





6. 使用LSTM递归神经网络进行时间序列预测
任务: 建立循环网络, 对时间序列的数据进行学习预测
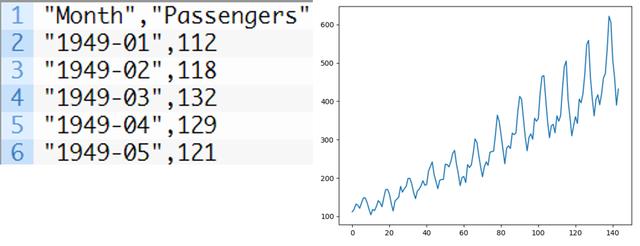
数据集: 1949年1月至1960年12月,即12年,144次数据记录, 每个月飞机的乘客数量。
数据形式如下:
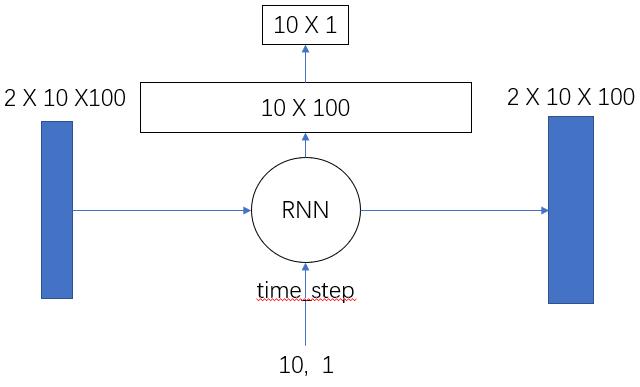
一.LSTM回归网络
## 2019.11.1# time_step = 1 lstm-cell个数# n_inputs = 1 输入大小, 也就是look-back# n_outputs = 1 输出大小, 全连接输出# iter_epoch = 100 训练次数# batch_size = 10 每次训练的大小import numpy as npfrom sklearn.preprocessing import MinMaxScalerimport tensorflow as tfimport matplotlib.pyplot as pltimport pandas as pd## 读取csv数据文件def readCSV(filePath): dataset = pd.read_csv(filePath, usecols=[1]) dataset = dataset.values.astype(np.float) plt.plot(dataset) plt.show() return dataset## 将数据转换为x, y## 这个函数将创造一个数据, x为时间t时刻的数据, y为时间t+1时刻的数据## look_back 指代 我们需要过去多少个时间点的数据作为输入 预测下一个点的数据def create_dataset(data, look_back=1): dataX, dataY = [], [] for i in range(len(data) - look_back - 1): dataX.append(data[i:(i+look_back), 0]) dataY.append(data[i+look_back, 0]) return np.array(dataX), np.array(dataY).reshape([-1, 1])def mean_square_error(pred, y): return np.power(np.sum(np.power(pred - y, 2)) / pred.shape[0], 0.5)def lstm_net(X, y, batch_size, units=100, learning_rate=0.002): lstm_cell = tf.contrib.rnn.BasicLSTMCell(units, forget_bias=1.0, state_is_tuple=True) init_state = lstm_cell.zero_state(batch_size, dtype=tf.float32) # batch_size, units outputs, final_state = tf.nn.dynamic_rnn(lstm_cell, X, initial_state=init_state, time_major=False) result = tf.layers.dense(outputs, units=1, activation=None) loss = tf.reduce_mean(tf.square(y-result)) train_op = tf.train.AdamOptimizer(learning_rate).minimize(loss) return result, loss, train_opdef train(data): ## 划分训练数据集和测试数据集 tst = 100 x_train, x_test = data[0:tst, :], data[tst:, :] ## 产生数据 trainX, trainY = create_dataset(x_train) testX, testY = create_dataset(x_test) print(trainX.shape) print(trainY.shape) ## reshape input to [samples, time step, features] trainX = np.reshape(trainX, newshape=[trainX.shape[0], 1, trainX.shape[1]]) testX = np.reshape(testX, newshape=[testX.shape[0], 1, testX.shape[1]]) time_step = 1 n_inputs = 1 n_outputs = 1 iter_epoch = 100 batch_size = 10 x = tf.placeholder(tf.float32, shape=[None, time_step, n_inputs]) y = tf.placeholder(tf.float32, shape=[None, n_outputs]) result, loss, train_op = lstm_net(x, y, batch_size) with tf.Session() as sess: sess.run(tf.global_variables_initializer()) re_loss = [] for i in range(iter_epoch): temp = 0 for j in range(int(trainX.shape[0] / batch_size)): tx = trainX[(j * batch_size):((j + 1) * batch_size), :, :] ty = trainY[(j * batch_size):((j + 1) * batch_size), :] ls, _ = sess.run([loss, train_op], feed_dict={x: tx, y: ty}) temp += ls print(temp / trainX.shape[0]) re_loss.append(temp / trainX.shape[0]) plt.plot(range(iter_epoch), re_loss, c='red') plt.show() re_train = [] for j in range(int(trainX.shape[0] / batch_size)): tx = trainX[(j * batch_size):((j + 1) * batch_size), :, :] ty = trainY[(j * batch_size):((j + 1) * batch_size), :] pred = sess.run([result], feed_dict={x: tx, y: ty}) re_train.append(pred) re_test = [] for j in range(int(testX.shape[0] / batch_size)): tx = testX[(j * batch_size):((j + 1) * batch_size), :, :] ty = testY[(j * batch_size):((j + 1) * batch_size), :] pred = sess.run([result], feed_dict={x: tx, y: ty}) re_test.append(pred) re_train = np.array(re_train).reshape([-1, 1]) re_test = np.array(re_test).reshape([-1, 1]) re_train = scaler.inverse_transform(re_train) re_test = scaler.inverse_transform(re_test) data = scaler.inverse_transform(data) ## plot 训练集预测 plt.plot(range(re_train.shape[0]), re_train, label='Train Predict') ## plot 测试集预测 plt.plot(range(tst, tst + re_test.shape[0]), re_test, label='Test Predict') ## plot 实际数据 plt.plot(range(data.shape[0]), data, label='Data') plt.show() print('Train Accuary {:.3f}'.format(np.sqrt(mean_square_error(re_train, trainY[0:re_train.shape[0]])))) print('Test Accuary {:.3f}'.format(np.sqrt(mean_square_error(re_test, testY[0:re_test.shape[0]])))) v1 = np.array(re_train).reshape([-1, 1]) v2 = trainY[0: v1.shape[0], :] print(np.hstack([v1, v2]))if __name__ == '__main__': pathFile = 'data/airline-passengers.csv' ## 加载数据 data = readCSV(pathFile) ## 正则化数据 数据收缩到[0, 1] scaler = MinMaxScaler(feature_range=(0, 1)) data = scaler.fit_transform(data) train(data)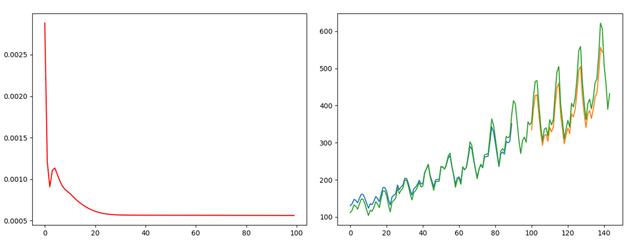
2.LSTM for Regression Using the Window Method
将look_back = 3, 即是把窗口size设置为3,对于每个lstm-cell, 我们输入n_inputs = look_back, 我们使用(t-look_back, t-1)间的数据进行预测t时刻
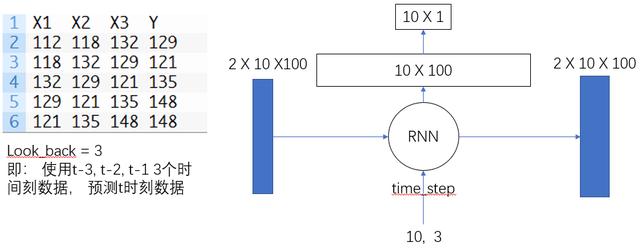
## 2019.11.1# time_step = 1 lstm-cell个数# n_inputs = 3 输入大小, 也就是look-back# n_outputs = 1 输出大小, 全连接输出# iter_epoch = 100 训练次数# batch_size = 10 每次训练的大小import numpy as npfrom sklearn.preprocessing import MinMaxScalerimport tensorflow as tfimport matplotlib.pyplot as pltimport pandas as pd## 读取csv数据文件def readCSV(filePath): dataset = pd.read_csv(filePath, usecols=[1]) dataset = dataset.values.astype(np.float) plt.plot(dataset) plt.show() return dataset## 将数据转换为x, y## 这个函数将创造一个数据, x为时间t时刻的数据, y为时间t+1时刻的数据## look_back 指代 我们需要过去多少个时间点的数据作为输入 预测下一个点的数据def create_dataset(data, look_back=1): dataX, dataY = [], [] for i in range(len(data) - look_back - 1): dataX.append(data[i:(i+look_back), 0]) dataY.append(data[i+look_back, 0]) return np.array(dataX), np.array(dataY).reshape([-1, 1])def mean_square_error(pred, y): return np.power(np.sum(np.power(pred - y, 2)) / pred.shape[0], 0.5)def lstm_net(X, y, batch_size, units=100, learning_rate=0.002): lstm_cell = tf.contrib.rnn.BasicLSTMCell(units, forget_bias=1.0, state_is_tuple=True) init_state = lstm_cell.zero_state(batch_size, dtype=tf.float32) # batch_size, units outputs, final_state = tf.nn.dynamic_rnn(lstm_cell, X, initial_state=init_state, time_major=False) result = tf.layers.dense(outputs, units=1, activation=None) loss = tf.reduce_mean(tf.square(y-result)) train_op = tf.train.AdamOptimizer(learning_rate).minimize(loss) return result, loss, train_opdef train(data): ## 划分训练数据集和测试数据集 tst = 100 x_train, x_test = data[0:tst, :], data[tst:, :] ## 产生数据 trainX, trainY = create_dataset(x_train, 3) testX, testY = create_dataset(x_test, 3) print(trainX.shape) print(trainY.shape) ## reshape input to [samples, time step, features] trainX = np.reshape(trainX, newshape=[trainX.shape[0], 1, trainX.shape[1]]) testX = np.reshape(testX, newshape=[testX.shape[0], 1, testX.shape[1]]) time_step = 1 n_inputs = 3 n_outputs = 1 iter_epoch = 100 batch_size = 10 x = tf.placeholder(tf.float32, shape=[None, time_step, n_inputs]) y = tf.placeholder(tf.float32, shape=[None, n_outputs]) result, loss, train_op = lstm_net(x, y, batch_size) with tf.Session() as sess: sess.run(tf.global_variables_initializer()) re_loss = [] for i in range(iter_epoch): temp = 0 for j in range(int(trainX.shape[0] / batch_size)): tx = trainX[(j * batch_size):((j + 1) * batch_size), :, :] ty = trainY[(j * batch_size):((j + 1) * batch_size), :] ls, _ = sess.run([loss, train_op], feed_dict={x: tx, y: ty}) temp += ls print(temp / trainX.shape[0]) re_loss.append(temp / trainX.shape[0]) plt.plot(range(iter_epoch), re_loss, c='red') plt.show() re_train = [] for j in range(int(trainX.shape[0] / batch_size)): tx = trainX[(j * batch_size):((j + 1) * batch_size), :, :] ty = trainY[(j * batch_size):((j + 1) * batch_size), :] pred = sess.run([result], feed_dict={x: tx, y: ty}) re_train.append(pred) re_test = [] for j in range(int(testX.shape[0] / batch_size)): tx = testX[(j * batch_size):((j + 1) * batch_size), :, :] ty = testY[(j * batch_size):((j + 1) * batch_size), :] pred = sess.run([result], feed_dict={x: tx, y: ty}) re_test.append(pred) re_train = np.array(re_train).reshape([-1, 1]) re_test = np.array(re_test).reshape([-1, 1]) re_train = scaler.inverse_transform(re_train) re_test = scaler.inverse_transform(re_test) data = scaler.inverse_transform(data) ## plot 训练集预测 plt.plot(range(re_train.shape[0]), re_train, label='Train Predict') ## plot 测试集预测 plt.plot(range(tst, tst + re_test.shape[0]), re_test, label='Test Predict') ## plot 实际数据 plt.plot(range(data.shape[0]), data, label='Data') plt.show() print('Train Accuary {:.3f}'.format(np.sqrt(mean_square_error(re_train, trainY[0:re_train.shape[0]])))) print('Test Accuary {:.3f}'.format(np.sqrt(mean_square_error(re_test, testY[0:re_test.shape[0]])))) v1 = np.array(re_train).reshape([-1, 1]) v2 = trainY[0: v1.shape[0], :] print(np.hstack([v1, v2]))if __name__ == '__main__': pathFile = 'data/airline-passengers.csv' ## 加载数据 data = readCSV(pathFile) ## 正则化数据 数据收缩到[0, 1] scaler = MinMaxScaler(feature_range=(0, 1)) data = scaler.fit_transform(data) train(data)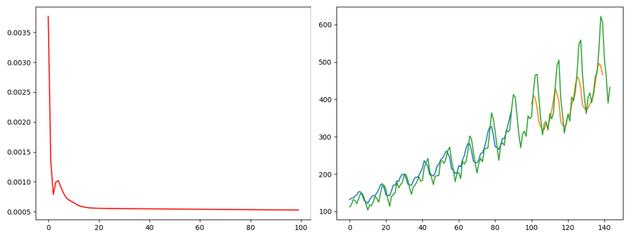
3.LSTM for Regression with Time Steps
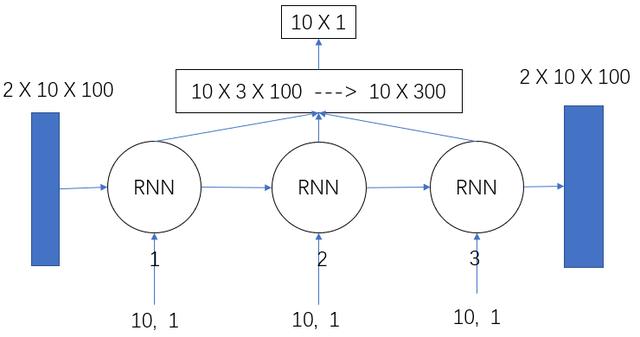
## 2019.11.1# time_step = 3 lstm-cell个数# n_inputs = 1 输入大小, 也就是look-back# n_outputs = 1 输出大小, 全连接输出# iter_epoch = 100 训练次数# batch_size = 10 每次训练的大小import numpy as npfrom sklearn.preprocessing import MinMaxScalerimport tensorflow as tfimport matplotlib.pyplot as pltimport pandas as pd## 读取csv数据文件def readCSV(filePath): dataset = pd.read_csv(filePath, usecols=[1]) dataset = dataset.values.astype(np.float) plt.plot(dataset) plt.show() return dataset## 将数据转换为x, y## 这个函数将创造一个数据, x为时间t时刻的数据, y为时间t+1时刻的数据## look_back 指代 我们需要过去多少个时间点的数据作为输入 预测下一个点的数据def create_dataset(data, look_back=1): dataX, dataY = [], [] for i in range(len(data) - look_back - 1): dataX.append(data[i:(i+look_back), 0]) dataY.append(data[i+look_back, 0]) return np.array(dataX), np.array(dataY).reshape([-1, 1])def mean_square_error(pred, y): return np.power(np.sum(np.power(pred - y, 2)) / pred.shape[0], 0.5)def lstm_net(X, y, batch_size, units=100, learning_rate=0.002): lstm_cell = tf.contrib.rnn.BasicLSTMCell(units, forget_bias=1.0, state_is_tuple=True) init_state = lstm_cell.zero_state(batch_size, dtype=tf.float32) # batch_size, units outputs, final_state = tf.nn.dynamic_rnn(lstm_cell, X, initial_state=init_state, time_major=False) outputs = tf.reshape(outputs, [-1, units * X.shape[1]]) result = tf.layers.dense(outputs, units=1, activation=None) loss = tf.reduce_mean(tf.square(y-result)) train_op = tf.train.AdamOptimizer(learning_rate).minimize(loss) return result, loss, train_opdef train(data): ## 划分训练数据集和测试数据集 tst = 100 x_train, x_test = data[0:tst, :], data[tst:, :] ## 产生数据 trainX, trainY = create_dataset(x_train, 3) testX, testY = create_dataset(x_test, 3) print(trainX.shape) print(trainY.shape) ## reshape input to [samples, time step, features] trainX = np.reshape(trainX, newshape=[trainX.shape[0], trainX.shape[1], 1]) testX = np.reshape(testX, newshape=[testX.shape[0], testX.shape[1], 1]) time_step = 3 n_inputs = 1 n_outputs = 1 iter_epoch = 100 batch_size = 10 x = tf.placeholder(tf.float32, shape=[None, time_step, n_inputs]) y = tf.placeholder(tf.float32, shape=[None, n_outputs]) result, loss, train_op = lstm_net(x, y, batch_size) with tf.Session() as sess: sess.run(tf.global_variables_initializer()) re_loss = [] for i in range(iter_epoch): temp = 0 for j in range(int(trainX.shape[0] / batch_size)): tx = trainX[(j * batch_size):((j + 1) * batch_size), :, :] ty = trainY[(j * batch_size):((j + 1) * batch_size), :] ls, _ = sess.run([loss, train_op], feed_dict={x: tx, y: ty}) temp += ls print(temp / trainX.shape[0]) re_loss.append(temp / trainX.shape[0]) plt.plot(range(iter_epoch), re_loss, c='red') plt.show() re_train = [] for j in range(int(trainX.shape[0] / batch_size)): tx = trainX[(j * batch_size):((j + 1) * batch_size), :, :] ty = trainY[(j * batch_size):((j + 1) * batch_size), :] pred = sess.run([result], feed_dict={x: tx, y: ty}) re_train.append(pred) re_test = [] for j in range(int(testX.shape[0] / batch_size)): tx = testX[(j * batch_size):((j + 1) * batch_size), :, :] ty = testY[(j * batch_size):((j + 1) * batch_size), :] pred = sess.run([result], feed_dict={x: tx, y: ty}) re_test.append(pred) re_train = np.array(re_train).reshape([-1, 1]) re_test = np.array(re_test).reshape([-1, 1]) re_train = scaler.inverse_transform(re_train) re_test = scaler.inverse_transform(re_test) data = scaler.inverse_transform(data) ## plot 训练集预测 plt.plot(range(re_train.shape[0]), re_train, label='Train Predict') ## plot 测试集预测 plt.plot(range(tst, tst + re_test.shape[0]), re_test, label='Test Predict') ## plot 实际数据 plt.plot(range(data.shape[0]), data, label='Data') plt.show() print('Train Accuary {:.3f}'.format(np.sqrt(mean_square_error(re_train, trainY[0:re_train.shape[0]])))) print('Test Accuary {:.3f}'.format(np.sqrt(mean_square_error(re_test, testY[0:re_test.shape[0]])))) v1 = np.array(re_train).reshape([-1, 1]) v2 = trainY[0: v1.shape[0], :] print(np.hstack([v1, v2]))if __name__ == '__main__': pathFile = 'data/airline-passengers.csv' ## 加载数据 data = readCSV(pathFile) ## 正则化数据 数据收缩到[0, 1] scaler = MinMaxScaler(feature_range=(0, 1)) data = scaler.fit_transform(data) train(data)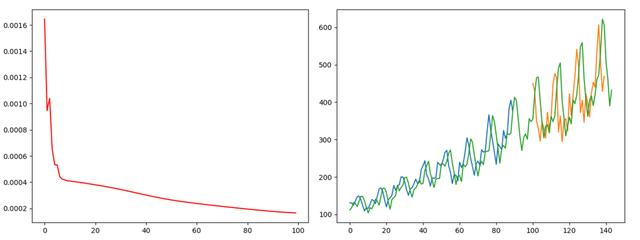
4.多层的LSTM网络
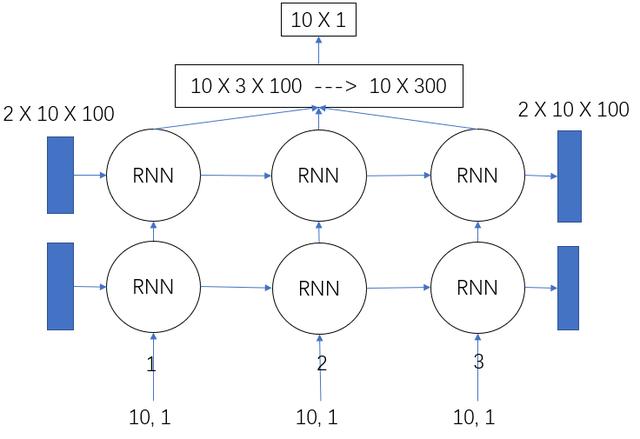
## 2019.11.1# time_step = 3 lstm-cell个数# n_inputs = 1 输入大小, 也就是look-back# n_outputs = 1 输出大小, 全连接输出# iter_epoch = 100 训练次数# batch_size = 10 每次训练的大小import numpy as npfrom sklearn.preprocessing import MinMaxScalerimport tensorflow as tfimport matplotlib.pyplot as pltimport pandas as pd## 读取csv数据文件def readCSV(filePath): dataset = pd.read_csv(filePath, usecols=[1]) dataset = dataset.values.astype(np.float) plt.plot(dataset) plt.show() return dataset## 将数据转换为x, y## 这个函数将创造一个数据, x为时间t时刻的数据, y为时间t+1时刻的数据## look_back 指代 我们需要过去多少个时间点的数据作为输入 预测下一个点的数据def create_dataset(data, look_back=1): dataX, dataY = [], [] for i in range(len(data) - look_back - 1): dataX.append(data[i:(i+look_back), 0]) dataY.append(data[i+look_back, 0]) return np.array(dataX), np.array(dataY).reshape([-1, 1])def mean_square_error(pred, y): return np.power(np.sum(np.power(pred - y, 2)) / pred.shape[0], 0.5)def lstm_net(X, y, batch_size, units=100, learning_rate=0.002): lstm_cells = [] for i in range(2): lstm_cells.append(tf.contrib.rnn.BasicLSTMCell(units, forget_bias=1.0, state_is_tuple=True)) multi_lstm = tf.contrib.rnn.MultiRNNCell(lstm_cells, state_is_tuple=True) init_state = multi_lstm.zero_state(batch_size, dtype=tf.float32) # batch_size, units outputs, final_state = tf.nn.dynamic_rnn(multi_lstm, X, initial_state=init_state, time_major=False) outputs = tf.reshape(outputs, [-1, units * X.shape[1]]) result = tf.layers.dense(outputs, units=1, activation=None) loss = tf.reduce_mean(tf.square(y - result)) train_op = tf.train.AdamOptimizer(learning_rate).minimize(loss) return result, loss, train_opdef train(data): ## 划分训练数据集和测试数据集 tst = 100 x_train, x_test = data[0:tst, :], data[tst:, :] ## 产生数据 trainX, trainY = create_dataset(x_train, 3) testX, testY = create_dataset(x_test, 3) print(trainX.shape) print(trainY.shape) ## reshape input to [samples, time step, features] trainX = np.reshape(trainX, newshape=[trainX.shape[0], trainX.shape[1], 1]) testX = np.reshape(testX, newshape=[testX.shape[0], testX.shape[1], 1]) time_step = 3 n_inputs = 1 n_outputs = 1 iter_epoch = 100 batch_size = 10 x = tf.placeholder(tf.float32, shape=[None, time_step, n_inputs]) y = tf.placeholder(tf.float32, shape=[None, n_outputs]) result, loss, train_op = lstm_net(x, y, batch_size) with tf.Session() as sess: sess.run(tf.global_variables_initializer()) re_loss = [] for i in range(iter_epoch): temp = 0 for j in range(int(trainX.shape[0] / batch_size)): tx = trainX[(j * batch_size):((j + 1) * batch_size), :, :] ty = trainY[(j * batch_size):((j + 1) * batch_size), :] ls, _ = sess.run([loss, train_op], feed_dict={x: tx, y: ty}) temp += ls print(temp / trainX.shape[0]) re_loss.append(temp / trainX.shape[0]) plt.plot(range(iter_epoch), re_loss, c='red') plt.show() re_train = [] for j in range(int(trainX.shape[0] / batch_size)): tx = trainX[(j * batch_size):((j + 1) * batch_size), :, :] ty = trainY[(j * batch_size):((j + 1) * batch_size), :] pred = sess.run([result], feed_dict={x: tx, y: ty}) re_train.append(pred) re_test = [] for j in range(int(testX.shape[0] / batch_size)): tx = testX[(j * batch_size):((j + 1) * batch_size), :, :] ty = testY[(j * batch_size):((j + 1) * batch_size), :] pred = sess.run([result], feed_dict={x: tx, y: ty}) re_test.append(pred) re_train = np.array(re_train).reshape([-1, 1]) re_test = np.array(re_test).reshape([-1, 1]) re_train = scaler.inverse_transform(re_train) re_test = scaler.inverse_transform(re_test) data = scaler.inverse_transform(data) ## plot 训练集预测 plt.plot(range(re_train.shape[0]), re_train, label='Train Predict') ## plot 测试集预测 plt.plot(range(tst, tst + re_test.shape[0]), re_test, label='Test Predict') ## plot 实际数据 plt.plot(range(data.shape[0]), data, label='Data') plt.show() print('Train Accuary {:.3f}'.format(np.sqrt(mean_square_error(re_train, trainY[0:re_train.shape[0]])))) print('Test Accuary {:.3f}'.format(np.sqrt(mean_square_error(re_test, testY[0:re_test.shape[0]])))) v1 = np.array(re_train).reshape([-1, 1]) v2 = trainY[0: v1.shape[0], :] print(np.hstack([v1, v2]))if __name__ == '__main__': pathFile = 'data/airline-passengers.csv' ## 加载数据 data = readCSV(pathFile) ## 正则化数据 数据收缩到[0, 1] scaler = MinMaxScaler(feature_range=(0, 1)) data = scaler.fit_transform(data) train(data)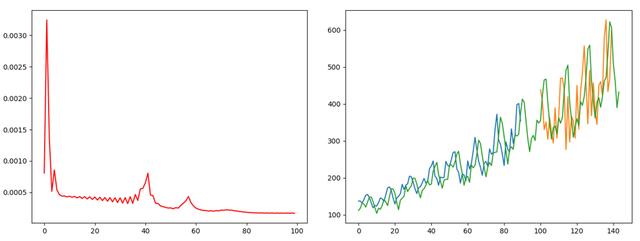















 1823
1823











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









