






这里写自定义目录标题
【地表最强】亚马逊amazon高性能爬虫 【关键词列表页采集】—【排位解析】
本文只介绍页面解析代码
如果想要采集完整的数据,请移步我的其他文章
如何采集搞效率采集亚马逊数据
在今天的技术文章中,我们将深入探讨如何使用Scrapy框架来解析亚马逊关键词搜索结果页面的数据。Scrapy是一个快速、高层次的Web爬虫框架,用于抓取网站数据并从页面中提取结构化的数据。首先,我们需要安装Scrapy并创建一个新的爬虫项目。接着,我们会编写Spider来模拟关键词搜索的请求,并针对亚马逊的搜索结果页面进行定向爬取。
在解析过程中,我们会使用Scrapy的选择器来提取商品名称、价格、评价数以及商品链接等信息。通过XPath或CSS选择器,我们能够精确地定位到这些数据所在的HTML元素。随后,我们将这些数据保存为JSON或CSV格式,以便于后续的数据分析或报告生成。
本教程的重点在于展示如何应对亚马逊的反爬虫机制,保持爬虫的稳定运行,并且确保数据的准确性。通过本文的指导,即使是初学者也能够掌握使用Scrapy对亚马逊关键词搜索页面进行数据抓取的基本方法。
asin_info = {}
asin_info[“title”] = title #商品标记
asin_info[“asin”] = dataAsin #商品asin
asin_info[“price”] = price #价格
asin_info[“ratting”] = ratting #打分
asin_info[“ratting_num”] = parseNumber(ratting_num) #打分数
asin_info[“goods_type”] = goods_type #广告还是自然排名
asin_info[“img_url”] = pic #首图
asin_info[“coupon”] = coupon #优惠券
asin_info[“deal”] = deal #促销
asin_info[“prime”] = prime #会员折扣
asin_info[“promotion”] = promotion
asin_info[“bs”] = bs
asin_info[“ac”] = ac
asin_info[“sales_num”] = sale_num #销量2024年更新
asin_info[“uuid”] = uuid #页面唯一标识
费话少说直接上代码
def parseAdsLocation(self, adsItem, Respons, country_code, asins, pageNo):
adsRankCount = 0 # 广告总排名
natureRankCount = 0 # 自然总排名
BestadsElement = False
BestnatureElement = False
# 判断是否存在数据
searchResultElements = Respons.xpath('//span[@data-component-type="s-search-results"]')
if (not searchResultElements):
return [], [], 0
# 获取所有商品信息
asinElements = searchResultElements[0].xpath(
'//div[@class="s-main-slot s-result-list s-search-results sg-row"]/div[@data-uuid!=""]')
if (len(asinElements) == 0):
print('没有广告数据====================================')
return [], [], 0
asd_asin_arr = []
for asd_asin in asins.split(","):
if (len(asd_asin) > 2): asd_asin_arr.append(asd_asin)
Elements = []
key_asins = []
otherPlace = []
for asinElement in asinElements:
Element = adsItem.copy()
# 品牌广告
asinElement_text = asinElement.extract()
if ("s-result-item s-widget s-widget-spacing-large AdHolder s-flex-full-width" in asinElement_text):
for asd_asin in asd_asin_arr:
if (asd_asin in asinElement_text):
otherPlace.append('品牌广告')
break
continue
# 视频广告
if ("sbv-video-single-product" in asinElement_text):
for asd_asin in asd_asin_arr:
if (asd_asin in asinElement_text):
otherPlace.append('视频广告')
break
continue
if ("a-size-medium-plus a-color-base" in asinElement_text and "Amazon’s Choice" in asinElement_text):
for asd_asin in asd_asin_arr:
if (asd_asin in asinElement_text):
otherPlace.append('AC推荐')
break
continue
if ("MAIN-SHOPPING_ADVISER" in asinElement_text and "HIGHLY RECOMMENDED" in asinElement_text):
for asd_asin in asd_asin_arr:
if (asd_asin in asinElement_text):
otherPlace.append('ER推荐')
break
continue
if ("MAIN-SHOPPING_ADVISER" in asinElement_text and "Climate Pledge Friendly" in asinElement_text):
print("CLIMATE PLEDGE FRIENDLY")
for asd_asin in asd_asin_arr:
if (asd_asin in asinElement_text):
otherPlace.append('气候友好保证')
break
continue
if (
"a-size-medium-plus a-color-base" in asinElement_text and "Top rated from our brands" in asinElement_text):
for asd_asin in asd_asin_arr:
if (asd_asin in asinElement_text):
otherPlace.append('TR推荐')
break
continue
# 高度推荐 HIGHLY RATED
if ("a-size-medium-plus a-color-base" in asinElement_text and "Highly rated" in asinElement_text):
print("hahahhahahaha**************", asd_asin_arr)
for asd_asin in asd_asin_arr:
if (asd_asin in asinElement_text):
otherPlace.append('HR推荐')
break
continue
# print( Element['ads_rank']," Element['ads_rank']====================")
sponsoredElements1 = asinElement.css('span[class="s-label-popover-default"]')
sponsoredElements2 = asinElement.css('span[class="puis-label-popover-default"]')
sponsoredElementsmx = asinElement.css('span[class="puis-label-popover-hover"]')
sponsoredElements = False
if (len(sponsoredElements1) > 0 or len(sponsoredElements2) > 0 or len(sponsoredElementsmx) > 0):
sponsoredElements = True
dataAsin = asinElement.css('div::attr(data-asin)').extract_first()
if (len(str(dataAsin)) < 5): continue
# 含有Amazon's Choice的商品
# B0748W31L5-amazons-choice
amazonsChoice = asinElement.xpath('//*[@id="' + dataAsin + '-amazons-choice"' + ']')
# 含有best-seller的商品
bestSeller = asinElement.xpath('//*[@id="' + dataAsin + '-best-seller"' + ']')
if (amazonsChoice):
ac = 1
else:
ac = 0
if (bestSeller):
bs = 1
else:
bs = 0
# 当前产品的信息
if (sponsoredElements):
goods_type = "A"
else:
goods_type = "N"
ratting = self.parseRatting(asinElement, country_code)
ratting_num = asinElement.css('span[class="a-size-base s-underline-text"]::text').extract_first()
price = self.parsePrice(asinElement, country_code)
pic = asinElement.css('img[class="s-image"]::attr(src)').extract_first()
title = self.parseTitle(asinElement, country_code)
uuid = asinElement.css('div::attr(data-uuid)').extract_first()
sale_num = asinElement.css(
'div[class="a-row a-size-base"] span[class="a-size-base a-color-secondary"]::text').extract_first()
coupon = asinElement.css(
'span[class="a-size-base s-highlighted-text-padding aok-inline-block s-coupon-highlight-color"]::text').extract_first()
if (coupon == None):
coupon = ""
if ("save" not in coupon.lower()):
coupon = ""
deal = ""
deal = asinElement.css('span[class="a-badge-label-inner a-text-ellipsis"] span::text').extract_first()
if (deal == None):
deal = ""
if ("deal" not in deal.lower()):
deal = ""
promotion = ""
prime = ""
secondary = asinElement.css('div[class="a-row a-size-base a-color-secondary"] span::text').extract_first()
if (secondary == None):
secondary = ""
if ("prime" in secondary.lower()):
prime = secondary.replace("join ", "").replace("to buy this item ", "")
if ("promotion" in secondary.lower()):
promotion = secondary
# print(Respons.url)
# print("ratting_num:",ratting_num)
asin_info = {}
asin_info["title"] = title #商品标记
asin_info["asin"] = dataAsin #商品asin
asin_info["price"] = price #价格
asin_info["ratting"] = ratting #打分
asin_info["ratting_num"] = parseNumber(ratting_num) #打分数
asin_info["goods_type"] = goods_type #广告还是自然排名
asin_info["img_url"] = pic #首图
asin_info["coupon"] = coupon #优惠券
asin_info["deal"] = deal #促销
asin_info["prime"] = prime #会员折扣
asin_info["promotion"] = promotion
asin_info["bs"] = bs
asin_info["ac"] = ac
asin_info["sales_num"] = sale_num #销量2024年更新
asin_info["uuid"] = uuid #页面唯一标识
if (sponsoredElements):
# 广告排名
adsRankCount = adsRankCount + 1
# 当前页广告数
if (dataAsin in asins):
# print(adsRankCount,"广告排名 in ****************")
# 记录广告排名与页码以及页码排名
Element['goods_type'] = "A"
Element['ads_page_rank'] = adsRankCount
Element['ads_page_no'] = pageNo
Element['ads_asin_info'] = json.dumps(asin_info)
if (BestadsElement == False):
BestadsElement = Element
else:
# 自然排名
natureRankCount = natureRankCount + 1
# 当前页自然排名
if (dataAsin in asins):
# print(adsRankCount, "自然排名 in****************")
Element['goods_type'] = "N"
Element['nature_page_rank'] = natureRankCount
Element['nature_page_no'] = pageNo
Element['nature_asin_info'] = json.dumps(asin_info)
if (BestnatureElement == False):
BestnatureElement = Element
key_asins.append(asin_info)
all_count=0
if (BestnatureElement != False):
Elements.append(BestnatureElement)
if (BestadsElement != False):
Elements.append(BestadsElement)
# 检查是否底部有广告
if (len(Elements) == 0):
Elements.append(adsItem)
Elements_new = []
for Element in Elements:
Element['search_num'] = all_count
Element['ads_page_num'] = adsRankCount
Element['nature_page_num'] = natureRankCount
Element["other_place"] = otherPlace
Elements_new.append(Element)
return Elements_new, key_asins, adsRankCount
入库效果
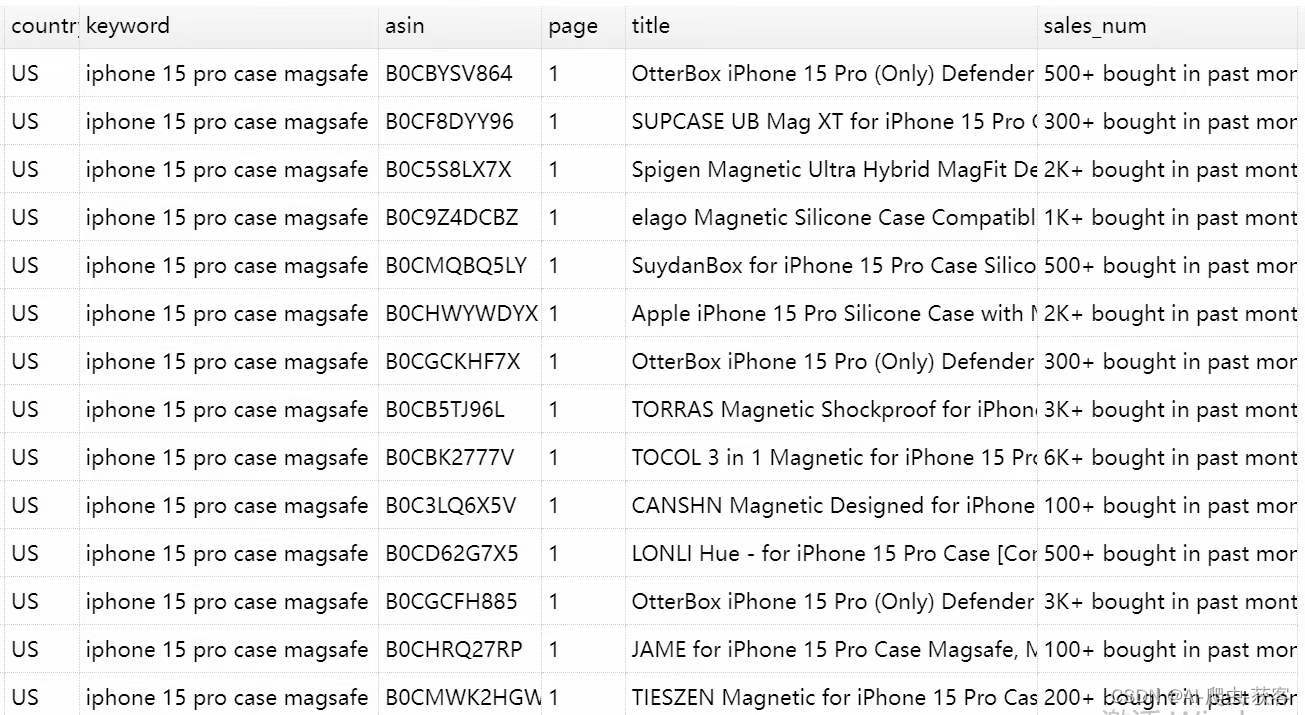
如果想知道亚马逊10万关键词扫描 1600万商品的数据
可以 联系作者















 5922
5922

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









