





今天有个同学问我能否快速地爬取网页上所有表格内容?
我说当然可以呀。
然后就扔过来一个链接
http://svc.stcsm.gov.cn/public/award
我就打开该网页,看看是啥样的表格。
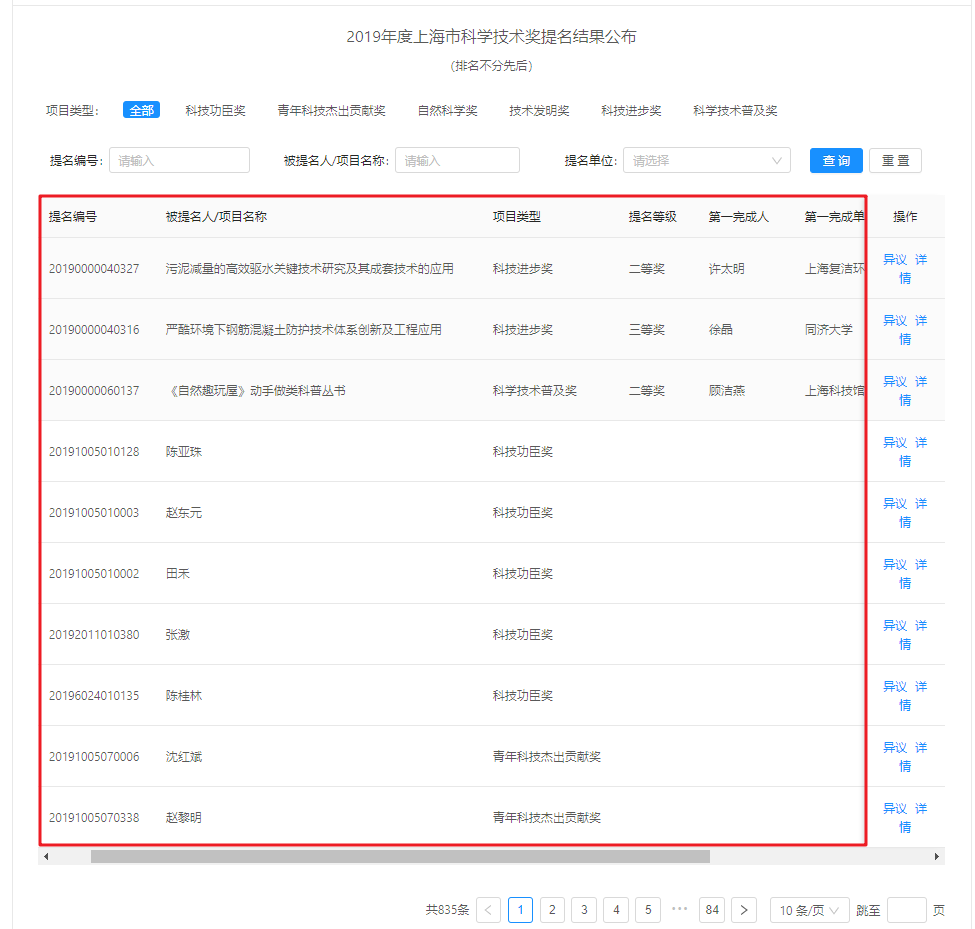
我首先想到python第三方库BeautifulSoup有个函数可以直接提取网页所有表格内容,决定直接用这个尝试一波。
在网上搜一下这个函数的使用方法
from bs4 import BeautifulSoup #引入BeautifulSoup第三方库import requests #引入requests库import pandas as pd #引入数据处理oandas库url = 'https://segmentfault.com/a/1190000007688656'res = requests.get(url)soup = BeautifulSoup(res.text, 'lxml')tables = soup.select('table')df_list = []for table in tables: df_list.append(pd.concat(pd.read_html(table.prettify())))df = pd.concat(df_list)print(df)将网址替换我们要爬取的网页,看看能不能把所要内容爬下来
from bs4 import BeautifulSoup #引入BeautifulSoup第三方库import requests #引入requests库import pandas as pd #引入数据处理oandas库url = 'http://svc.stcsm.gov.cn/public/award'res = requests.get(url)soup = BeautifulSoup(res.text, 'lxml')tables = soup.select('table')df_list = []for table in tables: df_list.append(pd.concat(pd.read_html(table.prettify())))df = pd.concat(df_list)print(df)一试就行,不错不错,还以pandas表格形式储存
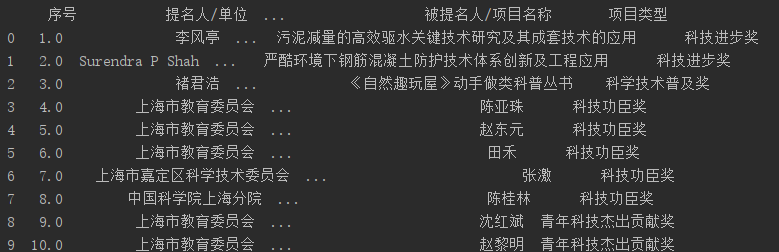
接着,我就想加个循环把所有页表格内容都爬下来
当我点击下一页时发现网址并没有改变
我就知道自己犯了个大错
应该先判断表格内容是通过动态加载(Ajax)还是静态加载的。
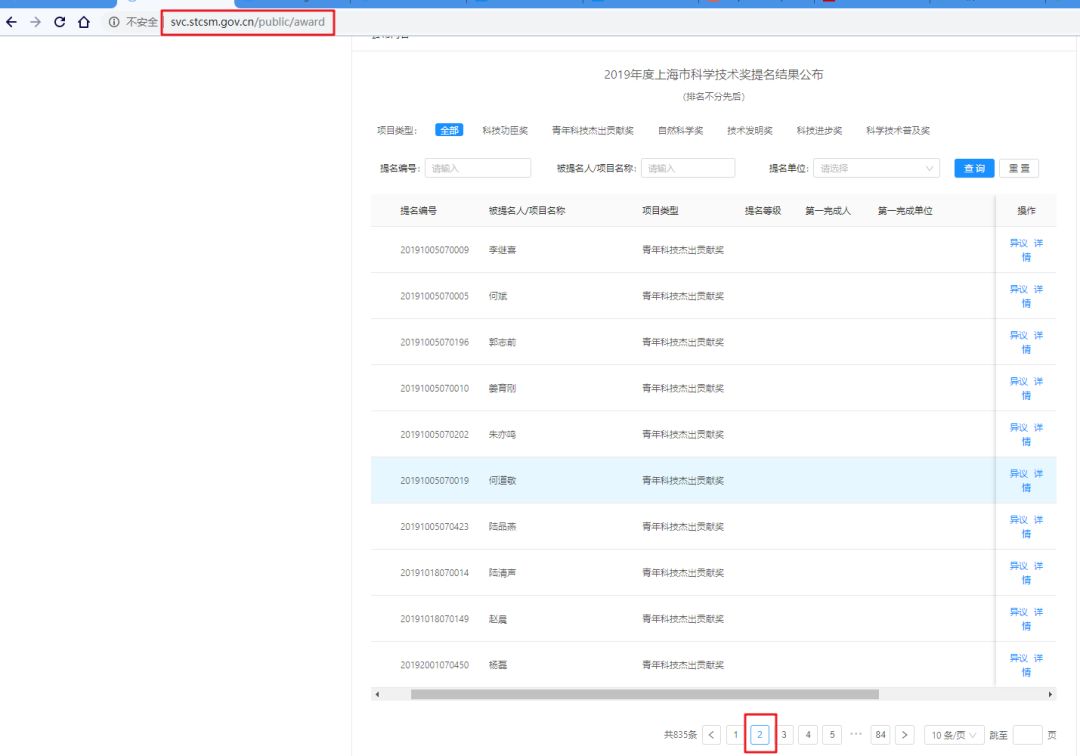
当表格下页数变为2时,网址未发生改变。
接下来就按照Ajax方式爬取表格内容。
第一步,利用谷歌浏览器开发者工具获取动态加载的真实网址及post数据
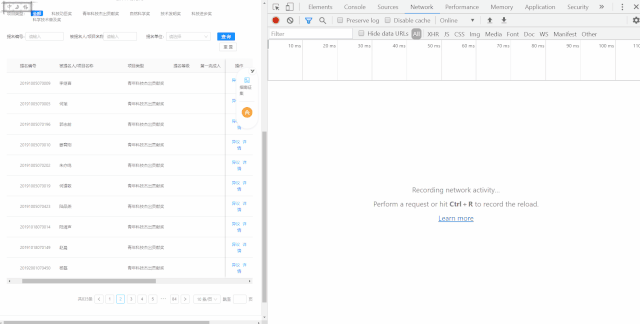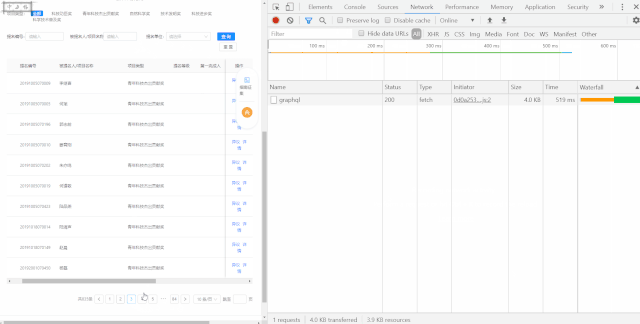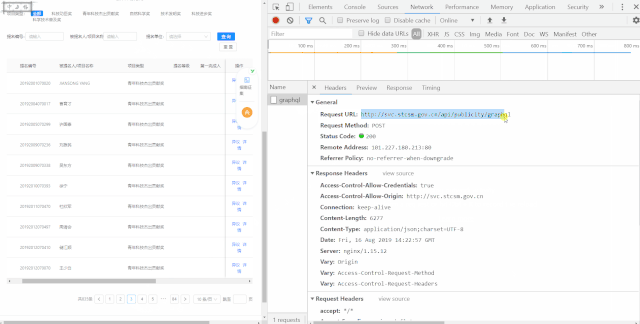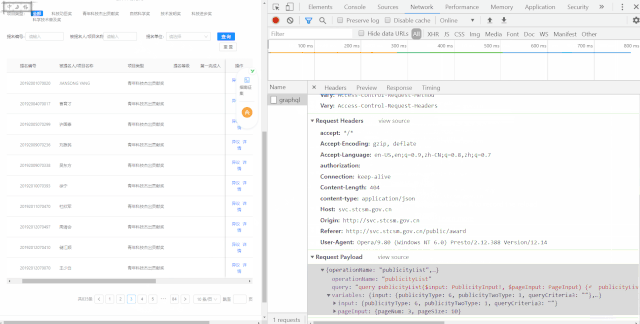
获得真实api网址:
http://svc.stcsm.gov.cn/api/publicity/graphql请求header:
accept: */*Accept-Encoding: gzip, deflateAccept-Language: en-US,en;q=0.9,zh-CN;q=0.8,zh;q=0.7authorization: Connection: keep-aliveContent-Length: 404content-type: application/jsonHost: svc.stcsm.gov.cnOrigin: http://svc.stcsm.gov.cnReferer: http://svc.stcsm.gov.cn/public/awardUser-Agent: Opera/9.80 (Windows NT 6.0) Presto/2.12.388 Version/12.14POST数据:
data = { "operationName": "publicityList", "variables": {"input": {"publicityType": 6, "publicityTwoType": 1, "queryCriteria3": ""}, "pageInput": {"pageNum": i, "pageSize": 10}}, "query": "query publicityList($input: PublicityInput!, $pageInput: PageInput) {\n publicityList(input: $input, pageInput: $pageInput) {\n total\n list {\n id\n publicityContentStr\n __typename\n }\n __typename\n }\n}\n" }第二步,尝试用requests库POST一次
url = 'http://svc.stcsm.gov.cn/api/publicity/graphql'headers = { 'Host': 'svc.stcsm.gov.cn', 'Connection': 'keep-alive', 'Content-Length': '404', 'accept': '*/*', 'authorization':'', 'User-Agent': 'Opera/9.80 (Windows NT 6.0) Presto/2.12.388 Version/12.14', 'content-type': 'application/json', 'Origin': 'http://svc.stcsm.gov.cn', 'Referer': 'http://svc.stcsm.gov.cn/public/award', 'Accept-Encoding': 'gzip, deflate', 'Accept-Language': 'en-US,en;q=0.9,zh-CN;q=0.8,zh;q=0.7',}data = { "publicityType": 6, "publicityTwoType": 1, "queryCriteria3": "", "pageNum": 2, "pageSize": 10, }res = requests.post(url, data=data, headers=headers)print(res)运行上述代码后发现,发现请求错误!!!!
再次查看谷歌浏览器开发者页面里请求头相关数据,发现post里data数据与平常的不一样

在查看headers相关信息,发现post上传的是json数据,不是以form表单形式提交数据。
赶紧网上搜索如何通过json数据使用post,看到这个例子,赶紧学习一下
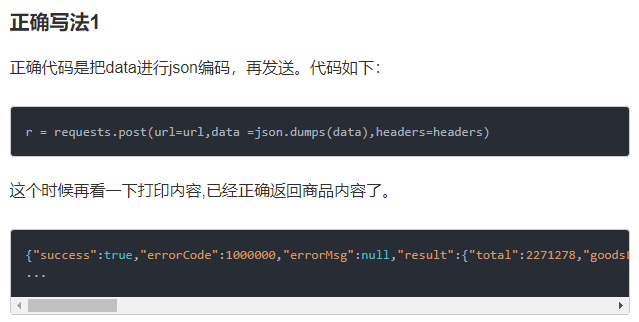
在上传json数据时,要通过json库进行编码,请求代码构造如下
res = requests.post(url, data=json.dumps(data), headers=headers)整个获取单页表格内容代码如下:
import requestsimport jsonimport csvurl = 'http://svc.stcsm.gov.cn/api/publicity/graphql'headers = { 'Host': 'svc.stcsm.gov.cn', 'Connection': 'keep-alive', 'Content-Length': '404', 'accept': '*/*', 'authorization':'', 'User-Agent': 'Opera/9.80 (Windows NT 6.0) Presto/2.12.388 Version/12.14', 'content-type': 'application/json', 'Origin': 'http://svc.stcsm.gov.cn', 'Referer': 'http://svc.stcsm.gov.cn/public/award', 'Accept-Encoding': 'gzip, deflate', 'Accept-Language': 'en-US,en;q=0.9,zh-CN;q=0.8,zh;q=0.7',}data = { "operationName": "publicityList", "variables": {"input": {"publicityType": 6, "publicityTwoType": 1, "queryCriteria3": ""}, "pageInput": {"pageNum": 2, "pageSize": 10}}, "query": "query publicityList($input: PublicityInput!, $pageInput: PageInput) {\n publicityList(input: $input, pageInput: $pageInput) {\n total\n list {\n id\n publicityContentStr\n __typename\n }\n __typename\n }\n}\n" }res = requests.post(url, data=json.dumps(data), headers=headers)print(res.text)得到如下结果:
C:\Users\sgq11\AppData\Local\Continuum\anaconda3\envs\pytorch\python.exe D:/Codes/Python/get_table.py{"data":{"publicityList":{"total":835,"list":[{"id":"5d50ca775c6ea9000174e7f6","publicityContentStr":"{\"contentId\":\"eff7556a3af540e88a3c02c979667416\",\"declarationNo\":\"20190000040327\",\"categoryName\":\"科技进步奖\",\"achieveUserName\":\"许太明\",\"categoryType\":\"2\",\"proposeUnitId\":\"\",\"proposeUserName\":\"李风亭\",\"declarationName\":\"污泥减量的高效驱水关键技术研究及其成套技术的应用\",\"declarationProposeType\":0,\"achieveUnitName\":\"上海复洁环保科技股份有限公司\",\"proposeUnitName\":\"\",\"publicityType\":\"1\",\"nomineeUnitName\":\"\",\"declarationLevel\":\"二等奖\",\"categoryId\":\"fc68f0929a614b66a71d35fc1ff8aae2\"}","__typename":"PublicityVo"},{"id":"5d50ca775c6ea9000174e7f7","publicityContentStr":"{\"contentId\":\"f0bc3069c6fc420e9b69a69f1a20502f\",\"declarationNo\":\"20190000040316\",\"categoryName\":\"科技进步奖\",\"achieveUserName\":\"徐晶\",\"categoryType\":\"2\",\"proposeUnitId\":\"\",\"proposeUserName\":\"Surendra P Shah\",\"declarationName\":\"严酷环境下钢筋混凝土防护技术体系创新及工程应用\",\"declarationProposeType\":0,\"achieveUnitName\":\"同济大学\",\"proposeUnitName\":\"\",\"publicityType\":\"1\",\"nomineeUnitName\":\"\",\"declarationLevel\":\"三等奖\",\"categoryId\":\"fc68f0929a614b66a71d35fc1ff8aae2\"}","__typename":"PublicityVo"},{"id":"5d50ca775c6ea9000174e7f8","publicityContentStr":"{\"contentId\":\"fc60ef4042424d7fb7e8f508e9ec1178\",\"declarationNo\":\"20190000060137\",\"categoryName\":\"科学技术普及奖\",\"achieveUserName\":\"顾洁燕\",\"categoryType\":\"2\",\"proposeUnitId\":\"\",\"proposeUserName\":\"褚君浩\",\"declarationName\":\"《自然趣玩屋》动手做类科普丛书\",\"declarationProposeType\":0,\"achieveUnitName\":\"上海科技馆\",\"proposeUnitName\":\"\",\"publicityType\":\"1\",\"nomineeUnitName\":\"\",\"declarationLevel\":\"二等奖\",\"categoryId\":\"967131166a3c4728b6e90d7deedde679\"}","__typename":"PublicityVo"},{"id":"5d50ca775c6ea9000174e7f9","publicityContentStr":"{\"contentId\":\"d311b45ec0ce46249ac1d564c4b2f904\",\"declarationNo\":\"20191005010128\",\"categoryName\":\"科技功臣奖\",\"categoryType\":\"1\",\"proposeUnitId\":\"f1e34adb178a4141b1c9799d112e1c17\",\"proposeUserName\":\"\",\"declarationName\":\"陈亚珠\",\"declarationProposeType\":1,\"proposeUnitName\":\"上海市教育委员会\",\"publicityType\":\"1\",\"nomineeUnitName\":\"上海交通大学\",\"declarationLevel\":\"\",\"categoryId\":\"88f1678c136b480ebe811b82f111924f\"}","__typename":"PublicityVo"},{"id":"5d50ca775c6ea9000174e7fa","publicityContentStr":"{\"contentId\":\"39c33964d8b24366979df0fee0a563fd\",\"declarationNo\":\"20191005010003\",\"categoryName\":\"科技功臣奖\",\"categoryType\":\"1\",\"proposeUnitId\":\"f1e34adb178a4141b1c9799d112e1c17\",\"proposeUserName\":\"\",\"declarationName\":\"赵东元\",\"declarationProposeType\":1,\"proposeUnitName\":\"上海市教育委员会\",\"publicityType\":\"1\",\"nomineeUnitName\":\"复旦大学\",\"declarationLevel\":\"\",\"categoryId\":\"88f1678c136b480ebe811b82f111924f\"}","__typename":"PublicityVo"},{"id":"5d50ca775c6ea9000174e7fb","publicityContentStr":"{\"contentId\":\"2584dd28b4fd4cca911cfac564878d58\",\"declarationNo\":\"20191005010002\",\"categoryName\":\"科技功臣奖\",\"categoryType\":\"1\",\"proposeUnitId\":\"f1e34adb178a4141b1c9799d112e1c17\",\"proposeUserName\":\"\",\"declarationName\":\"田禾\",\"declarationProposeType\":1,\"proposeUnitName\":\"上海市教育委员会\",\"publicityType\":\"1\",\"nomineeUnitName\":\"华东理工大学\",\"declarationLevel\":\"\",\"categoryId\":\"88f1678c136b480ebe811b82f111924f\"}","__typename":"PublicityVo"},{"id":"5d50ca775c6ea9000174e7fc","publicityContentStr":"{\"contentId\":\"e0b6bdd7cce24b78bb7a0c30cbfbc013\",\"declarationNo\":\"20192011010380\",\"categoryName\":\"科技功臣奖\",\"categoryType\":\"1\",\"proposeUnitId\":\"d469c7c1392a41acb49d62ffa262b1a3\",\"proposeUserName\":\"\",\"declarationName\":\"张激\",\"declarationProposeType\":1,\"proposeUnitName\":\"上海市嘉定区科学技术委员会\",\"publicityType\":\"1\",\"nomineeUnitName\":\"中国电子科技集团公司第三十二研究所\",\"declarationLevel\":\"\",\"categoryId\":\"88f1678c136b480ebe811b82f111924f\"}","__typename":"PublicityVo"},{"id":"5d50ca775c6ea9000174e7fd","publicityContentStr":"{\"contentId\":\"90d0123d0284427c9a901c3911e0d3ce\",\"declarationNo\":\"20196024010135\",\"categoryName\":\"科技功臣奖\",\"categoryType\":\"1\",\"proposeUnitId\":\"d7c6e20a91ff4253b707a6dca15b40f1\",\"proposeUserName\":\"\",\"declarationName\":\"陈桂林\",\"declarationProposeType\":1,\"proposeUnitName\":\"中国科学院上海分院\",\"publicityType\":\"1\",\"nomineeUnitName\":\"中国科学院上海技术物理研究所\",\"declarationLevel\":\"\",\"categoryId\":\"88f1678c136b480ebe811b82f111924f\"}","__typename":"PublicityVo"},{"id":"5d50ca775c6ea9000174e7fe","publicityContentStr":"{\"contentId\":\"924692cdf53b47ae9ad1b75db2ceb4b5\",\"declarationNo\":\"20191005070006\",\"categoryName\":\"青年科技杰出贡献奖\",\"categoryType\":\"1\",\"proposeUnitId\":\"f1e34adb178a4141b1c9799d112e1c17\",\"proposeUserName\":\"\",\"declarationName\":\"沈红斌\",\"declarationProposeType\":1,\"proposeUnitName\":\"上海市教育委员会\",\"publicityType\":\"1\",\"nomineeUnitName\":\"上海交通大学\",\"declarationLevel\":\"\",\"categoryId\":\"6a4328221b7f46a39ca968e33014eb9e\"}","__typename":"PublicityVo"},{"id":"5d50ca775c6ea9000174e7ff","publicityContentStr":"{\"contentId\":\"875b815fb4c74868b70a64ecae847146\",\"declarationNo\":\"20191005070338\",\"categoryName\":\"青年科技杰出贡献奖\",\"categoryType\":\"1\",\"proposeUnitId\":\"f1e34adb178a4141b1c9799d112e1c17\",\"proposeUserName\":\"\",\"declarationName\":\"赵黎明\",\"declarationProposeType\":1,\"proposeUnitName\":\"上海市教育委员会\",\"publicityType\":\"1\",\"nomineeUnitName\":\"华东理工大学\",\"declarationLevel\":\"\",\"categoryId\":\"6a4328221b7f46a39ca968e33014eb9e\"}","__typename":"PublicityVo"}],"__typename":"PublicityPagePayload"}}}说明这次的请求是正确的,接下来就是提取我们想要的信息,以及构建循环获取所有页面表格内容并保存到txt中。
表格中有如下几项信息需要提取:
对应着返回json数据里的字段
'declarationNo' , 'declarationName', 'categoryName', 'declarationLevel', 'achieveUserName', 'achieveUnitName', 'proposeUnitName'构造写入txt代码
# 创建一个空文档f = open('data.txt', 'w', newline='', encoding="utf-8")csv_write = csv.writer(f)keys = ['提名编号', '被提名人/项目名称', '项目类型', '提名等级', '第一完成人', '第一完成单位', '提名人/单位']# 写入表头名csv_write.writerow(keys)# 提取相应字段数据input_data = [str(js_item['declarationNo']), js_item['declarationName'], js_item['categoryName'], js_item['declarationLevel'], js_item['achieveUserName'] if ('achieveUserName' in js_item) else '', js_item['achieveUnitName'] if ('achieveUnitName' in js_item) else '', js_item['proposeUnitName']]# 写入空文档中csv_write.writerow(input_data)# 关闭保存创建的文档f.close()用Excel打开data.txt文档后,网页内容就会显示如下:

最后就可以加个循环把所有页面内容保存下来了,爬取部分截图如下:
.........

至此,大功告成!!
顺便学了新知识
通过传入json数据进行网页爬取
写入数据到csv文件中
相应代码如下:
# 通过传入json数据请求网页res = requests.post(url, data=json.dumps(data), headers=headers).json()# 写入数据到csv文件f = open('data.txt', 'w', newline='', encoding="utf-8")csv_write = csv.writer(f)keys = ['提名编号', '被提名人/项目名称', '项目类型', '提名等级', '第一完成人', '第一完成单位', '提名人/单位']csv_write.writerow(keys)csv_write.writerow(input_data)f.close()















 1712
1712











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









