






虽然很早就学会了 Python 的Pandas 库基础使用,但最近处理数据时发现还有很多知识需要掌握,这里我将介绍自己所学的 Pandas库使用技巧。
首先导入 Pandas 库。
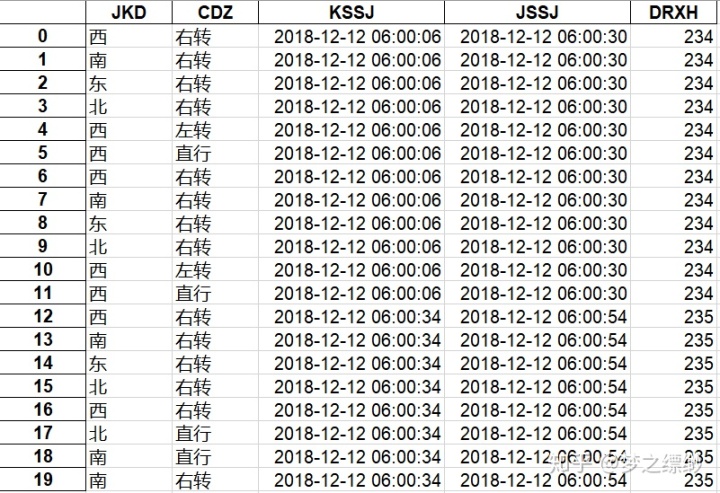
import 下面是原表图片:
- 读取文件
Pandas 读取的文件一般是 csv 或 xls 或 xlsx 格式,若文件与 Py 文件在同一个文件夹下,则只需要读取相对路径,如下面所示:
data_1 否则,则需要读取绝对路径,这里要注意转义字符()的使用。
这里我已经将数据读入,如下面所示(最左边数字代表索引):
Unnamed: 0 JKD CDZ KSSJ JSSJ DRXH
0 0 西 右转 2018-12-12 06:00:06 2018-12-12 06:00:30 234
1 1 南 右转 2018-12-12 06:00:06 2018-12-12 06:00:30 234
2 2 东 右转 2018-12-12 06:00:06 2018-12-12 06:00:30 234
3 3 北 右转 2018-12-12 06:00:06 2018-12-12 06:00:30 234
4 4 西 左转 2018-12-12 06:00:06 2018-12-12 06:00:30 234
5 5 西 直行 2018-12-12 06:00:06 2018-12-12 06:00:30 234
6 6 西 右转 2018-12-12 06:00:06 2018-12-12 06:00:30 234
7 7 南 右转 2018-12-12 06:00:06 2018-12-12 06:00:30 234
8 8 东 右转 2018-12-12 06:00:06 2018-12-12 06:00:30 234
9 9 北 右转 2018-12-12 06:00:06 2018-12-12 06:00:30 234
10 10 西 左转 2018-12-12 06:00:06 2018-12-12 06:00:30 234
11 11 西 直行 2018-12-12 06:00:06 2018-12-12 06:00:30 234
12 12 西 右转 2018-12-12 06:00:34 2018-12-12 06:00:54 235
13 13 南 右转 2018-12-12 06:00:34 2018-12-12 06:00:54 235
14 14 东 右转 2018-12-12 06:00:34 2018-12-12 06:00:54 235
15 15 北 右转 2018-12-12 06:00:34 2018-12-12 06:00:54 235
16 16 西 右转 2018-12-12 06:00:34 2018-12-12 06:00:54 235
17 17 北 直行 2018-12-12 06:00:34 2018-12-12 06:00:54 235
18 18 南 直行 2018-12-12 06:00:34 2018-12-12 06:00:54 235
19 19 南 右转 2018-12-12 06:00:34 2018-12-12 06:00:54 235- 选取n行
选取前2行([]中也可以写成[0:2])。
data_2 选取第2到5行就不再多说。
除了上面的方法,还可以直接 data[0:5] 这样
那么,接下来我想选取 JDK 为西的所有行,方法就是下面所示。
data_2 这样我还不满足,除了 JDK 为西,CDZ 要为直行或者左转。
data_3 而假设我们的 CDZ 列有‘直行’和‘行直’数据,筛选它们则可以考虑 str.contains('|') 方法。
- 选取n列
选取单列或多列有两种方法。
data_4 或者
data_4 那么接下来我希望筛选出 DRXH 列数值为235的行,就按下面的方法。
data_5 注意上面,需要区分该列包含的数据为数值还是字符。
或者用下面的方法。
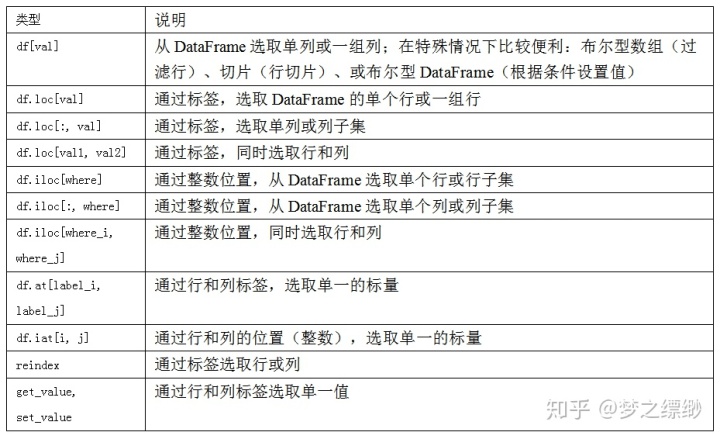
data_5 下面是一个关于 DataFrame索引选项的小总结,图源网络。
今天主要就写这么多,之后还会有其它的记录。















 299
299











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









