







我们完成了文章画像和用户画像的构建,画像数据主要是提供给召回阶段的各种召回算法使用。接下来,我们还要为排序阶段的各种排序模型做数据准备,通过特征工程将画像数据进一步加工为特征数据,以供排序模型直接使用。
我们可以将特征数据存储到 Hbase 中,这里我们先在 Hbase 中创建好 ctr_feature_article 表 和 ctr_feature_user 表,分别存储文章特征数据和用户特征数据
-- 文章特征表create 'ctr_feature_article', 'article'-- 如 article:13401 timestamp=1555635749357, value=[18.0,0.08196639249252607,0.11217275332895373,0.1353835167902181,0.16086650318453152,0.16356418791892943,0.16740082750337945,0.18091837445730974,0.1907214431716628,0.2........................-0.04634634410271921,-0.06451843378804649,-0.021564142420785692,0.10212902152136256]-- 用户特征表create 'ctr_feature_user', 'channel'-- 如 4 column=channel:13, timestamp=1555647172980, value=[]构建文章特征
文章特征包括文章关键词权重、文章频道以及文章向量,我们首先读取文章画像
spark.sql("use article")article_profile = spark.sql("select * from article_profile")在文章画像中筛选出权重最高的 K 个关键词的权重,作为文章关键词的权重向量
def article_profile_to_feature(row): try: article_weights = sorted(row.keywords.values())[:10] except Exception as e: article_weights = [0.0] * 10 return row.article_id, row.channel_id, article_weightsarticle_profile = article_profile.rdd.map(article_profile_to_feature).toDF(['article_id', 'channel_id', 'weights'])article_profile 结果如下所示,weights 即为文章关键词的权重向量
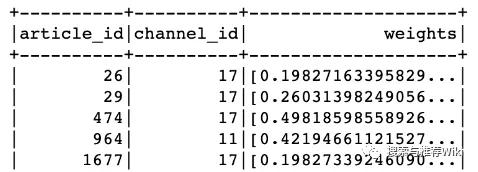
接下来,读取文章向量信息,再将频道 ID 和文章向量加入进来,利用 article_id 将 article_profile 和 article_vector 进行内连接,并将 weights 和 articlevector 转为 vector 类型
article_vector = spark.sql("select * from article_vector")article_feature = article_profile.join(article_vector, on=['article_id'], how='inner')def feature_to_vector(row): from pyspark.ml.linalg import Vectors return row.article_id, row.channel_id, Vectors.dense(row.weights), Vectors.dense(row.articlevector)article_feature = article_feature.rdd.map(feature_to_vector).toDF(['article_id', 'channel_id', 'weights', 'articlevector'])最后,我们将 channel_id, weights, articlevector 合并为一列 features 即可(通常 channel_id 可以进行 one-hot 编码,我们这里先省略了)
from pyspark.ml.feature import VectorAssemblercolumns = ['article_id', 'channel_id', 'weights', 'articlevector']article_feature = VectorAssembler().setInputCols(columns[1:4]).setOutputCol("features").transform(article_feature)article_feature 结果如下所示,features 就是我们准备好的文章特征

最后,将文章特征结果保存到 Hbase 中
def save_article_feature_to_hbase(partition): import happybase pool = happybase.ConnectionPool(size=10, host='hadoop-master') with pool.connection() as conn: table = conn.table('ctr_feature_article') for row in partition: table.put('{}'.format(row.article_id).encode(), {'article:{}'.format(row.article_id).encode(): str(row.features).encode()})article_feature.foreachPartition(save_article_feature_to_hbase)构建用户特征
由于用户在不同频道的偏好差异较大,所以我们要计算用户在每个频道的特征。首先读取用户画像,将空值列删除
spark.sql("use profile")user_profile_hbase = spark.sql("select user_id, information.birthday, information.gender, article_partial, env from user_profile_hbase")user_profile_hbase 结果如下所示,其中 article_partial 为用户标签及权重,如 (['18:vars': 0.2, '18: python':0.2, ...], ['19:java': 0.2, '19: javascript':0.2, ...], ...) 表示某个用户在 18 号频道的标签包括 var、python 等,在 19 号频道的标签包括 java、javascript等。
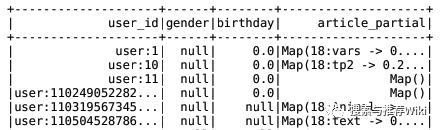
由于 gender 和 birthday 两列空值较多,我们将这两列去除(实际场景中也可以根据数据情况选择填充)
# 去除空值列user_profile_hbase = user_profile_hbase.drop('env', 'birthday', 'gender')提取用户 ID,获取 user_id 列的内容中 : 后面的数值即为用户 ID
def get_user_id(row): return int(row.user_id.split(":")[1]), row.article_partialuser_profile_hbase = user_profile_hbase.rdd.map(get_user_id)将 user_profile_hbase 转为 DataFrame 类型
from pyspark.sql.types import *_schema = StructType([ StructField("user_id", LongType()), StructField("weights", MapType(StringType(), DoubleType()))])user_profile_hbase = spark.createDataFrame(user_profile_hbase, schema=_schema)接着,将每个频道内权重最高的 K 个标签的权重作为用户标签权重向量
def frature_preprocess(row): from pyspark.ml.linalg import Vectors user_weights = [] for i in range(1, 26): try: channel_weights = sorted([row.weights[key] for key in row.weights.keys() if key.split(':')[0] == str(i)])[:10] user_weights.append(channel_weights) except: user_weights.append([0.0] * 10) return row.user_id, user_weightsuser_features = user_profile_hbase.rdd.map(frature_preprocess).collect()user_features 就是我们计算好的用户特征,数据结构类似 (10, [[0.2, 2.1, ...], [0.2, 2.1, ...]], ...),其中元组第一个元素 10 即为用户 ID,第二个元素是长度为 25 的用户频道标签权重列表,列表中每个元素是长度为 K 的用户标签权重列表,代表用户在某个频道下的标签权重向量。
最后,将用户特征结果保存到 Hbase,利用 Spark 的 batch() 方法,按频道批量存储用户特征
import happybase# 批量插入Hbase数据库中pool = happybase.ConnectionPool(size=10, host='hadoop-master', port=9090)with pool.connection() as conn: ctr_feature = conn.table('ctr_feature_user') with ctr_feature.batch(transaction=True) as b: for i in range(len(user_features)): for j in range(25): b.put("{}".format(res[i][0]).encode(),{"channel:{}".format(j+1).encode(): str(res[i][1][j]).encode()}) conn.close()Apscheduler 定时更新
定义文章特征和用户特征的离线更新方法
def update_ctr_feature(): """ 更新文章特征和用户特征 :return: """ fp = FeaturePlatform() fp.update_user_ctr_feature_to_hbase() fp.update_article_ctr_feature_to_hbase()在 Apscheduler 中添加定时更新文章特征和用户特征的任务,每隔 4 小时运行一次
from apscheduler.schedulers.blocking import BlockingSchedulerfrom apscheduler.executors.pool import ProcessPoolExecutor# 创建scheduler,多进程执行executors = { 'default': ProcessPoolExecutor(3)}scheduler = BlockingScheduler(executors=executors)# 添加一个定时运行文章画像更新的任务, 每隔1个小时运行一次scheduler.add_job(update_article_profile, trigger='interval', hours=1)# 添加一个定时运行用户画像更新的任务, 每隔2个小时运行一次scheduler.add_job(update_user_profile, trigger='interval', hours=2)# 添加一个定时运行特征中心平台的任务,每隔4小时更新一次scheduler.add_job(update_ctr_feature, trigger='interval', hours=4)scheduler.start()















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









