






在matlab中,既有各種分類器的訓練函數,比如“fitcsvm”,也有圖形界面的分類學習工具箱,里面包含SVM、決策樹、Knn等各類分類器,使用非常方便。接下來講講如何使用。
啟動:
點擊“應用程序”,在面板中找到“Classification Learner”圖標點擊即啟動,也可以在命令行輸入“classificationlearner”,回車,也可啟動。如下圖:
導入數據:
點擊“New Session”,可以從工作空間或文件中導入數據。選擇數據后,導入分為三步:
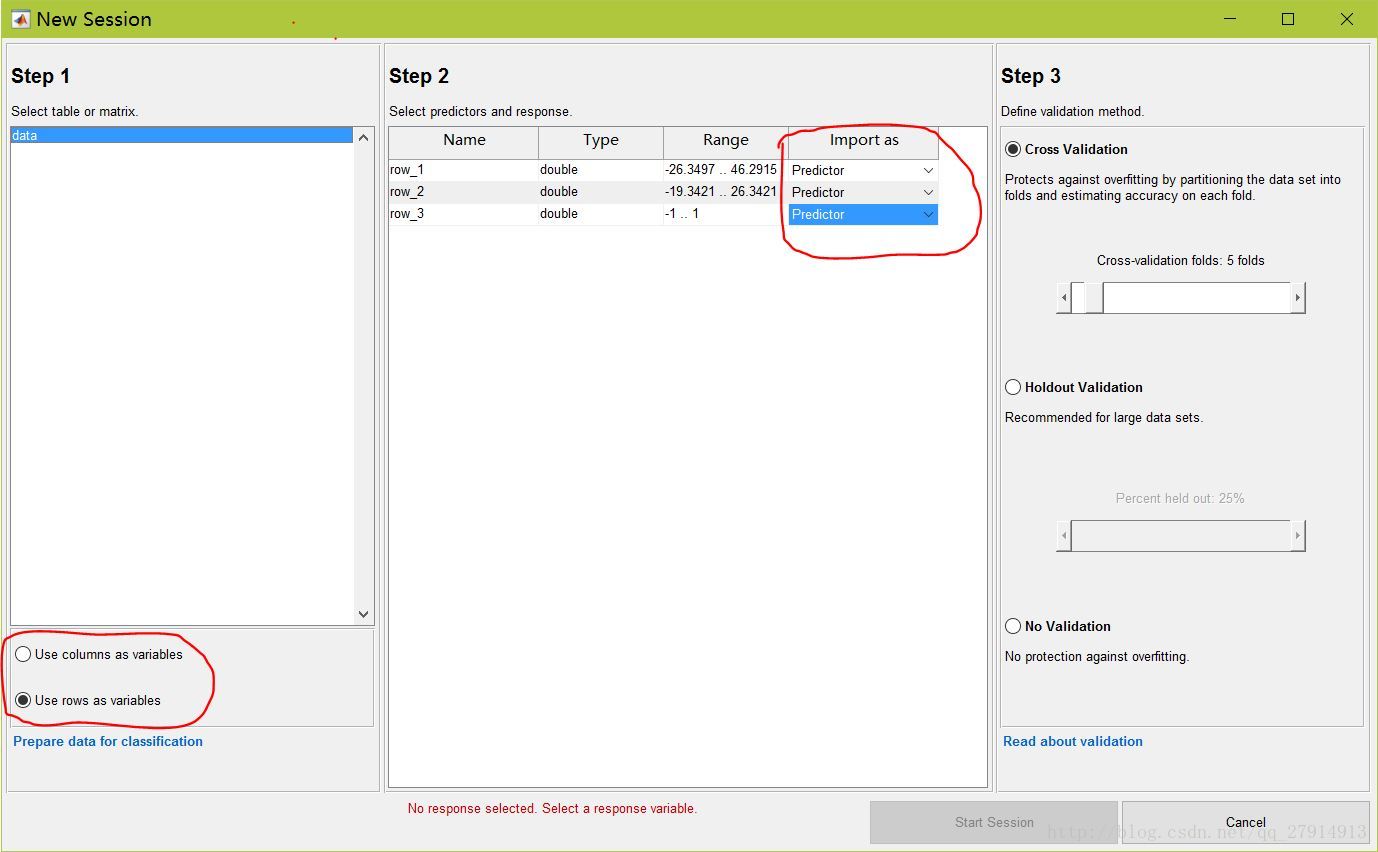
第一步,確定你的數據格式,這里導入的數據是一個矩陣,既有樣本輸入也有對應的輸出。比如,我導入的數據data是3*3000的矩陣,3000個樣本,每個樣本兩個特征值,第三行是每個樣本對應的輸出。這時我應該選擇“Use row as variables”,如果數據格式為3000*3,則選擇“Use column as variables”。
第二步,指定哪一行為“response”即輸出響應,在本數據中,第三行為輸出,其余為“predictor”。
第三步,是否需要驗證,一般都選擇交叉驗證“Cross Validation”,folds表示幾次,自己選擇即可。
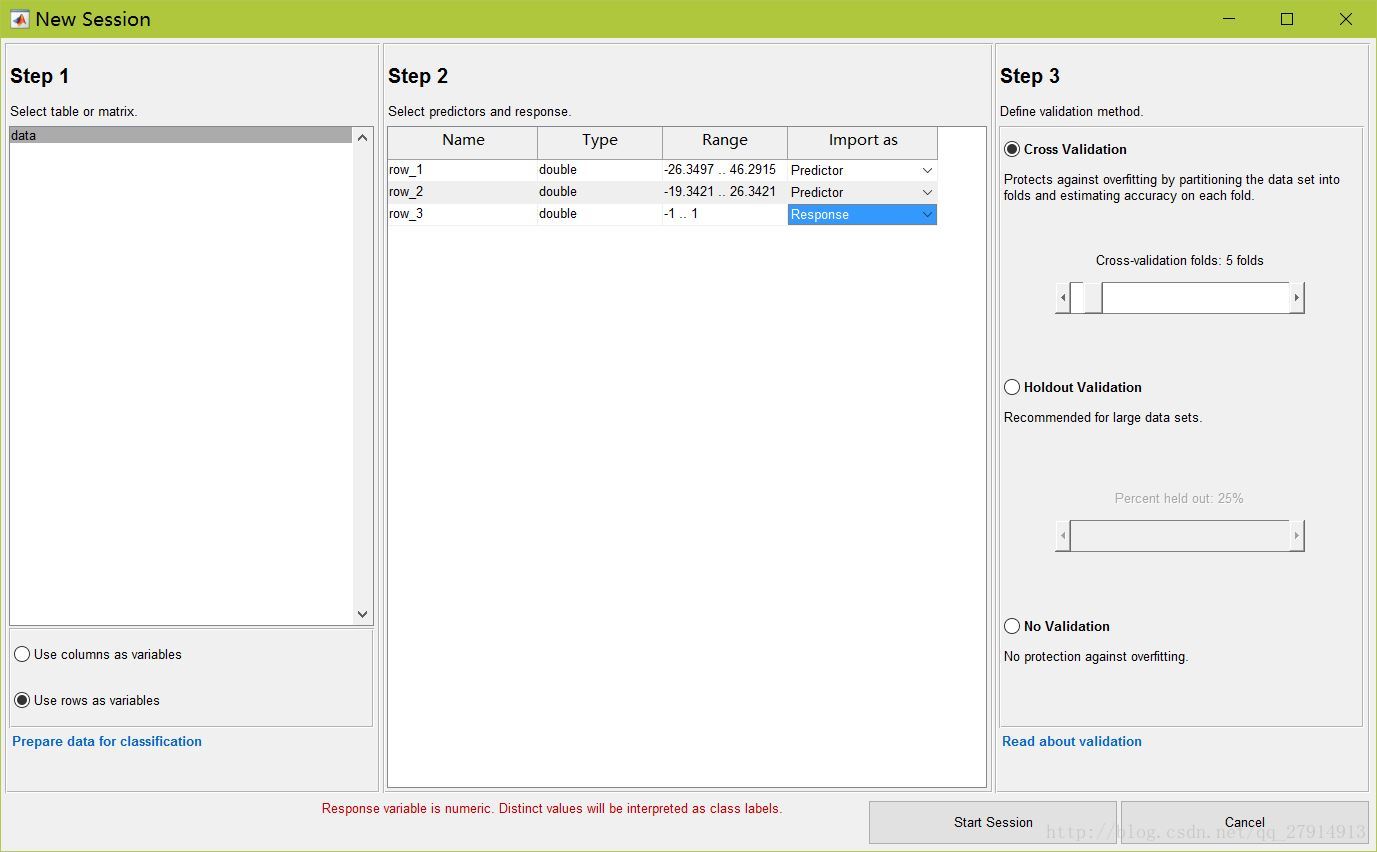
確定后,點擊“start session”。
選擇分類器:
如下圖,原始數據的散點圖會顯示出來,由於這數據只有兩維,因此可以全部顯示在二維坐標中。如果你的數據多於兩維,二維坐標系不能完全顯示每一維,你可以在右邊紅圈的X、Y下拉條中選擇顯示哪兩維。
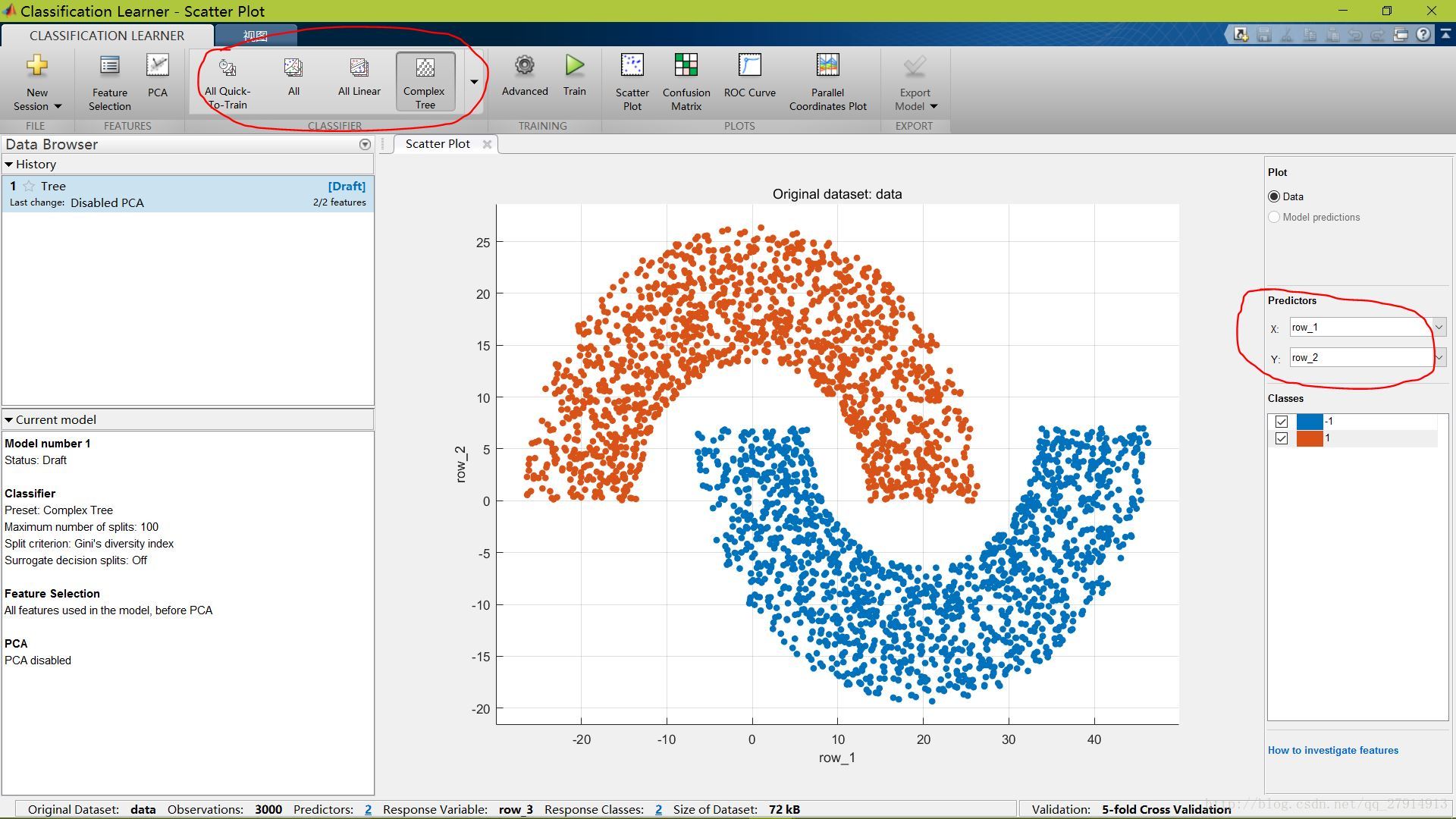
訓練前可以選擇訓練的模型,點擊紅圈中的下拉箭頭,可以看到各類訓練模型,選擇一個即可,也可以選擇某一類的“ALL”,該類所有模型都會訓練一遍。
選好模型后,點擊“train”,開始訓練。
訓練結果:
訓練結果顯示在左邊,每個模型訓練后的准確率都會顯示出來,最高准確率會被標注,下面即為模型的信息。
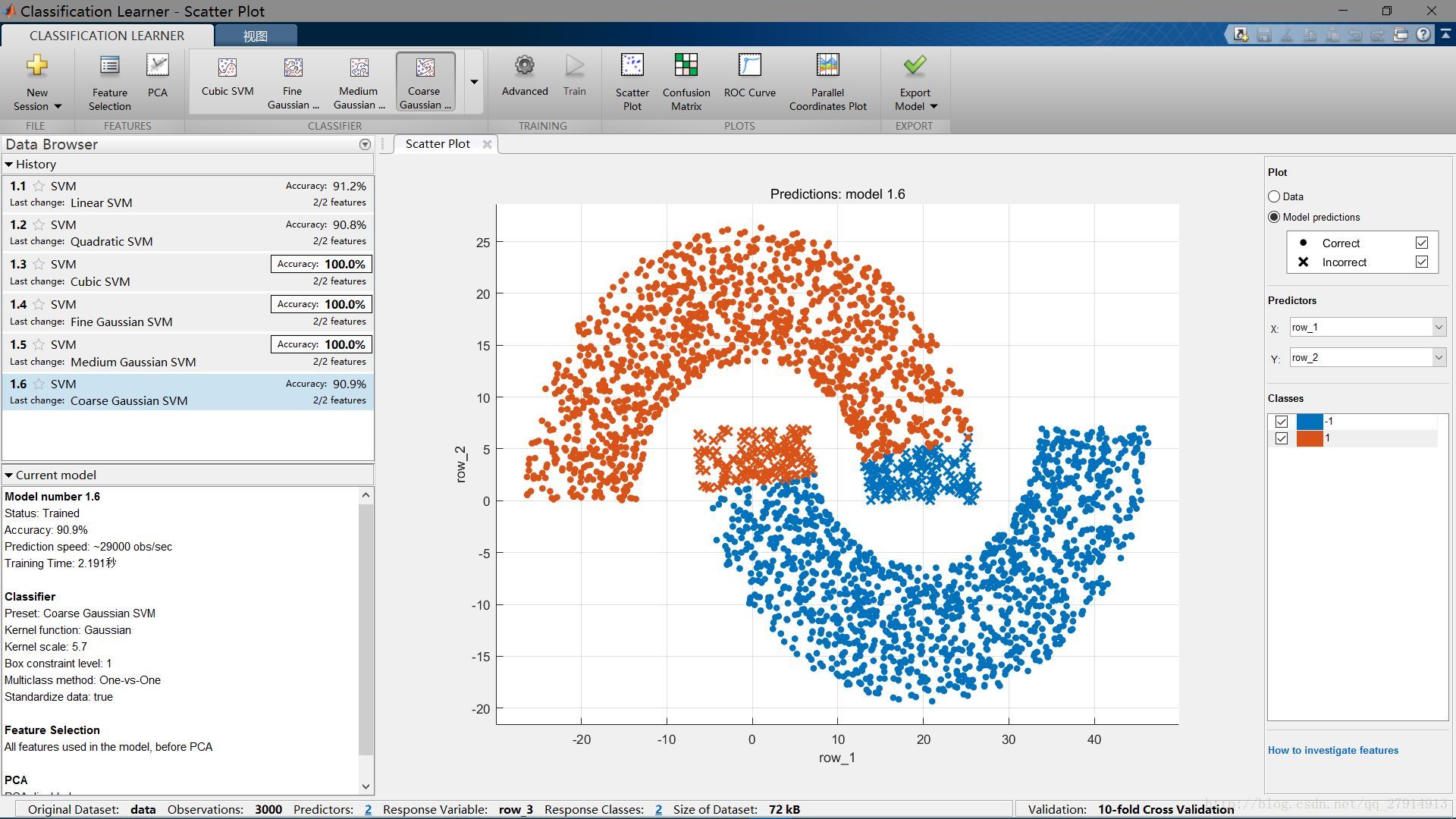
點擊“Advance”可以設置模型的具體參數。點擊“Confusion Matrix”可以查看混淆矩陣等。
點擊“Export Model”可以將模型導出到工作空間,這樣就可以利用模型來測試新的數據。也可以導出為代碼,方便研究。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









