






redis是日常开发中最常的非关系型数据库,可以说只要是个项目基本都会使用到。常用来做数据缓存、分布式锁等等。redis的基本安装内容就不说了(在之前的博客搭建系列里面有提到redis的安装使用,如果不会的可以看一下),后面更新会说一下其配置文件中主要的配置信息。
redis常用的数据类型str、hash、list、set、zset,但是最常用的应该就是前三种,这篇文章里面就是用来记录和说明这前三种数据类型常使用的命令。虽然在实际开发过程中很少使用这些命令,但是了解这些命令,会更有利于对redis相关API的理解和使用。
redis为什么快
redis为什么速度这么快,这是面试常见的面试题,更是项目中使用它的原因。
- redis是使用C语言编写,更接近底层的编程语言
- redis是基于内存存储数据,获取和存储数据都是在内存中
- redis是单线程处理,没有锁的竞争,减少了性能消耗,虽然是单线程,处理速度上并不慢,因为其是基于内存做处理,没有和磁盘间繁琐的读写IO过程(具体redis单线程原理,后期会再更新博客详细说明)
redis数据类型之str
字符串类型是最常用的,可能很多简单小型项目用来缓存数据都只会用到这一种数据类型。
常用命令
- set key value [ex seconds] [px milliseconds] [nx|xx]:存储数据,key是键唯一,值是字符串类型,用来存储真正的数据信息,ex和px表示设置其有效时间,对应的单位分别是秒和毫秒,nx和xx表示存储数据是否可以被覆盖,如果key已经存在,返回为0,表示没有设置成功,如果key不存在返回为1,表示设置成功,xx是set命令默认的存储方式,可覆盖
### 直接存储数据set name joker### 加上有效时间为10秒set name joker ex 10### 加上有效时间为10000毫秒set name joker px 10000### 不可覆盖+有效时间set name itcrud ex 10 nx- 这里需要注意,当使用nx或者xx的时候,前面需要有有效时间,如果只需要使用nx,不需要设置有效时间也是可以的,但是命令是不同,看下面setnx命令。
- get key:根据key获取value值
get name- mset keys values:批量存储键值数据,如果客户端同时有大量数据执行存储,每条数据都连接一次redis,会增大连接过程的资源消耗,效率上也会大打折扣,这时便可以使用批量存储方式
## 同时设置三条数据,key分别是:name、age、blog,值分别是:joker、30、blog.itcrud.commset name joker age 30 blog blog.itcurd.com- mget keys:输入批量键,获取批量的值,多个key用空格隔开即可
mget name age blog- incr key:key对应value值自增1操作,比如投票的时候常用,value必须为整数才可以
incr age- incrby key increment:key对应的value值增长increment指定的值,value同样要为整数
incrby age 3- decr key:key对应value值减1的操作,value必须为整数
decr age- decrby key decrement:key对应value值减decrement指定的值,value必须为整数
decrby age 1- incrbyfloat key increment:key对应的value值增加increment指定的值,value可以为整数或者浮点数都可以
incrbyfloat score 1.1- setnx key value:不可覆盖的设置值,当key已经存在,setnx返回为0,表示没有设置成功,如果key不存在返回为1,表示设置成功
setnx name joker- strlen key:获取key对应的value值长度
strlen name- getrange key start end:截取字符串,包含start和end
## 获取的字符串为"it"set name itcrudgetrange name 0 1redis数据类型之hash
hash结构的如图所示:
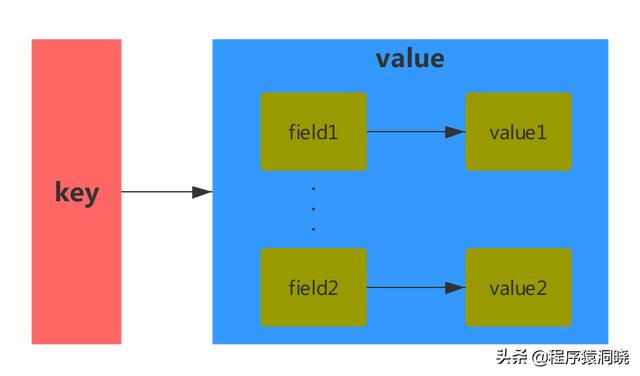
hash类型很适合存储一些对象信息。把field变为字段名,把字段值变为filed对应的value值,其中数据的唯一标识放在key上面。
常用命令
- hset key field value:设置值
hset user:1 name joker- hmset key fields values:批量设置值
hmset user:1 name joker age 30 blog blog.itcrud.com- hget kye field:获取单个值
hget user:1 name- hmget key fileds:批量获取值
hget user:1 name age blog- hgetall key:获取key下的所有键值对
hgetall user:1- hdel key fields:删除key下的某个键值对,支持批量删除,指定多个field即可
hdel user:1 name age- hlen key:获取当前key下键值对的数量
hlen user:1- hexists key field:查询key下,指定的field是否存在,
hexists user:1 name- hkeys key:获取key下所有的filed列表
hkeys user:1- hvals key:获取key下的所有value列表
hvals user:1- hincrby key field increment:对key的field对应value值做增加的操作,增加的值为increment指定的值,只支持整数
hincrby user:1 age 2- hincrbyfloat key field increment:对key的field对应value值做增加的操作,增加的值为increment指定的值,可以是整数或者浮点数
hincrbyfloat user1 score 1.1redis数据类型之list
list最常见的是被用为队列,一个key下面可以存储一个有序的字符串队列,单个队列可以存储2的32次方减1个元素。基本的数据结构图如下:
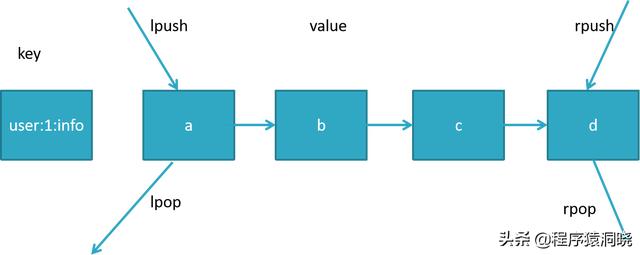
常用命令
- rpush key values:从右侧推入元素,可以同时推入多个
## 从右侧依次推入a、b、c三个元素rpush itcrud a b c- lpush key values:从左侧推入元素,可以同时推入多个
## 从左侧依次推入a、b、c三个元素lpush itcrud a b c- lrange key start end:根据index获取指定范围内的元素,包含start和end的元素
## 获取全量元素,0表示左侧开始的第一个元素,-1表示从右侧开始的第一个元素lrange itcrud 0 -1- linsert key before|after pivot value:在指定元素的前面或者后面插入元素
## 在b的前面插入新元素mlinsert itcrud before b m- lindex key index:获取指定index位置的元素
lindex itcrud -2- llen key:获取列表的长度
llen itcrud- lpop key:从左侧弹出元素
lpop itcrud- rpop key:从右侧弹出元素
rpop itcrud说明:关于list的index还是需要说一下,当index计数是从左到右,就是从0开始。但是index计数是从右到左,就是从-1开始。如下图:
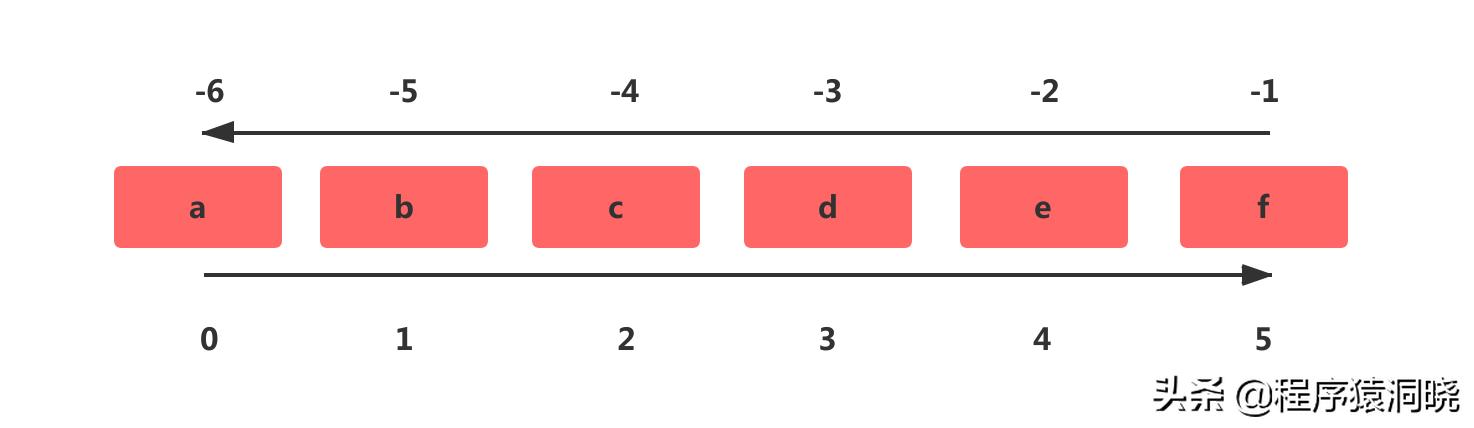
总结
三种数据类型都已经说完了,但是这里还需要补充一个内容,是平时我们项目中使用redis的习惯,以及其他主要的使用习惯的对比。
三种方案实现用户信息存储
- 直接用字符串的方式存储(分散存储),存储方式如下:
set user:1:name jokerset user:1:age 30set user:1:gender male- 这种存储的缺点是键的冗余太多,我们都知道redis是存储在内存里面,内存空间是很珍贵的,这个存储太浪费啦,另外这样存储过于分散,不利于使用。缺点和优点都是相对的,这样存储更为直观。但是实际上这个优点并没有什么用。
- 将对象序列化成字符串,存储方式如下:
## 将user序列化成json字符串:jsonUserset user:1 jsonUser- 优点:编程简单,序列化合理,内存使用率高
- 缺点:序列化的反序列化过程以及客户端和服务端建立连接有一定的开销。如果只是修改用户中的一个字段,都需要经历查询、反序列化、修改值、序列化、再set设置值。
- 使用hash数据类型
hmset user:1 name joker age 30 gender male- 优点:简单直观,相对于序列化内存消耗会高一点,每次修改只需要建立一次连接,操作简便
- 缺点:要控制ziplist与hashtable两种编码转换,且hashtable会消耗更多的内存
- 三种方式各有优缺点,可以对比使用,没有绝对的优势,也没有绝对的劣势,看实际项目的需求,我们项目里使用的第二种方式,序列化对象,因为json转换对象很方便。如果是采用第三种,在数据和对象的转换过程会更为复杂。















 1737
1737











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









