期间快速扩展计算资源,应对激增的查询需求,同时在淡季缩容以节省成本。
9. 技术优势与挑战
技术优势:
高性能查询:Dremio的列式内存计算和向量化执行技术使其查询性能远超传统数据仓库和数据湖解决方案。在复杂查询场景下,Dremio能够将响应时间从分钟级压缩至亚秒级,显著提高了分析效率。
数据虚拟化:Dremio的数据虚拟化技术通过元数据抽象层直接连接多源数据,无需物理迁移,降低了数据整合的成本和复杂度。这种虚拟化技术使企业能够充分利用现有数据基础设施,避免重复投资。
云原生弹性:Dremio基于Kubernetes的BYOC架构支持计算资源的动态扩缩容,使企业能够按需使用云资源,优化成本。在查询负载高峰期,Dremio可以自动扩展Compute Engine节点,确保查询性能;在低峰期则自动缩容,节省资源开销。
多源连接:Dremio支持连接多种数据源,包括云存储、关系型数据库、NoSQL数据库和流数据源等。这种广泛的连接能力使企业能够整合分散在不同系统中的数据,实现全局分析。
简化数据治理:Dremio内置强大的数据治理功能,包括数据注释、安全控制和行级权限管理等,简化了数据治理流程 。通过与云服务商的集成,Dremio能够自动实施数据安全策略,满足合规审计需求。
挑战与局限:
数据移动限制:虽然Dremio通过数据虚拟化技术减少了数据移动,但在某些场景下仍需将数据复制到特定位置以实现最佳性能。例如,Data Reflections需要将预聚合结果存储在用户指定的S3或HDFS中。
存储依赖:Dremio自身不提供存储资源,需要用户自己管理数据湖的存储。这增加了存储管理的复杂度,特别是在多云环境中。
查询优化复杂度:虽然Dremio的查询优化器能够自动识别查询模式并应用加速策略,但在某些复杂查询场景下仍需用户手动调整查询计划或创建合适的Reflections,增加了使用复杂度。
实时数据处理延迟:虽然Dremio支持实时数据流处理,但在某些高吞吐量场景下仍可能面临延迟问题。需要结合Kafka等流处理平台进行优化,才能实现真正的实时分析。
成本模型:Dremio的BYOC模式虽然降低了基础设施成本,但其计费模型基于Compute Engine的使用时长和资源规模,可能在某些场景下导致不可预测的成本。需要合理规划Reflections和缓存策略,才能优化成本。
10. 未来发展趋势
Dremio作为数据湖查询引擎的领导者,未来发展趋势主要体现在以下几个方面:
AI集成:Dremio正在加强与生成式AI(GenAI)的集成,使企业能够直接在数据湖上运行AI模型,无需将数据迁移至专门的AI平台。这将显著提高AI应用的效率和灵活性。
实时分析增强:随着企业对实时数据洞察需求的增长,Dremio将进一步优化其流数据处理能力,支持更低延迟的实时分析和更复杂的流数据操作 。
多云支持扩展:Dremio将继续扩展其多云支持能力,提供更无缝的跨云数据访问和分析体验。这将帮助企业避免供应商锁定,实现数据的自由流动和共享。
数据治理深化:Dremio将加强其数据治理功能,提供更全面的数据质量、合规和安全控制能力。这将帮助企业满足日益严格的监管要求,如GDPR、CCPA等。
开源生态扩展:Dremio将继续扩展其与Apache生态系统的集成,特别是与Iceberg、Hudi等开放表格式的协同优化。这将为企业提供更灵活的数据湖管理方案,支持流批一体的数据处理需求。
总结:Dremio作为数据湖查询引擎的创新者,通过其独特的数据虚拟化技术和列式存储加速机制,彻底改变了传统大数据查询的方式。它不仅解决了数据孤岛、查询性能和数据治理等核心问题,还提供了云原生弹性和多源连接等关键特性,使企业能够更高效地利用数据湖中的数据,加速决策过程。随着AI集成、实时分析增强和多云支持扩展等未来趋势的发展,Dremio有望进一步巩固其在数据湖分析领域的领导地位,为企业提供更强大的数据洞察能力。
参考资料:
技术做了多年,却总在“重复踩坑”?点我关注,陪你建立底层认知!
这里有:
📌 技术决策深度文(从选型到落地的全链路分析)
💭 开发者成长思考(职业规划/团队管理/认知升级)
🎯 行业趋势观察(AI对开发的影响/云原生下一站)
关注我,每周日与你聊“技术内外的那些事”,让你的代码之外,更有“技术眼光”。
日更专刊:
🥇 《Thinking in Java》 🌀 java、spring、微服务的序列晋升之路!
🏆 《Technology and Architecture》 🌀 大数据相关技术原理与架构,帮你构建完整知识体系!关于博主:


















 4093
4093


 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










