







前言:其实很早之前就想开始写写深度强化学习(Deep reinforcement learning)了,但是一年前DQN没调出来,没好意思写哈哈,最近呢无意中把打砖块游戏Breakout训练到平均分接近40分,最高分随便上50(虽说也不算太好,但好歹也体现了DRL的优势),于是就写写吧~
提到深度强化学习的成名作,很多人可能会觉得是2016年轰动一时的AlphaGo,从大众来看是这样的,但真正让深度强化学习火起来并获得学术界蹭蹭往上涨关注度的,当属Deep Q-learning Network(DQN),最早见于2013年的论文《Playing Atari with Deep Reinforcement Learning》。
2012年,深度学习刚在ImageNet比赛大获全胜,紧接着DeepMind团队就想到把深度网络与强化学习结合起来,思想是基于强化学习领域很早就出现的值函数逼近(function approximation),但是通过深度神经网络这一神奇的工具,巧妙地解决了状态维数爆炸的问题!
怎么解决的呢?让我们走进DQN,一探究竟。
CNN实现Q(s, a)
如果我们以纯数学的角度来看动作值函数
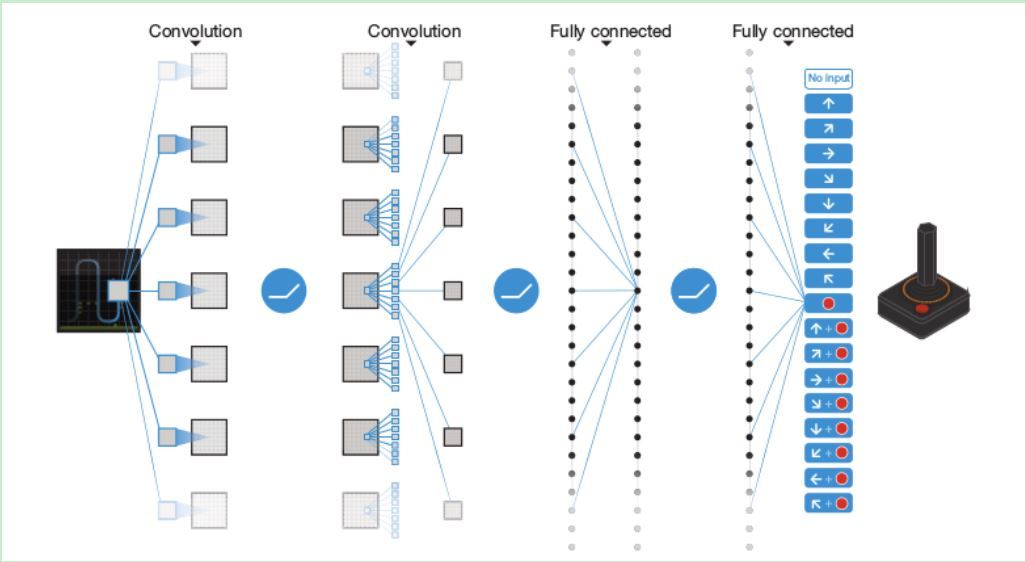
就是胜利。于是用CNN完成这种映射的做法应运而生,先上一幅架构图:
DQN
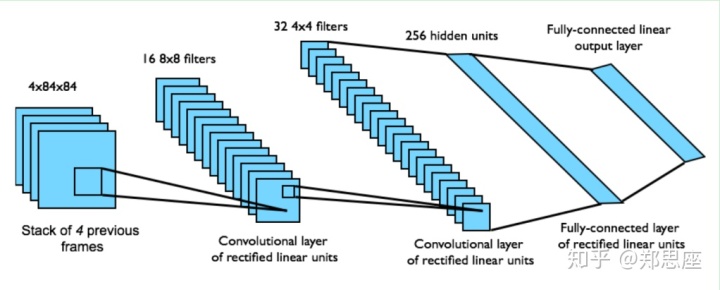
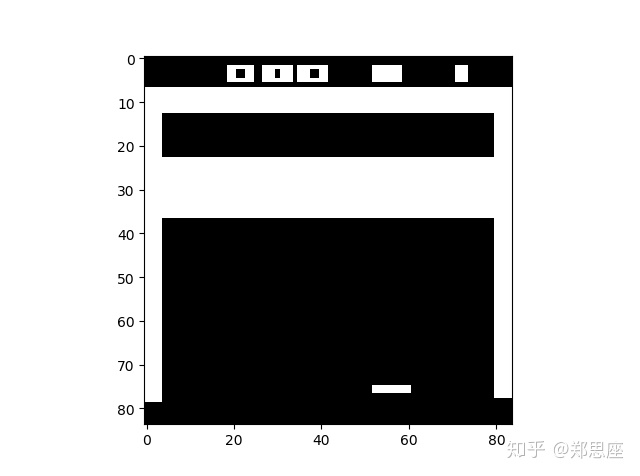
通过gym模块输出Atari环境的游戏,状态空间都是(210, 160, 3),即210*160的图片大小,3个通道,在输入CNN之前需要通过图像处理二值化并缩小成84*84。由于如果将一张图片作为状态输入信息,很多隐藏信息就会忽略(比如球往哪边飞),于是论文中把连续的4帧图片作为状态输入。所以在pytorch中,CNN的输入就是
- 第一层卷积核8*8,stride=4,输出通道为32,ReLU
- 第二层卷积核4*4,stride=2,输出通道为64,ReLU
- 第三层卷积核3*3,stride=1,输出通道为64,ReLU
- 第三层输出经过flat之后维度为3136,然后第四层连接一个512大小的全连接层
- 第五层为动作空间大小的输出层,Breakout游戏中为4,表示每种动作的概率
搭建CNN的py文件在q_model.py中,并手动随机生成torch.randn(32, 4, 84, 84)向量用于测试网络架构的正确性:
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
import cv2
import gym
import matplotlib.pyplot as plt
class QNetwork(nn.Module):
"""Actor (Policy) Model."""
def __init__(self, state_size, action_size, seed):
"""Initialize parameters and build model.
Params
======
state_size (int): Dimension of each state
action_size (int): Dimension of each action
seed (int): Random seed
"""
super(QNetwork, self).__init__()
self.seed = torch.manual_seed(seed)
"*** YOUR CODE HERE ***"
self.conv = nn.Sequential(
nn.Conv2d(state_size[1], 32, kernel_size=8, stride=4),
nn.ReLU(),
nn.Conv2d(32, 64, kernel_size=4, stride=2),
nn.ReLU(),
nn.Conv2d(64, 64, kernel_size=3, stride=1),
nn.ReLU()
)
self.fc = nn.Sequential(
nn.Linear(64*7*7, 512),
nn.ReLU(),
nn.Linear(512, action_size)
)
def forward(self, state):
"""Build a network that maps state -> action values."""
conv_out = self.conv(state).view(state.size()[0], -1)
return self.fc(conv_out)
def pre_process(observation):
"""Process (210, 160, 3) picture into (1, 84, 84)"""
x_t = cv2.cvtColor(cv2.resize(observation, (84, 84)), cv2.COLOR_BGR2G 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 56
56











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









