





网易云歌单歌曲实时拉取
最近个人公众号Mozi的bug日志上线了新的音乐推送API,下面来讲讲推送的实现过程。
一、抓取目的
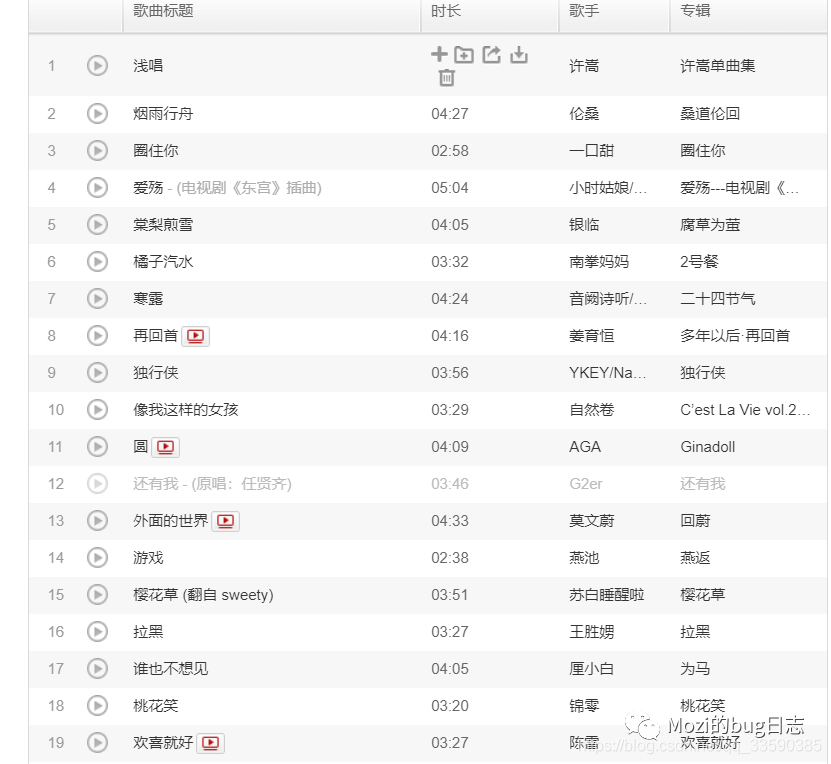
抓取歌单中的歌曲列表,并提取对应歌曲的外链、歌曲名单以及作者名
测试歌曲外链,删除其中失效外链
存储不同歌单中的歌曲数据到csv中以便后续读取
二、读取并存储cookies
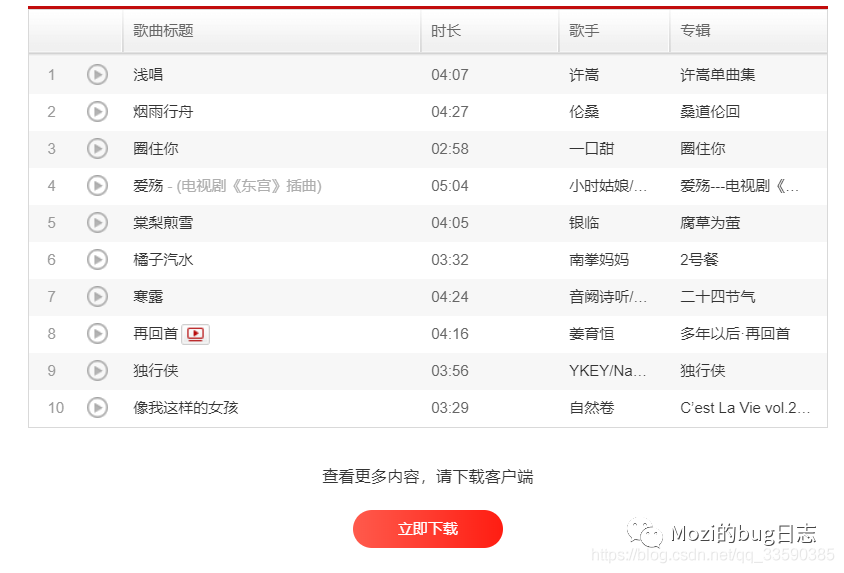
经实验发现,若在未登录状态下查看歌单列表时,仅显示前10条歌曲信息:
为了可以稳定的获取对应的歌单列表,这里需要获取cookie,进行cookie登录,这里选择selenium框架来进行获取:
def getcookie():
driver = webdriver.Chrome('chromedriver.exe')
driver.get('https://music.163.com/')
time.sleep(30)
#在30s内通过网页进行登录
cookie = driver.get_cookies()
#在登陆之后直接获取cookie
driver.quit()
with open('wyy_cookie.pkl', 'wb') as f:
#为了方便后续读取,保存cookie为pkl格式
pickle.dump(cookie, f)
return cookie
三、获取歌单列表
通过观察网页源码,歌单列表是镶嵌在iframe框架中的,直接通过通过类似于request框架和urllib框架难以获取iframe内的元素,且在加载网页时,并未发现有post请求的preview里或加载的js内包含关于歌曲列表的信息,因此只好选取selenium来获取歌单列表信息。
具体代码如下所示:
def get_list(url, cookie = None):
options = webdriver.ChromeOptions()
options.add_argument('--no-sandbox') # 解决DevToolsActivePort文件不存在的报错
options.add_argument('window-size=1600x900') # 指定浏览器分辨率
options.add_argument('--disable-gpu') # 谷歌文档提到需要加上这个属性来规避bug
options.add_argument('--hide-scrollbars') # 隐藏滚动条, 应对一些特殊页面
options.add_argument('blink-settings=imagesEnabled=false') # 不加载图片, 提升速度
options.add_argument('--headless') # 浏览器不提供可视化页面. linux下如果系统不支持可视化不加这条会启动失败
driver = webdriver.Chrome(options = options, executable_path='./chromedriver')
driver.get(url)
#加载cookies
driver.delete_all_cookies()
for cookie_ in cookie:
driver.add_cookie(cookie_)
time.sleep(3)
driver.refresh()
#获取iframe内容
iframe_elemnt = driver.find_element_by_id("g_iframe")
print(iframe_elemnt)
driver.switch_to.frame(iframe_elemnt)
print(driver.page_source)
#获取歌单名称
play_list_name = driver.find_element_by_xpath('//h2[@class=\'f-ff2 f-brk\']').text
#保存歌曲的id,名字,作者
id = []
name = []
author = []
list_id = driver.find_elements_by_xpath('//tbody//tr//div[@class=\'ttc\']//span/a')
for i in list_id:
#歌曲id转化为外链
temp = i.get_attribute('href').replace('?','/media/outer/url?')
temp = temp + '.mp3'
print(temp)
id.append(temp)
list_name = driver.find_elements_by_xpath('//tbody//tr//div[@class=\'ttc\']//span//a/b')
for i in list_name:
name.append(i.get_attribute('title'))
list_author = driver.find_elements_by_xpath('//tbody//tr//div[@class=\'text\']/span')
for i in list_author:
author.append(i.get_attribute('title'))
#保存为csv
dict = {'id': id, 'name': name, 'author': author}
df = pd.DataFrame(dict, columns = ['id', 'name', 'author'])
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:58.0) Gecko/20100101 Firefox/58.0'}
# 验证外链的有效性
for index, row in df.iterrows():
data = requests.get(row['id'], headers=header)
print(data.url)
if "404" in data.url:
df.drop(index, axis = 0,inplace = True)
print(index)
df.reset_index()
path = play_list_name + '.csv'
df.to_csv(path, index = 0)
这样便可以保存为csv格式,方便公众号接口使用。















 4073
4073











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









