






承接上文,对原地数组操作的进一步理解
- 交代下背景:利用创建新数组的方法删除重复数据,得到新数组。这种方案需要开辟新的数组,提高了空间复杂度,也就是空间复杂度是O(N),而同时由于需要计算新数组的初始容量,还需要多出一次迭代去计算,所以整个方法的时间复杂度就来都了O(N*N)。
- 优化方案:利用原地数组操作直接在原数组上操作,不额外创建新数组。核心算法相似,但是又能少一遍计算新数组容量的迭代操作。从时间复杂度和空间复杂度上都得到了提升。
示例如下:
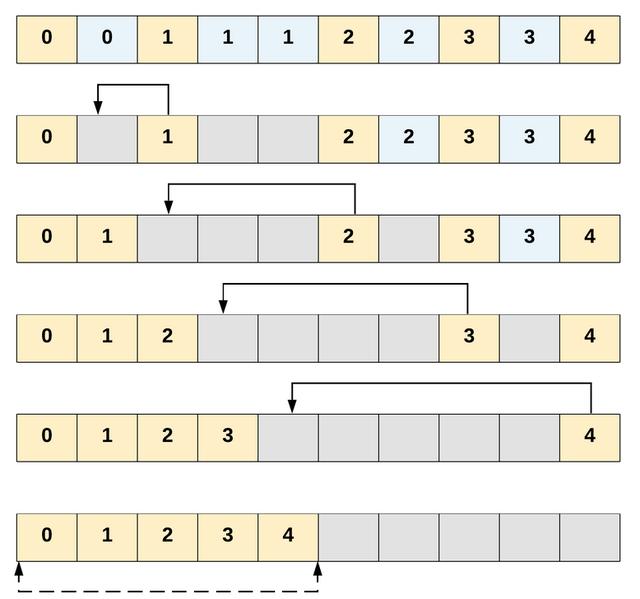
- 说明:在原始数组上修改,所有的唯一元素前移,重复的数据依然存在于数组中。需要返回的数据长度是仅仅唯一的这5个。
- 实现原理:利用了双指针技术,同时在两个不同的地方进行迭代。1、一个指针用于读取数组内元素来确定重复的元素,可以叫他为读指针2、一个指针用于提前记录下一个需要插入的数组位置,一旦找到下一个唯一元素则插入。可以叫他为写指针。
- 细节实现
// 第一个元素已经是正确位置,不需要变动
int writePointer = 1;
// 遍历数组
for (int readPointer = 1; readPointer < nums.length; readPointer++) {
// 如果当前读到的元素与前一个元素不同
if (nums[readPointer] != nums[readPointer - 1]) {
// 通过写指针位置将他写入到数组前面
nums[writePointer] = nums[readPointer];
// 将写指针自增1,向后移动,保证下一个元素可被写入.
writePointer++;
}
}
// 写指针的即为唯一元素的个数
return writePointer;

- 解惑:你有可能或惊讶于这也行,没被读到的数据被覆盖掉那不就错乱了。核心点就在于你要想明白的是写指针是永远不会跑到读指针的前面去的,这样我们也就不可能覆盖掉未读到的数据。
- 双指针技术是原地数组操作算法的众多技术之一,上面的小例子也只是双指针技术的小试牛刀。
- 原地数组操作的使用场景:知道什么时候使用原地数组操作是十分重要的,因为合适才重要。如果我们以后还需要原始数组,那我们就不应该覆盖掉他。在这种场景中,最好的方式就是弄一个副本,或者干脆就不用原地操作技术。当你面对的是别人写的已有的代码的时候就要更加的小心谨慎了。否则你动了别人需要依赖的原始数组,那应用就坏掉了,后果还是蛮严重的。原地数组操作的价值就在于场景适当的情况他的空间复杂度十分优秀,从O(N)直降到O(1)。
所谓存在即合理,合理利用,才能发挥出应用的效能。















 1653
1653











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









