






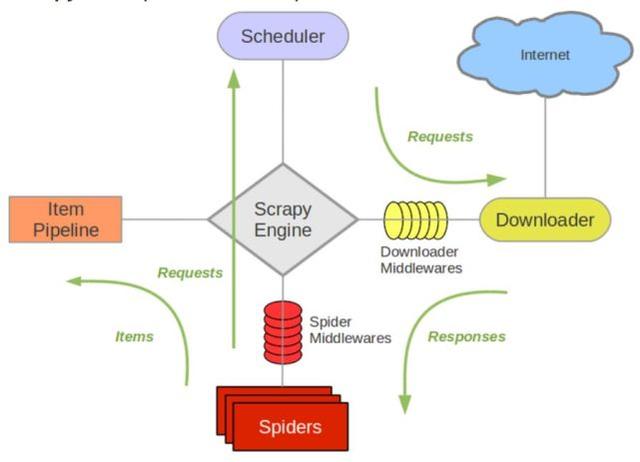
本篇文章是关于 Scrapy 爬虫的创建
01
Scrapy的环境搭建
想来能学习 Scrapy 肯定 Python 环境是安装好的,所以就可以直接使用命令
pip install scrapy
这样就可以直接安装 Scrapy 了。太慢的话建议去更换 pip 源,自行百度。安装完成之后输入 scrapy 出现下面的信息则就是安装成功
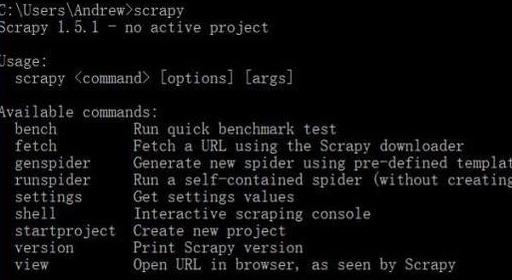
02
创建一个Scrapy项目
进入你想生成项目的文件目录,使用命令创建一个 Scrapy 项目
scrapy startproject newspider

出现这个信息意味着你的项目已经创建成功。newspider 是项目的名字,可以自己命名。
查看文件夹, 会发现 newspider 这个文件夹,这就是你创建的 Scrapy 爬虫项目了。
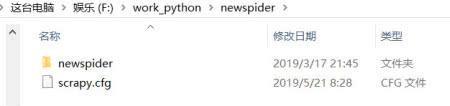
Scrapy 爬虫还有好几个不同的类型可以创建,这个后续再说。创建到这里基本就结束,可以直接使用 IDE 工具打开,建议使用 PyCharm 直接打开。
03
项目文件介绍

这是文件目录,下面给大家介绍一下每个文件都是干嘛的。
newspider 文件夹内,有一个 scrapy.cfg 配置文件和 newspider 的文件夹
第一层[一级 newspider目录]:
-scrapy.cfg: 配置文件,不需要修改
-newspider: 文件夹:第二层解释
第二层[二级newspider目录]:
init.py: 特定文件,指明二级newspider目录为一个python模块
item.py:定义需要的item类
pipeline.py:管道文件,传入item.py中的item类,清理数据,保存或入库
settings.py:设置文件,例如设置用户代理和初始下载延迟
spiders目录:第三层解释
第三层【spiders目录】
init.py : 特定文件,指明二级newspider目录为一个python模块
这里是放自定义爬虫的py文件,负责从html中获得数据,传入上一层管道文件中进行数据清理
项目文件目录介绍完毕。
04
简单的爬虫实例
这里我以上次的抓取智联的代码为例,就直接上代码了,按照上面的步骤走下来,运行这个爬虫是完全没问题的。在 spiders 文件夹下新建 zhilianspider.py 文件,名字自己定。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2019/4/29 16:11
# @Author : zhao.jia
# @Site :
# @File : zhilianspider.py
# @Software: PyCharm
import scrapy
import json
from spider_work.items import ZhaopingItem
import re
class ZhaopinSpider(scrapy.Spider):
# 爬虫的名字,以此来启动爬虫
name = 'job_spider'
# 起始URL,
baseUrl = 'https://fe-api.zhaopin.com/c/i/sou?start=&pageSize=90&cityId=489&kw=&kt=3'
offset = 0 # 偏移量
def start_requests(self):
# 打开关键词的json文件
with open('keywords.json', 'r', encoding='utf8') as f:
keywords_list = json.load(f)
start_urls = []
for item in keywords_list:
for key, value in item.items():
for job_key in value:
print(job_key)
start_urls.append(self.baseUrl.format(str(self.offset), job_key))
if start_urls is not None:
for url in start_urls:
print("start_url:















 3627
3627











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









