






实验准备:
- Google账号
- VPN
- 本文章
首先需要开启一个colab的notebook
然后开启tpu模式
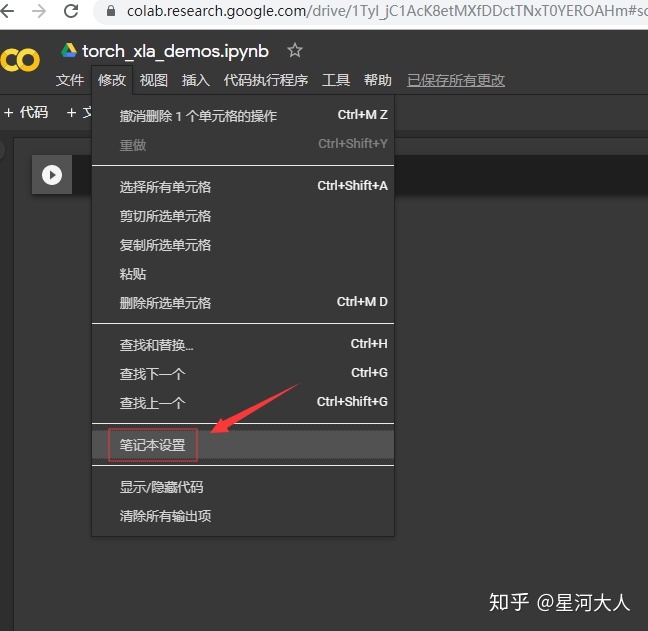
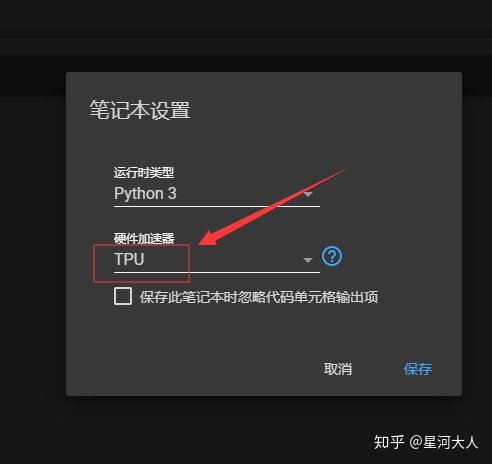
ok到目前为止一切正常,现在可以拉下来TF版本的soft模型,并且把use-tpu这个参数调成true。
不过这里我们不做尝试。
接下来安装pytorch
import 输出
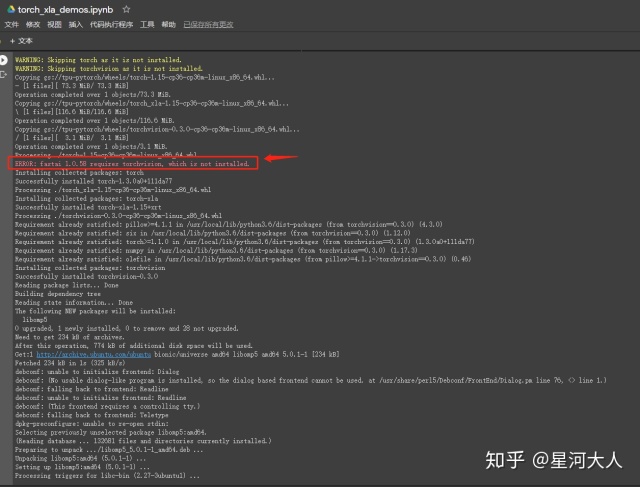
一切正常,这个版本的torch对fastai不友好
进行第一次测试
import torch
import torch_xla
import torch_xla.core.xla_model as xm
t = torch.randn(2, 2, device=xm.xla_device())
print(t.device)
print(t)
输出

相加测试
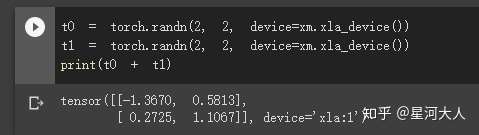
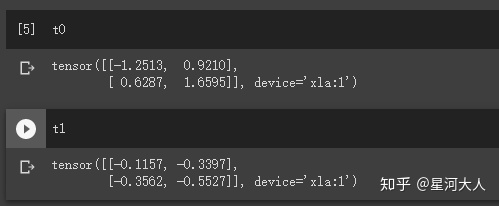
打印一下向量
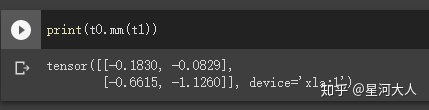
乘法测试
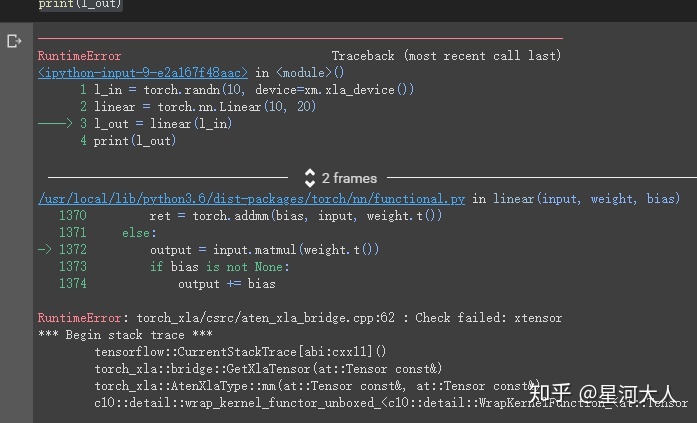
xla张量仅与同一设备上的其他xla张量兼容:实验代码
l_in = torch.randn(10, device=xm.xla_device())
linear = torch.nn.Linear(10, 20)
l_out = linear(l_in)
print(l_out)这里将会报错

正确的写法是
l_in = torch.randn(10, device=xm.xla_device())
linear = torch.nn.Linear(10, 20).to(xm.xla_device())
l_out = linear(l_in)
print(l_out)通过方法.to(xm.xla_device())将torch.FloatTensor转换成 xla tensor
接下来测试 MINIST
定义超参数
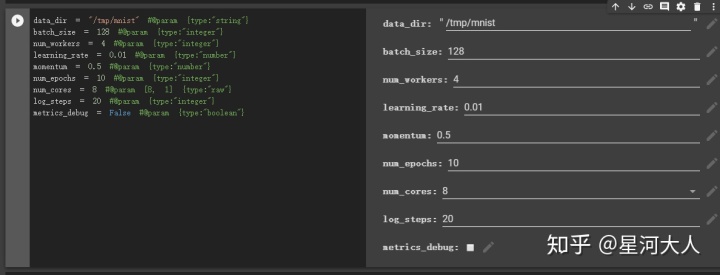
data_dir = "/tmp/mnist" #@param {type:"string"}
batch_size = 128 #@param {type:"integer"}
num_workers = 4 #@param {type:"integer"}
learning_rate = 0.01 #@param {type:"number"}
momentum = 0.5 #@param {type:"number"}
num_epochs = 10 #@param {type:"integer"}
num_cores = 8 #@param [8, 1] {type:"raw"}
log_steps = 20 #@param {type:"integer"}
metrics_debug = False #@param {type:"boolean"}这种写法会产生如下效果
定义模型
class MNIST(nn.Module):
def __init__(self):
super(MNIST, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.bn1 = nn.BatchNorm2d(10)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.bn2 = nn.BatchNorm2d(20)
self.fc1 = nn.Linear(320, 50)
self.fc2 = nn.Linear(50, 10)
def forward(self, x):
x = F.relu(F.max_pool2d(self.conv1(x), 2))
x = self.bn1(x)
x = F.relu(F.max_pool2d(self.conv2(x), 2))
x = self.bn2(x)
x = torch.flatten(x, 1)
x = F.relu(self.fc1(x))
x = self.fc2(x)
return F.log_softmax(x, dim=1)定义数据流
norm = transforms.Normalize((0.1307,), (0.3081,))
inv_norm = transforms.Normalize((-0.1307/0.3081,), (1/0.3081,))
train_dataset = datasets.MNIST(
data_dir,
train=True,
download=True,
transform=transforms.Compose(
[transforms.ToTensor(), norm]))
test_dataset = datasets.MNIST(
data_dir,
train=False,
transform=transforms.Compose(
[transforms.ToTensor(), norm]))
train_loader = torch.utils.data.DataLoader(
train_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=num_workers)
test_loader = torch.utils.data.DataLoader(
test_dataset,
batch_size=batch_size,
shuffle=False,
num_workers=num_workers)
devices = (
xm.get_xla_supported_devices(
max_devices=num_cores) if num_cores != 0 else [])
print("Devices: {}".format(devices))
# Scale learning rate to num cores
learning_rate = learning_rate * max(len(devices), 1)
# Pass [] as device_ids to run using the PyTorch/CPU engine.
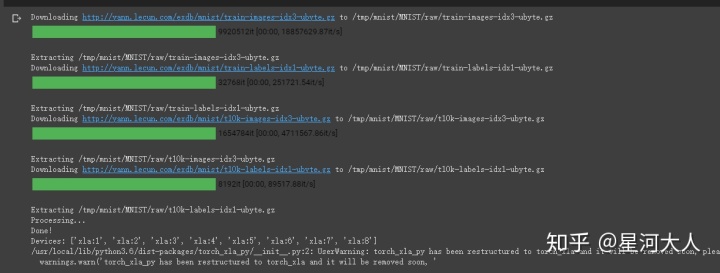
model_parallel = dp.DataParallel(MNIST, device_ids=devices)执行后会下载如下文件,斌且可以看到8个TPU已被打印出来
定义数据训练方法和测试方法
def train_loop_fn(model, loader, device, context):
loss_fn = nn.NLLLoss()
optimizer = context.getattr_or(
'optimizer',
lambda: optim.SGD(model.parameters(), lr=learning_rate,
momentum=momentum))
tracker = xm.RateTracker()
model.train()
for x, (data, target) in enumerate(loader):
optimizer.zero_grad()
output = model(data)
loss = loss_fn(output, target)
loss.backward()
xm.optimizer_step(optimizer)
tracker.add(batch_size)
if x % log_steps == 0:
print('[{}]({}) Loss={:.5f} Rate={:.2f} GlobalRate={:.2f} Time={}n'.format(
device, x, loss.item(), tracker.rate(),
tracker.global_rate(), time.asctime()), flush=True)
def test_loop_fn(model, loader, device, context):
total_samples = 0
correct = 0
model.eval()
data, pred, target = None, None, None
for x, (data, target) in enumerate(loader):
output = model(data)
pred = output.max(1, keepdim=True)[1]
correct += pred.eq(target.view_as(pred)).sum().item()
total_samples += data.size()[0]
accuracy = 100.0 * correct / total_samples
print('[{}] Accuracy={:.2f}%n'.format(device, accuracy))
return accuracy, data, pred, target——————————————————————————————
执行训练
data, target, pred = None, None, None
for epoch in range(1, num_epochs + 1):
model_parallel(train_loop_fn, train_loader)
results = model_parallel(test_loop_fn, test_loader)
results = np.array(results) # for ease of slicing
accuracies, data, pred, target =
[results[:,i] for i in range(results.shape[-1])]
accuracy = sum(accuracies) / len(accuracies)
print('[Epoch {}] Global accuracy: {:.2f}%'.format(epoch, accuracy))
if metrics_debug:
print(met.metrics_report())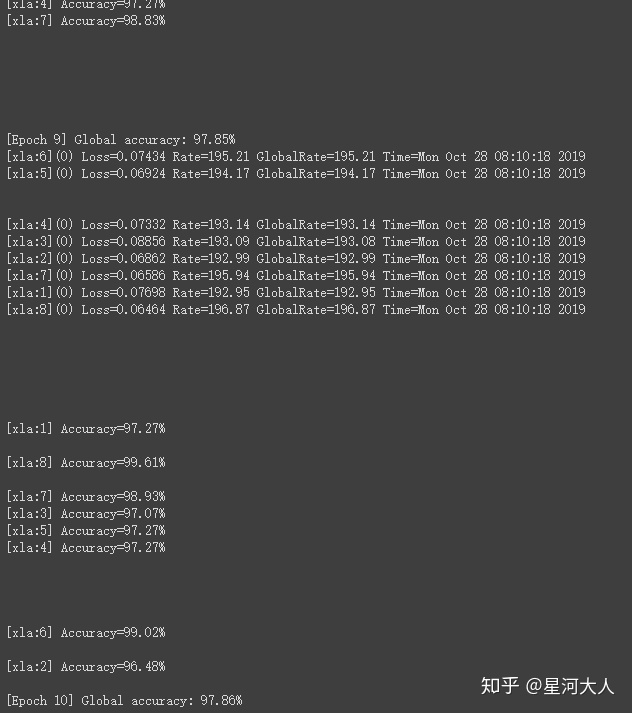
可以看到,每一个tpu(xla{n})都会执行一部分训练任务,并行进行,取得单节点的Acc然后汇总到一起取得Global Acc
展示一下效果
for i, ax in enumerate(fig.axes):
img, label, prediction = images[i], labels[i], preds[i]
img = inv_norm(img)
img = img.squeeze() # [1,Y,X] -> [Y,X]
ax.axis('off')
label, prediction = label.item(), prediction.item()
if label == prediction:
ax.set_title(u'u2713', color='blue', fontsize=22)
else:
ax.set_title(
'X {}/{}'.format(label, prediction), color='red')
ax.imshow(img)打勾代表预测准确

注意一点:在获取设备的代码中,我们使用的是多线程模式,除此以外还有多进程模式
devices = (
xm.get_xla_supported_devices(
max_devices=num_cores) if num_cores != 0 else [])这个函数的作用是:获取xla设备,并且管理在 num_cores 个线程里,这里num_cores 指的是线程数,至于进程的方案用这一段代码:
import torch_xla.core.xla_model as xm
import torch_xla.distributed.parallel_loader as pl
import torch_xla.distributed.xla_multiprocessing as xmp
def _mp_fn(index):
device = xm.xla_device()
para_loader = pl.ParallelLoader(train_loader, [device])
model = MNIST().train().to(device)
loss_fn = nn.NLLLoss()
optimizer = optim.SGD(model.parameters(), lr=lr, momentum=momentum)
for data, target in para_loader.per_device_loader(device):
optimizer.zero_grad()
output = model(data)
loss = loss_fn(output, target)
loss.backward()
xm.optimizer_step(optimizer)
if __name__ == '__main__':
xmp.spawn(_mp_fn, args=())实测不好用并且不好管理,建议放弃。使用线程方案。
================================================
接下来测试resnet50
定义超参数
data_dir = "/tmp/cifar" #@param {type:"string"}
batch_size = 128 #@param {type:"integer"}
num_workers = 4 #@param {type:"integer"}
learning_rate = 0.1 #@param {type:"number"}
momentum = 0.9 #@param {type:"number"}
num_epochs = 20 #@param {type:"integer"}
num_cores = 8 #@param [8, 1] {type:"raw"}
log_steps = 20 #@param {type:"integer"}
metrics_debug = False #@param {type:"boolean"}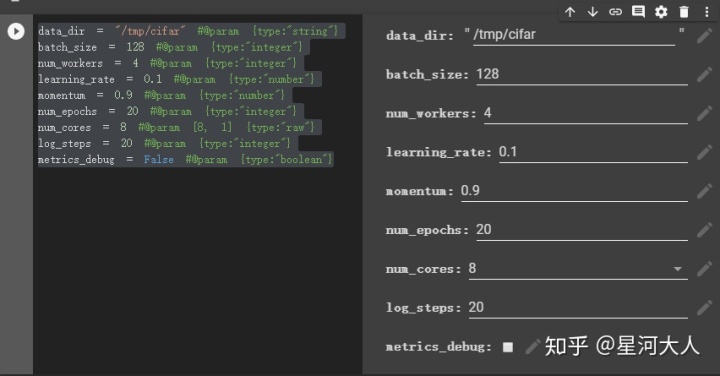
定义网络
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, in_planes, planes, stride=1):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(
in_planes, planes, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(
planes, planes, kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.shortcut = nn.Sequential()
if stride != 1 or in_planes != self.expansion * planes:
self.shortcut = nn.Sequential(
nn.Conv2d(
in_planes,
self.expansion * planes,
kernel_size=1,
stride=stride,
bias=False), nn.BatchNorm2d(self.expansion * planes))
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
out += self.shortcut(x)
out = F.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, block, num_blocks, num_classes=10):
super(ResNet, self).__init__()
self.in_planes = 64
self.conv1 = nn.Conv2d(
3, 64, kernel_size=3, stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.layer1 = self._make_layer(block, 64, num_blocks[0], stride=1)
self.layer2 = self._make_layer(block, 128, num_blocks[1], stride=2)
self.layer3 = self._make_layer(block, 256, num_blocks[2], stride=2)
self.layer4 = self._make_layer(block, 512, num_blocks[3], stride=2)
self.linear = nn.Linear(512 * block.expansion, num_classes)
def _make_layer(self, block, planes, num_blocks, stride):
strides = [stride] + [1] * (num_blocks - 1)
layers = []
for stride in strides:
layers.append(block(self.in_planes, planes, stride))
self.in_planes = planes * block.expansion
return nn.Sequential(*layers)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
out = F.avg_pool2d(out, 4)
out = torch.flatten(out, 1)
out = self.linear(out)
return F.log_softmax(out, dim=1)
def ResNet18():
return ResNet(BasicBlock, [2, 2, 2, 2])
定义数据流
norm = transforms.Normalize(
mean=(0.4914, 0.4822, 0.4465), std=(0.2023, 0.1994, 0.2010))
inv_norm = transforms.Normalize(
mean=(-0.4914/0.2023, -0.4822/0.1994, -0.4465/0.2010),
std=(1/0.2023, 1/0.1994, 1/0.2010)) # For visualizations
transform_train = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
norm,
])
transform_test = transforms.Compose([
transforms.ToTensor(),
norm,
])
train_dataset = datasets.CIFAR10(
root=data_dir,
train=True,
download=True,
transform=transform_train)
test_dataset = datasets.CIFAR10(
root=data_dir,
train=False,
download=True,
transform=transform_test)
train_loader = torch.utils.data.DataLoader(
train_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=num_workers)
test_loader = torch.utils.data.DataLoader(
test_dataset,
batch_size=batch_size,
shuffle=False,
num_workers=num_workers)
devices = (
xm.get_xla_supported_devices(
max_devices=num_cores) if num_cores != 0 else [])
print("Devices: {}".format(devices))
# Scale learning rate to num cores
learning_rate = learning_rate * max(len(devices), 1)
# Pass [] as device_ids to run using the PyTorch/CPU engine.
model_parallel = dp.DataParallel(ResNet18, device_ids=devices)
执行训练
data, target, pred = None, None, None
for epoch in range(1, num_epochs + 1):
model_parallel(train_loop_fn, train_loader)
results = model_parallel(test_loop_fn, test_loader)
results = np.array(results) # for ease of slicing
accuracies, data, pred, target =
[results[:,i] for i in range(results.shape[-1])]
accuracy = sum(accuracies) / len(accuracies)
print('Global accuracy: {:.2f}%'.format(accuracy))
if metrics_debug:
print(met.metrics_report())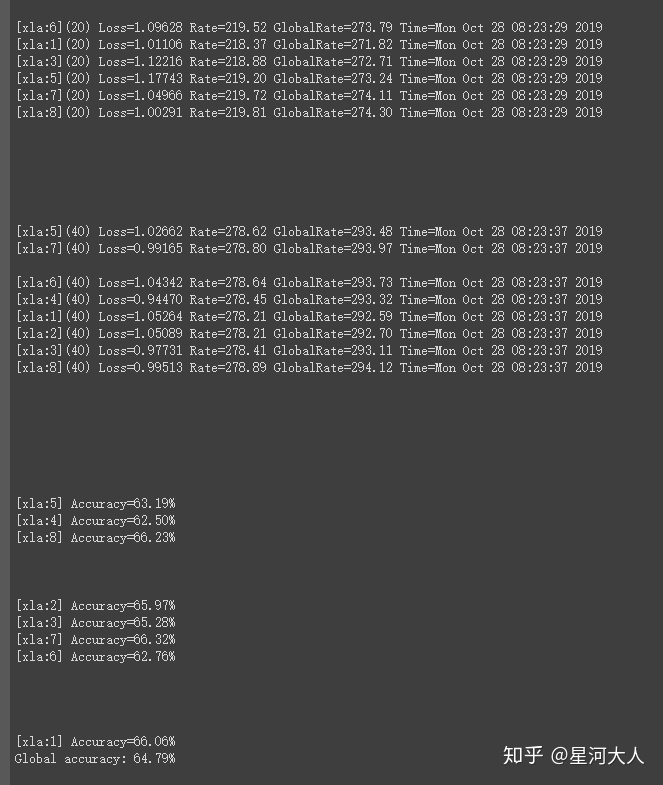
为了效率,这里使用的epoch是20,但是模型属于欠拟合状态
展示一下预测结果
%matplotlib inline
from matplotlib import pyplot as plt
CIFAR10_LABELS = ['airplane', 'automobile', 'bird', 'cat', 'deer',
'dog', 'frog', 'horse', 'ship', 'truck']
# Retrive tensors that is on TPU cores
M = 4
N = 6
images, labels, preds = data[0][:M*N].cpu(),
target[0][:M*N].cpu(), pred[0][:M*N].cpu()
fig, ax = plt.subplots(M, N, figsize=(16, 9))
plt.suptitle('Correct / Predicted Labels (Red text for incorrect ones)')
for i, ax in enumerate(fig.axes):
img, label, prediction = images[i], labels[i], preds[i]
img = inv_norm(img)
img = img.permute(1, 2, 0) # (C, M, N) -> (M, N, C)
ax.axis('off')
label, prediction = label.item(), prediction.item()
if label == prediction:
ax.set_title(u'u2713', color='blue', fontsize=22)
else:
ax.set_title(
'X {}/{}'.format(CIFAR10_LABELS[label],
CIFAR10_LABELS[prediction]), color='red')
ax.imshow(img)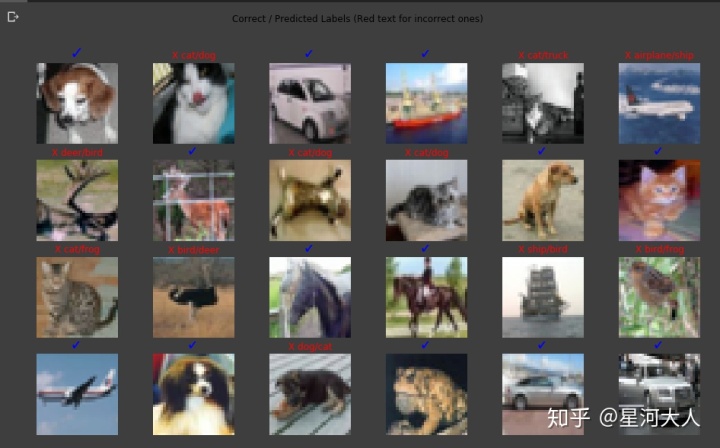
错的很多
================================================
接下来测试推理效果:
加载一张 corgi 图片
%matplotlib inline
# From OpenImages V5 Dataset
!wget -O corgi.jpg
https://farm4.staticflickr.com/1301/4694470234_6f27a4f602_o.jpg
from PIL import Image
from matplotlib import pyplot as plt
img = Image.open('corgi.jpg');
plt.imshow(img);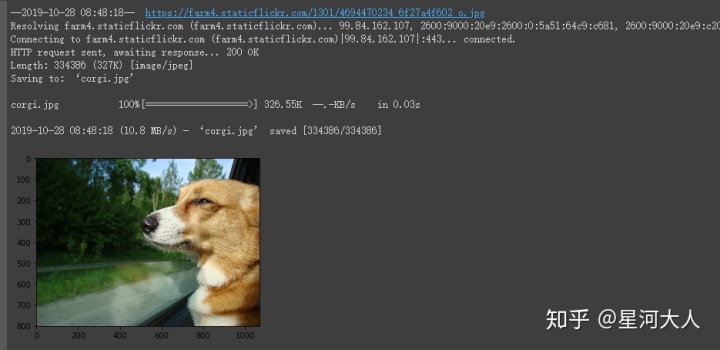
import torch
import torch_xla.core.xla_model as xm
model = torch.hub.load('pytorch/vision', 'densenet121', pretrained=True)
model.eval()
# Move the model weights onto the TPU device.
# Using 1 out of 8 cores available (to use 8 use DataParallel API)
DEVICE = xm.xla_device()
model = model.to(DEVICE)
model
import torch
import torch_xla.core.xla_model as xm
这里测试两个模型,分别是resnet50 和 densenet121
densenet121
model = torch.hub.load('pytorch/vision', 'densenet121', pretrained=True)
model.eval()
# Move the model weights onto the TPU device.
# Using 1 out of 8 cores available (to use 8 use DataParallel API)
DEVICE = xm.xla_device()
model = model.to(DEVICE)打印一下model:
Using cache found in /root/.cache/torch/hub/pytorch_vision_master
DenseNet(
(features): Sequential(
(conv0): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(norm0): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu0): ReLU(inplace=True)
(pool0): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(denseblock1): _DenseBlock(
(layers): ModuleDict(
(denselayer1): _DenseLayer(
(norm1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(64, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
......................
太长所以省略了
预处理图片,主要是调整尺寸,归一化像素
from torchvision import transforms
norm = transforms.Normalize(
mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
inv_norm = transforms.Normalize(
mean=[-0.485/0.229, -0.456/0.224, -0.406/0.225],
std=[1/0.229, 1/0.224, 1/0.225])
preprocess = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
norm,
])
image_tensor = preprocess(img)
input_tensor = image_tensor.unsqueeze(0) # single-image batch as wanted by model
input_tensor = input_tensor.to(DEVICE) # send tensor to TPU
# Display resized and cropped image
fig, ax = plt.subplots(1, 2, figsize=(8, 4));
mnc_tensor = image_tensor.permute(1, 2, 0); # (C, M, N) -> (M, N, C)
展示一下
ax[0].imshow(mnc_tensor);
ax[0].axis('off');
ax[0].set_title('preprocessed image');
inv_norm_tensor = inv_norm(image_tensor).permute(1, 2, 0);
ax[1].imshow(inv_norm_tensor);
ax[1].axis('off');
ax[1].set_title('inv_norm(preprocessed image)');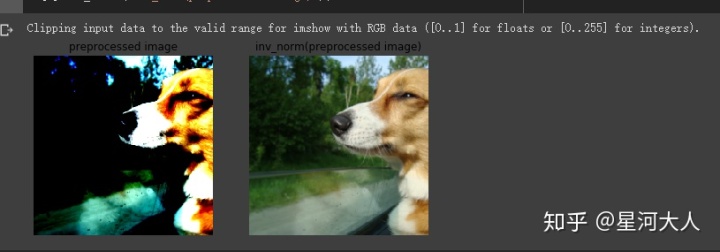
加载字典表 IMAGENET_LABELS (字典表与与训练的模型兼容)
IMAGENET_LABELS = {0: 'tench, Tinca tinca',
1: 'goldfish, Carassius auratus',
2: 'great white shark, white shark, man-eater, man-eating shark, Carcharodon carcharias',
..................
262: 'Brabancon griffon',
263: 'Pembroke, Pembroke Welsh corgi',
264: 'Cardigan, Cardigan Welsh corgi',
265: 'toy poodle',
..................
998: 'ear, spike, capitulum',
999: 'toilet tissue, toilet paper, bathroom tissue'}测试输出
outputs = model(input_tensor)
print('outputs.device == {}'.format(outputs.device))
prediction = outputs.max(dim=1).indices.item()
print('Densenet121 prediction: {}'.format(IMAGENET_LABELS[prediction]))
测试一下batchsize = 32 的速度
import numpy as np
import time
import torch_xla.distributed.data_parallel as dp
batch_size = 32
input_batch_tensor = input_tensor.repeat(batch_size, 1, 1, 1)
times = []
for i in range(256):
start_time = time.time()
output_batch_tensor = model(input_batch_tensor)
xm.mark_step()
times.append((time.time() - start_time) * 1000)
print('Inference times: p50={:.2f}ms p90={:.2f}ms p95={:.2f}ms'.format(
np.percentile(times, 50), np.percentile(times, 90),
np.percentile(times, 95)))
中位数116.9毫秒,90分位数 118.48毫秒,95分位数119.04毫秒
resnet50
dog测试
model = torch.hub.load('pytorch/vision', 'densenet121', pretrained=True)
model.eval()
# Move the model weights onto the TPU device.
# Using 1 out of 8 cores available (to use 8 use DataParallel API)
DEVICE = xm.xla_device()
model = model.to(DEVICE)
outputs = model(input_tensor)
print('outputs.device == {}'.format(outputs.device))
prediction = outputs.max(dim=1).indices.item()
print('Densenet121 prediction: {}'.format(IMAGENET_LABELS[prediction]))
batchsize = 32

tpu到底比gpu强在哪里?
已经有官方基于resnet50 的测试结果:
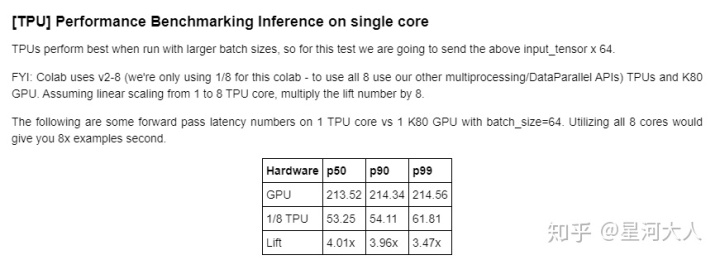
看一下向量文件的保存与读取:
import torch
import torch_xla
import torch_xla.core.xla_model as xm
device = xm.xla_device()
t0 = torch.randn(2, 2, device=device)
t1 = torch.randn(2, 2, device=device)
tensors = (t0.cpu(), t1.cpu())
torch.save(tensors, 'tensors.pt')
tensors = torch.load('tensors.pt')
t0 = tensors[0].to(device)
t1 = tensors[1].to(device)以及向量文件
最后值得说一下的是直到2019年10月底,pytorch 支持的xla设备不包括GPU,只有CPU和TPU
import torch_xla.core.xla_model as xm
测试cpu
xm.get_xla_supported_devices(devkind=["CPU"])输出
['xla:0']
测试gpu
xm.get_xla_supported_devices(devkind=["GPU"])无输出
测试tpu
xm.get_xla_supported_devices(devkind=["TPU"])输出















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









